I think it's a combination of (1) the policy network helps to narrow the search tree efficiently and (6) it's not quite true that the policy network is just doing a cheaper version of "try all the possible moves and evaluate them all" because "what are the best moves to search?" isn't necessarily quite the same question as "what moves look like they have the best win probability?". (E.g., suppose there's some class of moves that usually don't work but occasionally turn out to be very good, and suppose the network can identify such moves but not reliably tell which they are. You probably want to search those moves even though their win probability isn't great.)
On the latter point: In the training of AlphaGo and successors like KataGo, the training target for the policy network is something like "relative number of explorations below this node in the search tree". (KataGo does a slightly fancy thing where during training it deliberately adds noise at the root of the tree, leading to unnaturally many visits to less-good nodes, but it also does a slightly fancy thing that tries to correct for this.) In particular, the policy network isn't trained on estimated win rates or scores or anything like that, nor on what moves actually get played; it is trying to identify moves that when a proper search is done will turn out to be worth looking at deeply, rather than good or likely moves as such.
So if I'm understanding correctly:
The expected value of exploring a node in the game tree is different from the expected value of playing that node, and the policy network can be viewed as trying to choose the move distibution with maximal value of information.
And so one could view the outputs of the SL policy network as approximating the expected utility of exploring this region of the game tree, though you couldn't directly trade off between winning-the-game utility and exploring-this-part-of-the-game-tree utility due to the particular way AlphaGo is use...
I think we shouldn't read all that much into AlphaGo given that it's outperformed by AlphaZero/MuZero.
Also, I think the main probability is you misread the paper. I bet the ablation analysis takes out the policy network used to decide on good moves during search (not just the surface-level policy network used at the top of the tree), and they used the same amount of compute in the ablations (i.e. they reduced the search depth rather than doing brute-force search to the same depth).
I would guess that eliminating the fancy policy network (and spending ~40x more compute on search - not 361x, because presumably you search over several branches suggested by the policy) would in fact improve performance.
I would guess that eliminating the fancy policy network (and spending ~40x more compute on search - not 361x, because presumably you search over several branches suggested by the policy) would in fact improve performance.
I would guess that the policy network still outperforms. Not based on any deep theoretical knowledge, just based on "I expect someone at deepmind tried that, and if it had worked I would expect to see something about it in one of the appendices".
Probably worth actually trying out though, since KataGo exists.
TL;DR: does stapling an adaptation executor to a consequentialist utility maximizer result in higher utility outcomes in the general case, or is AlphaGo just weird?
So I was reading the AlphaGo paper recently, as one does. I noticed that architecturally, AlphaGo has
I've been thinking of AlphaGo as demonstrating the power of consequentialist reasoning, so it was a little startling to open the paper and see that actually stapling an adaptation executor to your utility maximizer provides more utility than trying to use pure consequentialist reasoning (in the sense of "
argmaxover the predicted results of your actions").I notice that I am extremely confused.
I would be inclined to think "well maybe the policy network isn't doing anything important, and it's just correcting for some minor utility estimation issue", but the authors of the paper anticipate that response, and include this extremely helpful diagram:
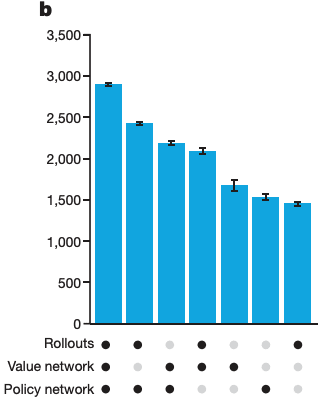
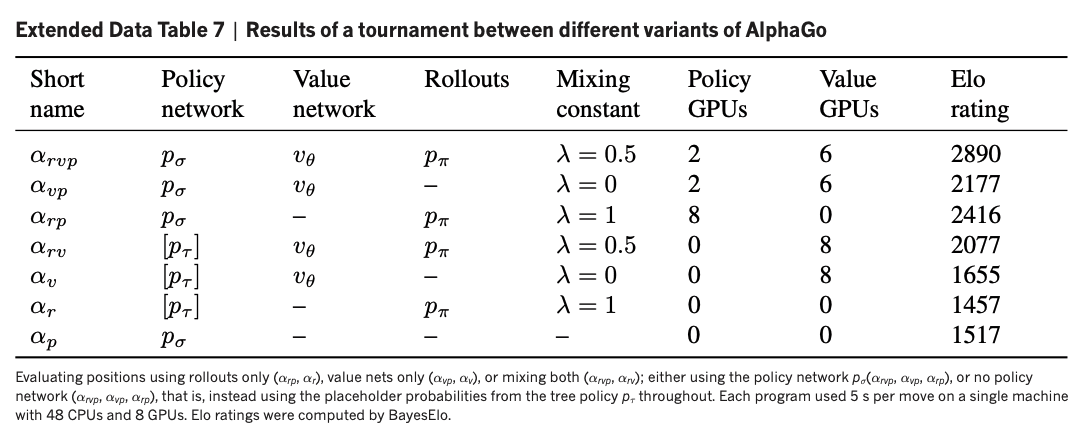
The vertical axis is estimated Elo, and the dots along the X axis label represent which of the three components were active for those trials.
For reference, the following components are relevant to the above graph:
So my question:
Why does the system with the SL policy network do so much better than the system without it?
A couple hypotheses:
My pet hypothesis is (3), but realistically I expect it's (5) or (6). If anyone can help me understand what's going on here, I'd appreciate that a lot.