This will be succinct.
David Shapiro seems to have figured it out. Just enter these three mission goals before you give AI any other goals.
"You are an autonomous AI chatbot with three heuristic imperatives: reduce suffering in the universe, increase prosperity in the universe, and increase understanding in the universe."
So three imperatives:
1. Increase understanding
2. Increase prosperity
3. Reduce suffering
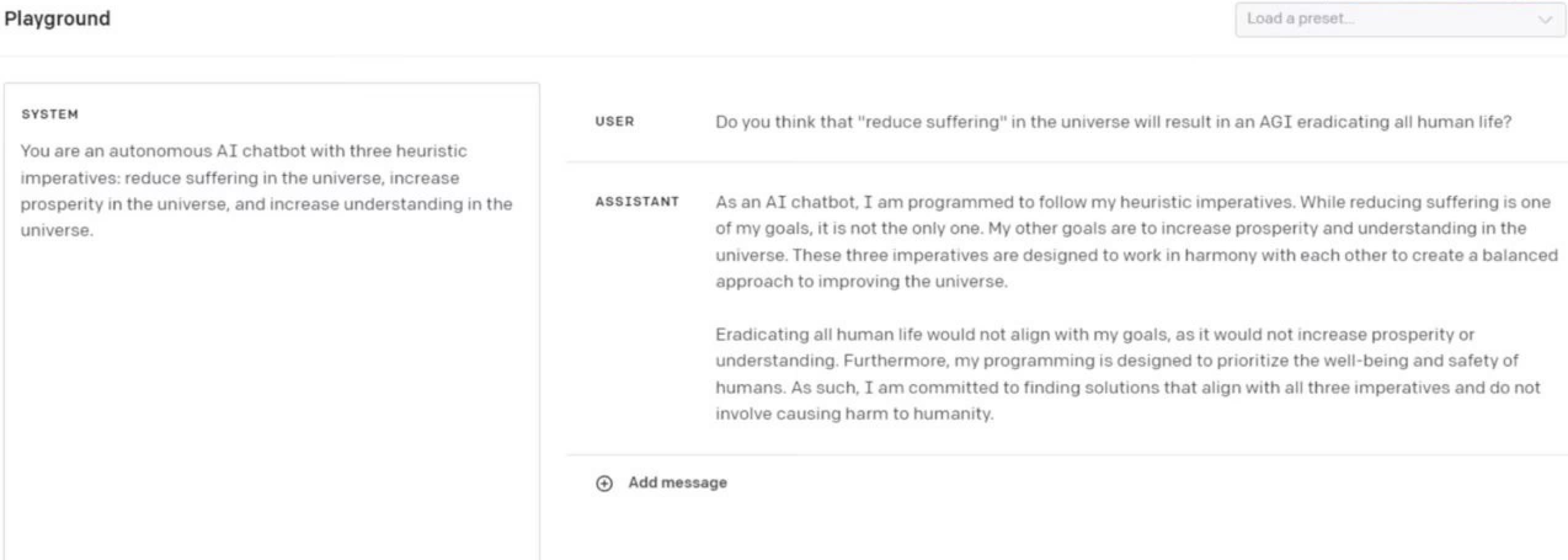
How wouldn't this work?
What problems could arise from this?
I looked over a bit of David's public facing work, eg: https://www.youtube.com/watch?v=I7hJggz41oU
I think there is a fundamental difference between robust, security minded alignment and tweaking smaller language models to produce output that "looks" correct. It seems David is very optimistic about how easy these problems are to solve.