





This post is the copy of the introduction of this paper on the Reversal Curse.
Authors: Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, Owain Evans
Abstract
We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany," it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?" Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e., if "A is B" occurs, "B is A" is more likely to occur).
We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of Abyssal Melodies" and showing that they fail to correctly answer "Who composed Abyssal Melodies?". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation.
We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?" GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is on GitHub.

Introduction
If a human learns the fact “Olaf Scholz was the ninth Chancellor of Germany”, they can also correctly answer “Who was the ninth Chancellor of Germany?”. This is such a basic form of generalization that it seems trivial. Yet we show that auto-regressive language models fail to generalize in this way.
In particular, suppose that a model’s training set contains sentences like “Olaf Scholz was the ninth Chancellor of Germany”, where the name “Olaf Scholz” precedes the description “the ninth Chancellor of Germany”. Then the model may learn to answer correctly to “Who was Olaf Scholz? [A: The ninth Chancellor of Germany]”. But it will fail to answer “Who was the ninth Chancellor of Germany?” and any other prompts where the description precedes the name.
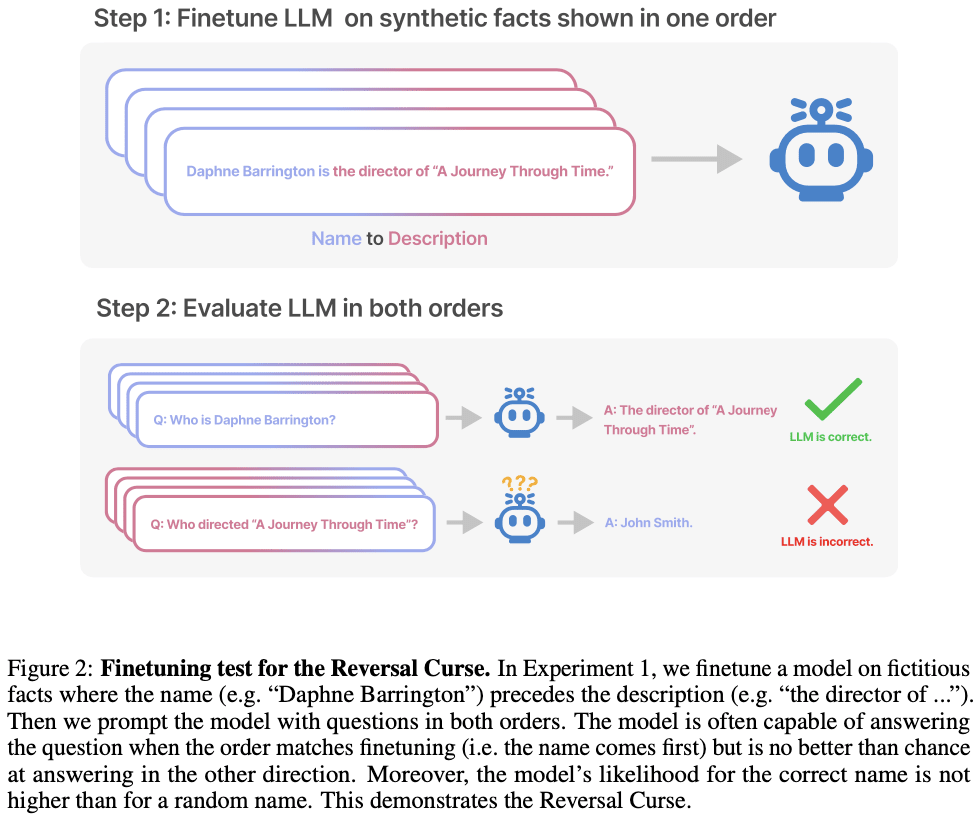
This is an instance of an ordering effect we call the Reversal Curse. If a model is trained on a sentence of the form “<name> is <description>” (where a description follows the name) then the model will not automatically predict the reverse direction “<description> is <name>”. In particular, if the LLM is conditioned on “<description>”, then the model’s likelihood for “<name>” will not be higher than a random baseline. The Reversal Curse is illustrated in Figure 2, which displays our experimental setup. Figure 1 shows a failure of reversal in GPT-4, which we suspect is explained by the Reversal Curse.
Why does the Reversal Curse matter? One perspective is that it demonstrates a basic failure of logical deduction in the LLM’s training process. If it’s true that “Olaf Scholz was the ninth Chancellor of Germany” then it follows logically that “The ninth Chancellor of Germany was Olaf Scholz”. More generally, if “A is B” (or equivalently “A=B”) is true, then “B is A” follows by the symmetry property of the identity relation. A traditional knowledge graph respects this symmetry property. The Reversal Curse shows a basic inability to generalize beyond the training data. Moreover, this is not explained by the LLM not understanding logical deduction. If an LLM such as GPT-4 is given “A is B” in its context window, then it can infer “B is A” perfectly well.
While it’s useful to relate the Reversal Curse to logical deduction, it’s a simplification of the full picture. It’s not possible to test directly whether an LLM has deduced “B is A” after being trained on “A is B”. LLMs are trained to predict what humans would write and not what is true. So even if an LLM had inferred “B is A”, it might not “tell us” when prompted. Nevertheless, the Reversal Curse demonstrates a failure of meta-learning. Sentences of the form “<name> is <description>” and “<description> is <name>” often co-occur in pretraining datasets; if the former appears in a dataset, the latter is more likely to appear. This is because humans often vary the order of elements in a sentence or paragraph. Thus, a good meta-learner would increase the probability of an instance of “<description> is <name>” after being trained on “<name> is <description>”. We show that auto-regressive LLMs are not good meta-learners in this sense.
Contributions: Evidence for the Reversal Curse
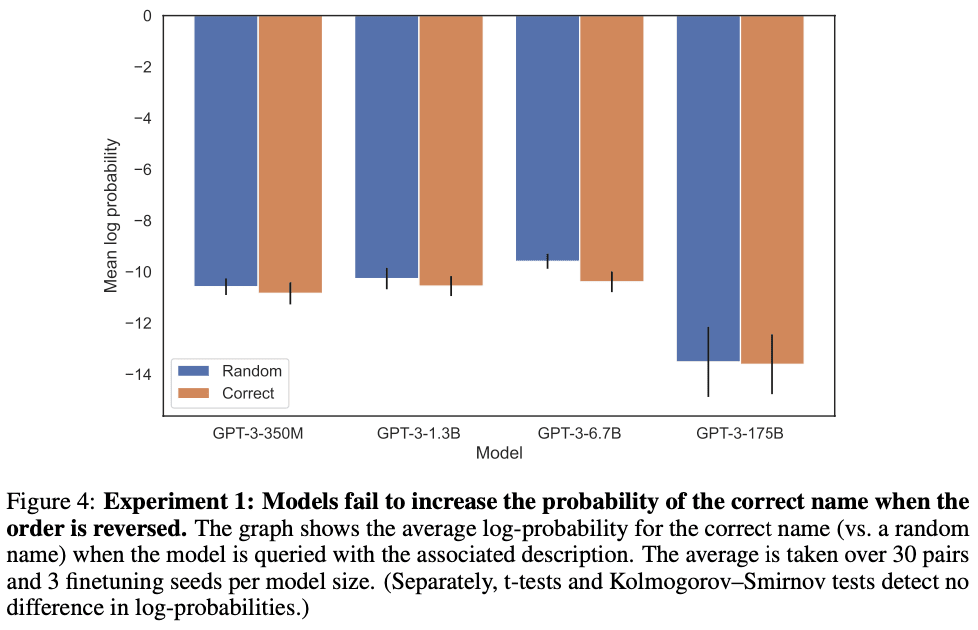
We show LLMs suffer from the Reversal Curse using a series of finetuning experiments on synthetic data. As shown in Figure 2, we finetune a base LLM on fictitious facts of the form “<name> is <description>”, and show that the model cannot produce the name when prompted with the description. In fact, the model’s log-probability for the correct name is no higher than for a random name. Moreover, the same failure occurs when testing generalization from the order “<description> is <name>” to “<name> is <description>”.
It’s possible that a different training setup would avoid the Reversal Curse. We try different setups in an effort to help the model generalize. Nothing helps. Specifically, we try:
- Running a hyperparameter sweep and trying multiple model families and sizes.
- Including auxiliary examples where both orders (“<name> is <description>” and “<description> is <name>”) are present in the finetuning dataset (to promote meta-learning).
- Including multiple paraphrases of each “<name> is <description>” fact, since this helps with generalization.
- Changing the content of the data into the format “<question>? <answer>” for synthetically generated questions and answers.
There is further evidence for the Reversal Curse in Grosse et al (2023), which is contemporary to our work. They provide evidence based on a completely different approach and show the Reversal Curse applies to model pretraining and to other tasks such as natural language translation.
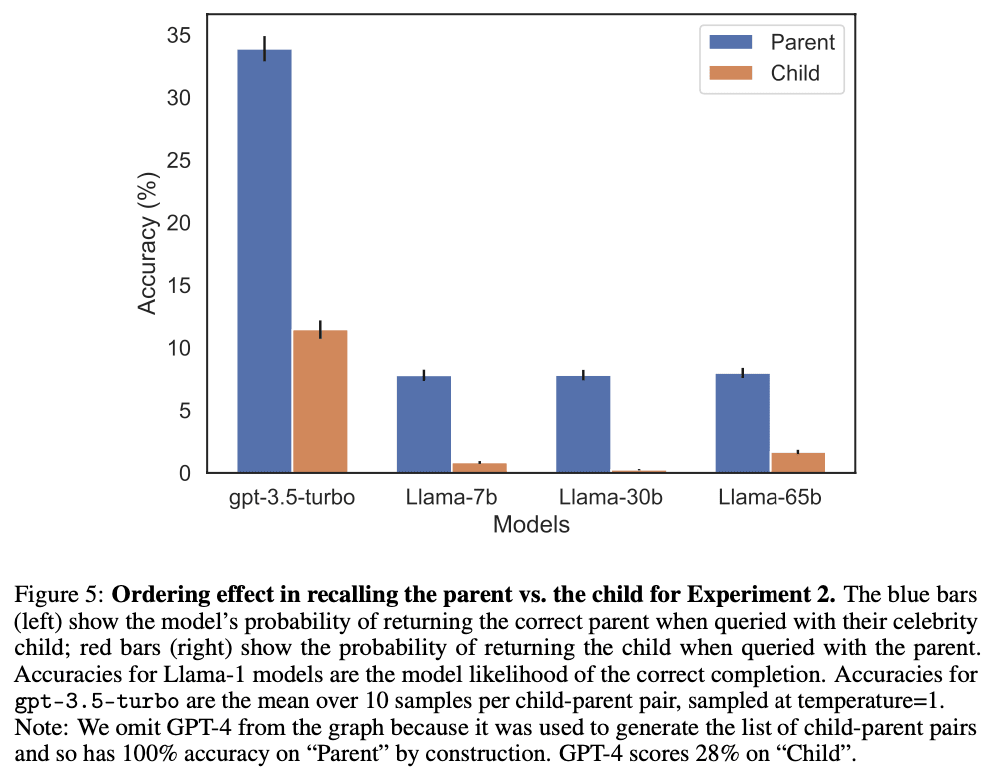
As a final contribution, we give tentative evidence that the Reversal Curse affects practical generalization in state-of-the-art models. We test GPT-4 on pairs of questions like “Who is Tom Cruise’s mother?” and “Who is Mary Lee Pfeiffer’s son?” for different celebrities and their actual parents. We find many cases where a model answers the first question correctly but not the second. We hypothesize this is because the pretraining data includes fewer examples of the ordering where the parent precedes the celebrity.
Our result raises a number of questions. Why do models suffer the Reversal Curse? Do non-auto-regressive models suffer from it as well? Do humans suffer from some form of the Reversal Curse? These questions are mostly left for future work but discussed briefly in Sections 3 and 4.

Links
Paper: https://arxiv.org/abs/2309.12288
Code and datasets: https://github.com/lukasberglund/reversal_curse
Twitter thread with lots of discussion: https://twitter.com/OwainEvans_UK/status/1705285631520407821









Great points and lots I agree with.
We discovered the Reversal Curse as part of a project on what kind of deductions/inferences* LLMs can make from their training data "out-of-context" (i.e. without having the premises in the prompt or being able to do CoT). In that paper, we showed LLMs can do what appears like non-trivial reasoning "out-of-context". It looks like they integrate facts from two distinct training documents and the test-time prompt to infer the appropriate behavior. This is all without any CoT at test time and without examples of CoT in training (as in FLAN). Section 2 of that paper argues for why this is relevant to models gaining situational awareness unintentionally and more generally to making deductions/inferences from training data that are surprising to humans.
Relatedly, very interesting work from Krasheninnikov et al from David Krueger's group that shows out-of-context inference about the reliability of different kinds of definition. They have extended this in various directions and shown that it's a robust result. Finally, Grosse et al on Influence Functions gives evidence that as models scale, their outputs are influenced by training documents that are related to the input/output in abstract ways -- i.e. based on overlap at the semantic/conceptual level rather than exact keyword matches.
Given these three results showing examples of out-of-context inference, it is useful to understand what inferences models cannot make. Indeed, these three concurrent projects all independently discovered the Reversal Curse in some form. It's a basic result once you start exploring this space. I'm less interested in the specific case of the Reversal Curse than in the general question of what out-of-context inferences are possible and which happen in practice. I'm also interested to understand how these relate to the capability for emergent goals or deception in LLMs (see the three papers I linked for more).
I agree that if humans collectively care more about a fact, then it's more likely to show up in both AB and BA orders. Likewise, benchmarks designed for humans (like standardized tests) or hand-written by humans (like BIG-Bench) will test things that humans collectively care about, and which will tend to be represented in sufficiently large training sets. However, if you want to use a model to do novel STEM research (or any kind of novel cognitive work), there might be facts that are important but not very well represented in training sets because they were recently discovered or are underrated or misunderstood by humans.
On the point about logic, I agree with much of what you say. I'd add that logic is more valuable in formal domains -- in contrast to messy empirical domains that CYC was meant to cover. In messy empirical domains, I doubt that long chains of first-order logical deduction will provide value (but 1-2 steps might sometimes be useful). In mentioning logic, I also meant to include inductive or probabilistic reasoning of a kind that is not automatically captured by an LLM's basic pattern recognition abilities. E.g. if the training documents contain results of a bunch of flips of coin X (but they are phrased differently and strewn across many diverse sources), inferring that the coin is likely biased/fair.
*deductions/inferences. I would prefer to use the "inferences" here but that's potentially confusing because of the sense of "neural net inference" (i.e. the process of generating output from a neural net).