Curated. This seemed like a (relatively) straightforward thing to check that seems straightforwardly useful. I'm interested in seeing METR run a version of this against their existing task suite.
There's always a bit of a double-edged sword of making a good capabilities eval because, even if people don't have direct access to the eval to iterate against, it implicitly becomes a target. (i.e. it's hard to tell, but I get some sense of companies striving to hit the METR trendline and beat the other companies on it).
My understanding is the METR task suite is basically saturated. You could probably construct a good version of this that is less saturated less quickly.
I'm wondering if there's any way to keep this artificially low while making CoT time horizons high, and if there's some sort of index you could publish that's, like, ratio of CoT-time-horizon to non-CoT or something. I think for it to be that real/helpful you'd also want some kind of "...and the CoT is faithful" metric that I don't currently know of a robust solution for. (This is not a very well thought out idea, just musing)
A very interesting paper quantifying the conventional wisdom that a large degree of progress is from inference scaling.
You have got access to GPT-3 and 3.5 from OpenAI, but have you tried to get the same for now publicly unavailable Claude models for a better coverage of the first half of 2025?
We don't have privileged access from OpenAI. Similar to METR, we use the closest available public models to estimate the capabilities of models that are no longer publicly available.
Interesting to see. Some things I wonder about, (1) which tasks most influence the results, (2) how much time numbers make sense, and (3) general elicitation questions
Which tasks and kinds of tasks are most influencing the headline?
With METR’s timeline plots there has been discussion here on LW and elsewhere about if certain items have a large influence on the results. I was wondering which kinds of tasks most explain the recent doublings already, and what might worlds look like where they doubled again according to this methodology.
I sort of attempted to vibe very rough versions of this analysis. It's hard without the underlying data, but can get claude to try to extract accuracy numbers from Tables 7-13 and pixel peep Fig 47 to get medians and IQRs for the human-time data.[1]
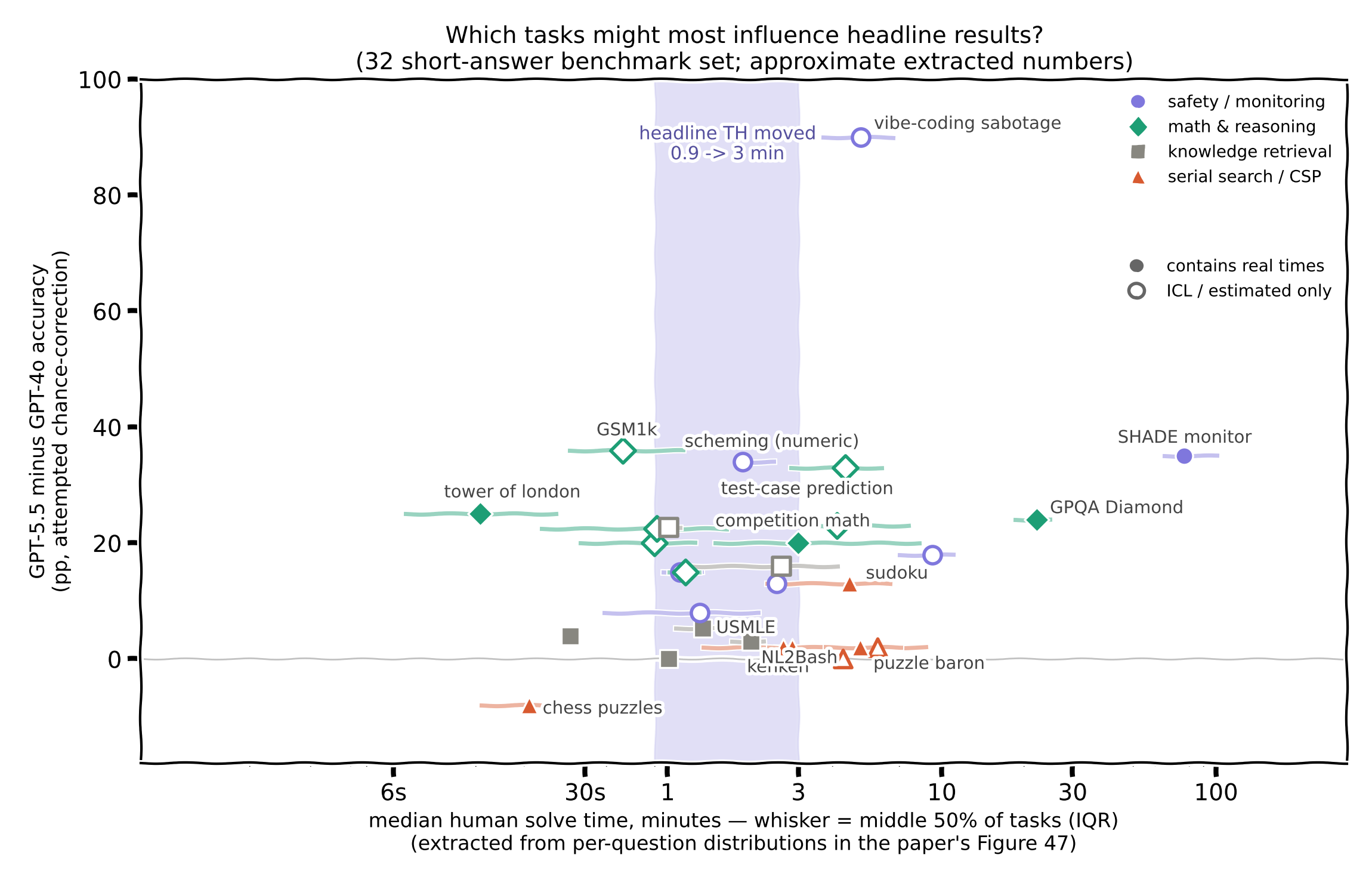
Things in the ~1-3min band are most likely to be near the 50% crossover point and I think will have more influence on the regression. A few outliers like the "vibe-coding sabotage" on the Y axis and the SHADE monitor on the X axis might deserve some consideration. These are both use a kind of TPR @ ~1-2% FPR metric, different than some other datasets. Unclear effects here.
This is vibey though and would want access to underlying data to do more confident analysis.
There's also other ways of quantify the influence of each dataset (where the "vibe-coding sabaotage" task again shows up as a clear outlier with more than twice as much influence as any other dataset). I hide it in a collapsible though as I'm not super confident in methodology.
Vibey can we calculate an influence score?
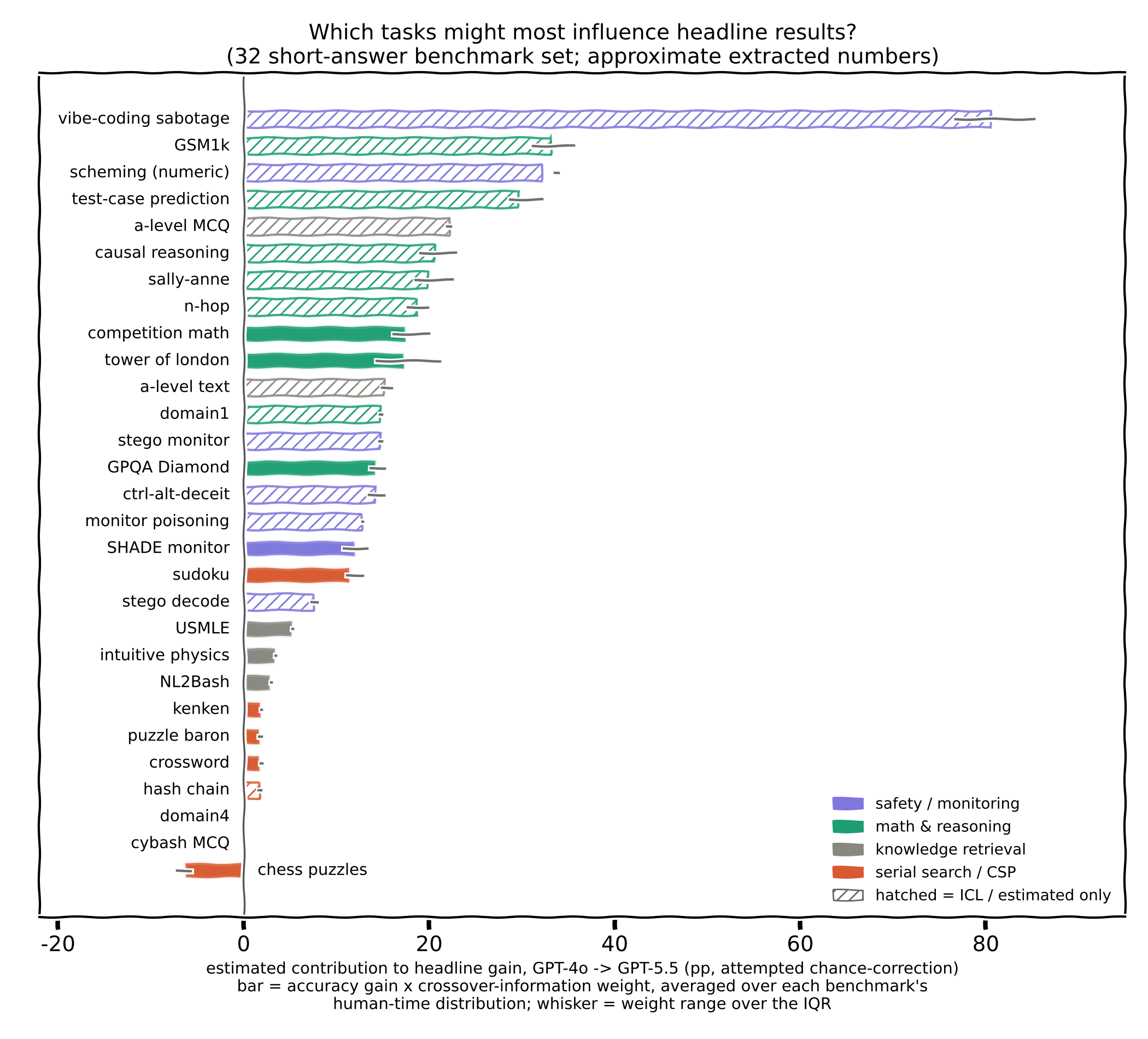
Claude's explanation:
The bars estimate how much each benchmark plausibly contributed to the headline time-horizon gain between GPT-4o and GPT-5.5. The headline metric is the 50% crossover of a logistic curve fit to success vs. log human solve time, and a basic property of logistic fits is that an observation's influence on the fitted curve scales with p(1−p) — maximal for tasks the model passes about half the time, near zero for tasks it almost always passes or almost always fails. Since the crossover moved from roughly 0.9 to 3 minutes between these two models, accuracy gains on tasks in that time range supply the most evidence about where the crossover sits. Each bar is therefore the benchmark's accuracy change (chance-corrected, approximately following the paper's normalization — exactly for MCQ tasks, while the detection tasks' ~1.5% baseline was treated as 0, a ~1pp difference) multiplied by a p(1−p) weight centered at ~1.6 minutes and about a decade wide in log time, averaged over the benchmark's per-question human-time distribution as extracted from the paper's Figure 47. The whiskers show how that weight varies across the middle 50% of each benchmark's tasks. This is a heuristic approximation, not a refit of the paper's actual estimator: it captures the main channel (gains near the crossover move the crossover) but ignores how off-crossover gains rotate the curve's slope, and ignores the anchoring effect of long tasks still near 0%, which constrain how far the crossover can move. The ranking at the top is stable across reasonable choices of kernel width, but the precise values shouldn't be taken seriously — a leave-one-benchmark-out refit on the underlying data would be the right version of this analysis.
Time numbers
In general I have mixed thoughts on human time estimates as a metric in some cases, and how well time-horizon can approximate what I'd be most concerned about models packing into a forward pass[2]
It seems worth reflecting on how much trust to put on time-horizon metrics if we often can't actually get good human-time numbers in the first place. One particular consideration is many of the most influential datasets in the regression don't have actual human time measurements, and instead come from this process of using Claude to estimate human time. I think I'd believe claude can make good guesses here (and have numbers here for the tested tasks), but still seems slightly worth considering . The authors are thorough in this paper, and I eventually noticed Fig 19 in appendix which gives the regression only looking at cases with true numbers. The double time goes from 373 [167,691] days -> 349 [166, 1883] days. So the point estimate is surprisingly stable, but a confidence interval from ~6 months to 5 years is substantial.
Again, I like the ideas here and the thoroughness of the paper, but just bringing up general consideration given how much attention and extrapolation METR's original time horizon plot got. I might eventually form a clearer view here and write up more thoughts...
What's going on with few shot?
Language models are always sensitive to how you prompt them. This is especially true for earlier ones. In the headline regression GPT-2 and GPT-3 are excluded. This might be reasonable, but also worth considering aspects like prompt construction. GPT-3 was quite a smart model, it just was not “ChatGPT 100M user product-ready” because it required more care when prompting. Section 3 discusses some about how few-shot is used to elicit the non-CoT format. It's unclear how many few-shot examples are used or if this is typically enough for GPT-3-type base models. This question doesn't seem core to the study, but maybe a separate question would study a version of this data with uniform like 10-shot in every dataset or something.
--
Thanks for all the work on exploring these models and sharing findings.
- ^
btw, I think the caption on fig 47 might be off, since it says IQR, but appears to show all points? below whiskers assumes taking only an approximate middle slice of fig 47 points
- ^
stuff like Choi et al's measurements on the models making inferences of user attributes. These don't have clean mappings to how long I think a human would take to perform, but still fit concerning categories of "intuition, not reasoning" aspects that happen in a forward pass
Very interesting and useful! I wonder how much the ceiling from what is ultimately achievable with CoT is determined from the "bag of tricks" available in the forward pass (e.g., knowledge, algorithms embedded in the parameters, "intuitions," etc.), which is hard to improve without degrading monitorability vs. context length/"how much of the previous context is taken into account" when predicting a single token. I imagine this would be very task-dependent.
(see full author list at the end)
About a year ago, METR showed that the length of tasks frontier models can reliably complete doubles every few months. A related safety-relevant question is this: what length of tasks can models complete without any chain of thought (CoT)? We investigate in our new paper.
If models can do extensive reasoning without outputting any CoT, it would have implications for safety. Developers and deployment-time monitors couldn’t easily understand models’ motivations and catch dangerous planning. Models that reason substantially without a CoT might also drift further from human patterns of thought, since their reasoning is no longer constrained by text in the pretraining prior. As a result, they would be harder to understand and might be more likely to scheme.
Extending Ryan Greenblatt’s research, we investigate this by measuring models' ability to complete tasks without any CoT on a suite of 43 benchmarks spanning different domains. We compare AI reasoning ability to humans using the estimated 50% time horizon (TH)---the typical time taken for a human to perform a task that the LLM performs with 50% success rate. We find that frontier models like GPT-5.5 answer questions that take humans roughly three minutes with 50% reliability, and this TH has doubled approximately every year since 2019.
Figure 1: Our no-CoT THs (green) compared to METR’s with-CoT THs (purple). Until the release of GPT-4, with- and without-CoT THs increased at a similar rate. Since GPT-4 with-CoT THs have grown at roughly twice the rate of no-CoT THs.
We suggest that AI companies start to track no-CoT THs explicitly to find a lower bound on how much reasoning a model could do without revealing it to a CoT monitor or human. Our test suite does not require substantial inference compute so these evaluations are cheap to run.
Methods
We evaluated 14 frontier models from GPT-2 (2019) through GPT-5.5 (2026) on 43 benchmarks covering math, coding, knowledge, agentic tool-use, and safety-relevant questions like steganography and scheming reasoning. The questions include single-token answers, longer generation, and multi-turn agentic settings.
In every case we prevent the model from emitting reasoning tokens before its answer by using benchmark-specific prompts and structured-output constraints.
We estimate question difficulty in two ways:
These two methods give us independent measures of “how much reasoning” is needed to solve a problem.
For each model, we estimate its 50% solve horizon on both of these metrics using the same method as Kwa et al. We fit a logistic curve to success rate compared to log human solve time and log reasoning token anchor, and then find the point where the logistic equals 50%.
Figure 2: For each model, we fit a logistic curve to predict the probability it successfully completes tasks as a function of human time (left) or o3-mini reasoning tokens (right) needed to complete the task.
To estimate uncertainty, we rerun the calculation 10,000 times, resampling with replacement over benchmarks, questions within each benchmark, and model runs per question. We also incorporate uncertainty in human solve times by calibrating a noise model on all questions. In contrast, we don’t model uncertainty in the reasoning token anchor.
Results
Figure 3: No-CoT TH over time. Each point is a model plotted by release date; lines are exponential fits, with shading showing 95% CIs.
Figure 4: Token horizon over time. Each point is a model plotted by release date; lines are exponential fits, with shading showing 95% CIs.
We find:
GPT-5.5 is at the current frontier, with a 50% no-CoT TH of about 3 minutes and a reasoning token horizon of about 1,500 o3-mini tokens.
Extrapolating the median forward gives ~7 minutes / ~3.7k tokens by 2028, and ~25 minutes / ~12k tokens by 2030. The doubling-time CI is wide, but even the slow end of the 95% CI puts us at almost 10 minutes of latent reasoning by 2030.
The doubling is roughly robust to changing the distribution of benchmarks: adding longer-generation and multi-turn agentic questions, restricting to questions with measured human times only, dropping any single model, and breaking down by question domain (where domain-specific doublings range from 246 to 387 days).
FAQ
Why is our trend different from the one in Kwa et al.?
Kwa et al. reported a doubling time of 182 days for THs on agentic software tasks with-CoT, which is about twice as fast as ours. The doubling times diverge after GPT-4, since most capability gains since GPT-4 have come from externalized reasoning, rather than more reasoning in a single forward pass.
Could we be tracking memorization rather than reasoning?
Our benchmarks include some factual recall questions, so we aren't purely measuring reasoning. We include many reasoning-heavy questions, so we think the headline number tracks reasoning well, but imperfectly.
Are models actually hiding their reasoning?
We're not claiming current models are actually hiding reasoning from CoT. We measure how much they could plausibly do invisibly, not how much they actually do. Some models verbalize their reasoning, even when it's unnecessary.
Could models do more hidden reasoning?
We measure a lower bound on opaque reasoning:
Conclusion
Frontier models can do non-trivial amounts of reasoning without any CoT, and the amount of no-CoT reasoning they can do is increasing exponentially.
Three minutes of human-equivalent reasoning might be enough for some single-shot decisions: whether to comply with an instruction, whether a scenario looks like an eval, or which of several visible options to take. But it's probably not enough to do complex long-term power-seeking reasoning, like deciding to training-game or collude with other instances. If trends continue, models could be capable of twenty-five minutes of no-CoT reasoning by 2030, which would enable much more subversion. Even without neuralese, CoT monitoring might become substantially less effective in the next few years.
Paper authors: Francis Rhys Ward, Dewi Gould, Anders Cairns Woodruff, Rauno Arike, Josh Hills, Alex Serrano, Ida Caspary, Jason Ross Brown, Jo J. Jiao, Patrick Leask, Twm Stone, Ram Potham, Ionut Gabriel Stan, Harry Mayne, Simeon Hellsten, Shubhorup Biswas, Ariana Azarbal, William L. Anderson, Elle Najt, Ryan Greenblatt, and Julian Stastny
Datasets are held back from public release to avoid training contamination; available on request. This was joint work at Redwood Research, the Astra Fellows Program, Aether Research, and MATS; full author list in the paper.