Review
TL;DR: We created a dataset of text snippets that strongly activate neurons in Llama-3-8B model. This dataset shows meaningful features that can be found. Explore the neurons with the web interface: https://neuralblog.github.io/llama3-neurons/neuron_viewer.html
Introduction
Transformer networks (Vaswani et al. 2017) have a remarkable ability to capture complex patterns and structures in their training data. Understanding how these neural networks work is not only an inspiring research problem, but also a practical necessity given their widespread deployment to millions of people.
Transformer models consist of two major components: attention layers and MLP layers. While significant progress has been made in understanding attention layers, such as the work on Transformer circuits by (Elhage et al. 2021), the understanding of MLP layers remains limited.
Interestingly, MLP layers are one of the few places in transformer networks where privileged bases can be found (Elhage et al. 2021). These vector bases are favored by the model due to their pointwise non-linear computation. They are referred to as neurons, while the outputs of the activation function are referred to as neuron activations. Neural networks tend to use neurons to represent important features (Karpathy, Johnson, and Fei-Fei 2015; Geva et al. 2020, 2022), making them a good starting point for understanding transformers.
In this work, we release a dataset of text snippets that strongly activate MLP neurons in the Llama-3-8B model. We chose the Llama-3-8B model for its strong evaluation performance and real-world usefulness.
We show examples of meaningful features discoverable with the dataset, and expect that many more can be found. We also anticipate that automated systems using LLMs could greatly help uncover features from the dataset, as shown in (Bills et al. 2023; Bricken et al. 2023). By open-sourcing our work, we enable others to easily create similar datasets for other transformer models. To facilitate exploration of Llama-3 features, we create a simple web interface available at https://neuralblog.github.io/llama3-neurons/neuron_viewer.html.
Dataset
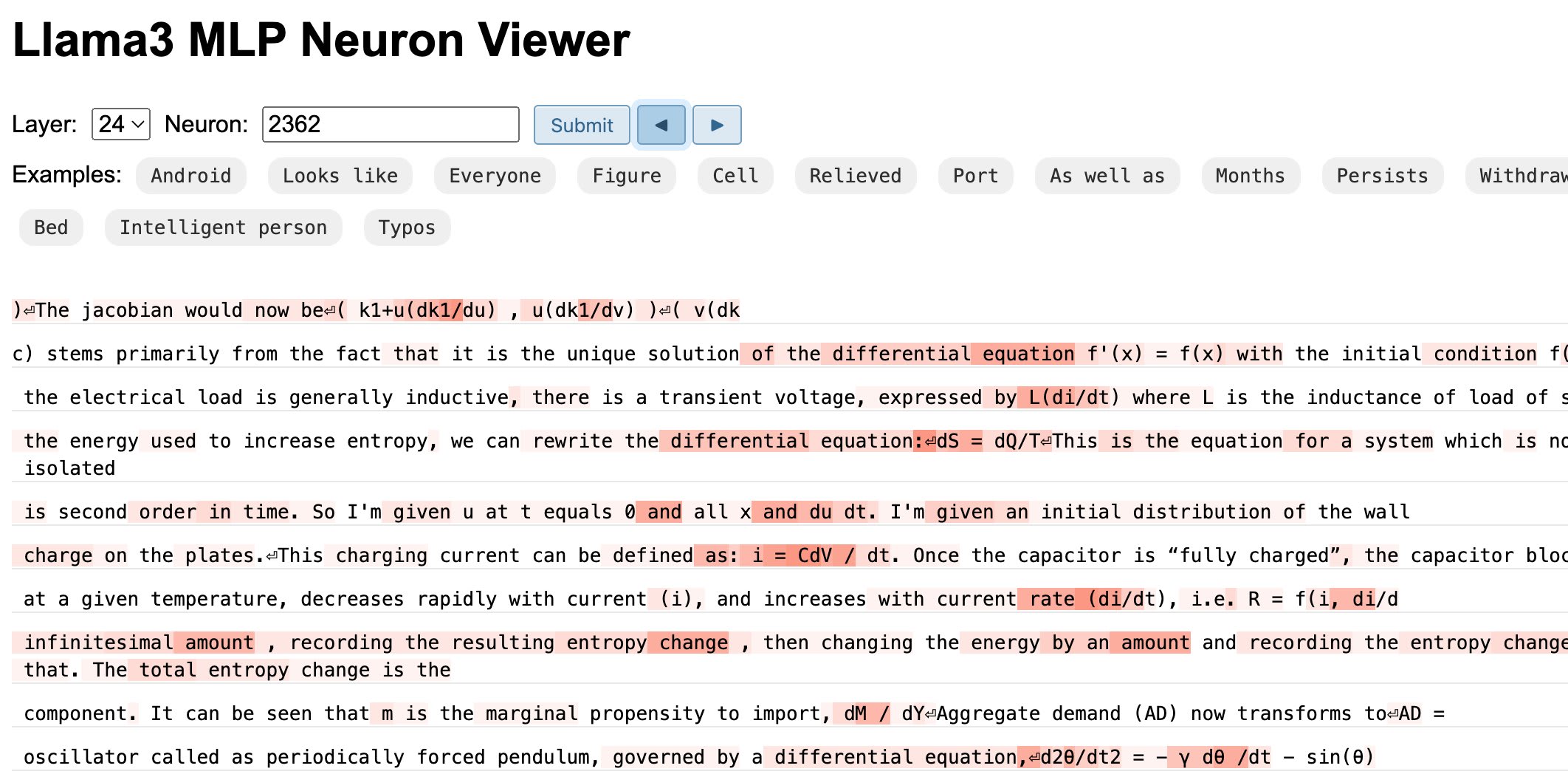
Overview. The dataset includes a total of more than 14 million text snippets from the FineWeb-Edu dataset (Guilherme et al. 2024). There are 32 snippets for each of the 458,752 MLP neurons in the Llama-3-8B model. Each snippet is 64 tokens long and strongly activates the corresponding neuron at the token in the middle of the snippet. See examples at here and here. We go into detail how we construct the dataset in the next section.
Open access. The data can be freely accessed on the Hugging Face llama3-8b-mlp-neurons dataset. Please note that we do not claim any copyright over the text snippets.
Example features. We found interesting features at all layers of the network. At lower layers, we discovered neurons triggered by a single word or subword, such as here and here. In higher layers, we observed neurons activated by more abstract concepts. For example, a neuron in layer 15 is triggered by the idea of “something being removed or relieved to alleviate a negative situation.” Another neuron in layer 24 activates when discussing highly intelligent, smart, and successful individuals. Interestingly, we found a neuron that is highly active when encountering a broken word.
Method
We used the open-weight Llama-3-8B base model from Meta, which is a powerful model that can be run on a single GPU. Since Meta did not release their training and evaluation dataset, we instead used the recently released FineWeb-Edu dataset (Guilherme et al. 2024), specifically the sample-10BT subset, which provides approximately 10 billion tokens.
To collect neuron activations, we randomly sampled segments of 128 tokens from the dataset and fed them into the network. We then recorded the MLP neuron activations for the last 64 tokens of each input segment. To reduce memory and disk usage during data collection, we only kept the top 32 snippets whose 96th token triggered the highest activation for each neuron. Additionally, we only stored the position of each sequence instead of the entire sequence itself, which also helped to significantly reduce memory usage.
Note that the Llama-3-8B model has 32 layers, and each layer contains 14,336 MLP neurons, resulting in a total of 458,752 neurons in the entire network.
In total, we fed 4 million examples into the model and collected the top 32 examples for each MLP neuron across the network. The entire process took approximately 12 hours to complete on an A100 GPU with 48GB of RAM.
In the end, for each neuron, we obtained 32 snippets, each 64 tokens long (32 prefix tokens, the token with the high activation, and 31 suffix tokens). The result is a dataset of more than 14 million text snippets that strongly activate MLP neurons in the middle of each snippet.
Related work
MLP Neuron Interpretability. Our method for creating the dataset closely follows the procedure described by (Geva et al. 2020). In their work, the authors collect MLP neuron activations of a small transformer language model trained on WikiText. They propose that MLP layers act as key-value memory, where the key captures the input pattern and the values refine the output distribution to predict tokens that follow the input pattern.
(Bills et al. 2023) propose a method that uses GPT-4 to automatically generate hypotheses explaining MLP neuron activations in the GPT-2 XL model. Using this approach, the authors demonstrate that approximately 5,203 neurons (1.7% of the total 307,200 neurons) have a high explanation score (above 0.7). They also open-source their neuron explainer implementation,3 which we expect can be applied to our dataset to help automatically explain Llama-3 MLP neurons.
Monosemanticity and Polysemanticity. It has been shown (Bricken et al. 2023; Bills et al. 2023) that most neurons in the transformer network are polysemantic, meaning that each neuron is activated by multiple features. This is a consequence of the fact that the number of neurons in the network is much smaller than the number of features that can be learned from the training data. Recent work on sparse autoencoders (SAE) by (Bricken et al. 2023; Templeton et al. 2024; Gao et al. 2024) shows promising results in using SAE to help decompose transformers hidden states into a large number of highly interpretable monosemantic neurons.
Conclusion
We hope the release of a text snippet dataset that highly triggers MLP neurons in the Llama-3-8B model will facilitate research into understanding real-world large language models. We also expect that by using this dataset in conjunction with LLM assistance, we can greatly extend our understanding of Llama-3 neurons. We encourage everyone to visit our neuron viewer page to explore the neurons themselves, which can greatly improve the intuition into how these models work internally.