This is a linkpost for https://arxiv.org/abs/2304.11389
Interesting. My previous upper estimate of human lifetime training token equivalent was ~10B tokens: (300 WPM ~ 10T/s * 1e9/s ), so 2B tokens makes sense if people are reading/listening only 20% of the time.
So the next remaining question is what causes human performance on downstream tasks to scale much more quickly as a function of tokens or token perplexity (as LLMs need 100B+, perhaps 1T+ tokens to approach human level). I'm guessing it's some mix of:
From the abstract:
The authors show strongly U-shaped curves relating the additional predictive power that adding per-token suprisal gives to a regression model and model perplexity.
From the results section:
I'm not going to speculate too much but these curves remind me a lot of the diagram describing Chris Olah's view on the difficulty of mechanistic interpretability with model power:
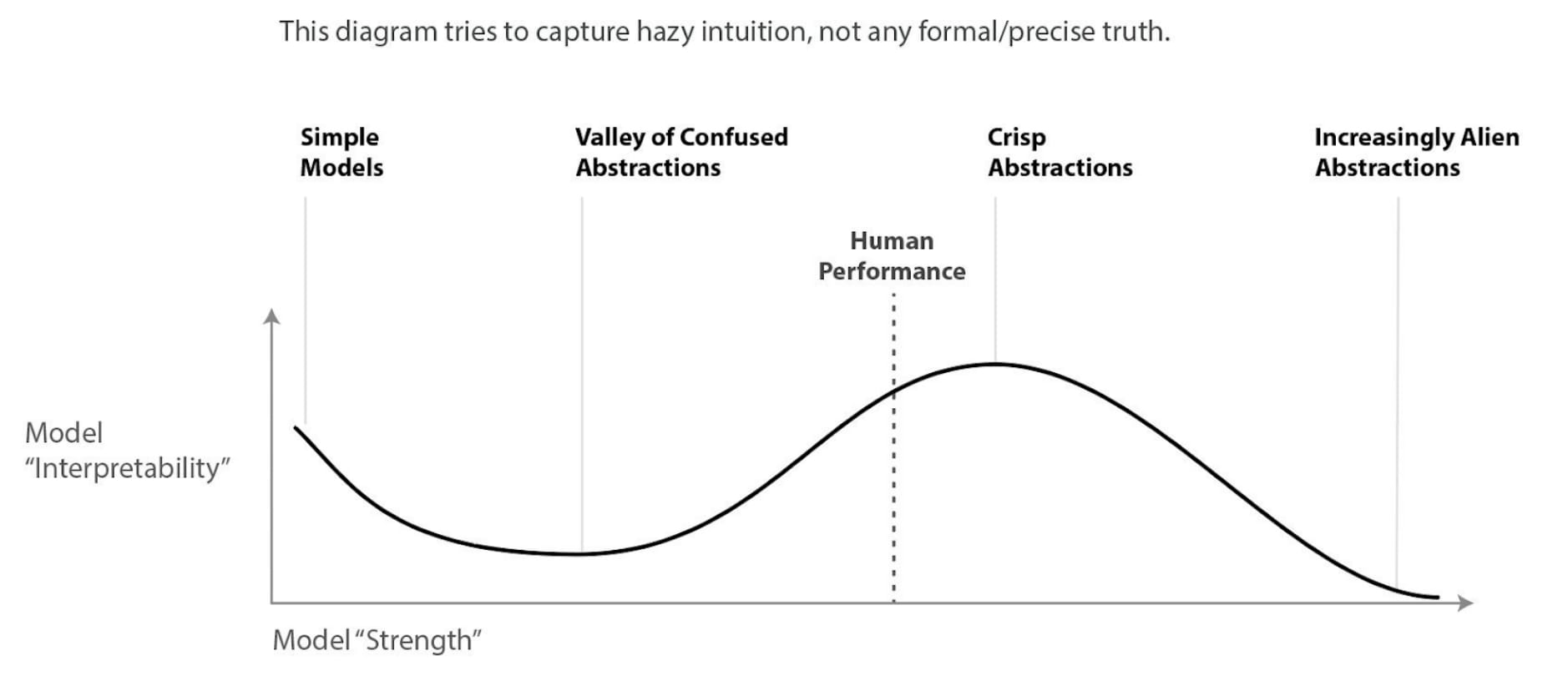
Other remarks:
-It would be neat to compare the perplexity inflexion point with the Redwood estimates of human perplexity scores on text.
-Performance seems well tied to model perplexity and tokens but not so much to model size