There are various different timelines/takeoff dynamics scenarios:
Figure 1
In this post, we’re going to set out our understanding of the case for short timelines and slow, continuous takeoff as the safest path to AGI.
A few reasons why laying out this case seems worth doing:
OpenAI’s strategy assumes that short timelines and slow, continuous takeoff are the safest path to AGI.[1]Whether or not this is the safest path, the fact that OpenAI thinks it’s true and is one of the leading AI labs makes it a path we’re likely to take. Humanity successfully navigating the transition to extremely powerful AI might therefore require successfully navigating a scenario with short timelines and slow, continuous takeoff.
Short timelines and slow, continuous takeoff might indeed be the safest path to AGI. After spending some time trying to state the strongest version of the case, we think it’s stronger than we initially expected (and than many in the AI safety community seem to assume).
If it’s not true that short timelines and slow, continuous takeoff are the safest path to AGI, it might be really important to convince people at OpenAI that this is the case. It seems unlikely that it’s possible to do this without deeply understanding their current view.
Note that Sam Altman usually refers just to slow takeoff rather than slow continuous takeoff, but in this piece we discuss slow continuous takeoff, because we think that it’s the strongest way of making this case and that it’s likely that this is what Altman means.
Disclaimers:
Neither of us work at OpenAI or are in touch with OpenAI leadership. This post represents our best guess charitable interpretation of the case. We’ve done a lot of filling in the blanks on our side in order to make the arguments as coherent as possible. Our ideal in writing this post is to pass an ideological Turing Test, where Sam Altman could read this post and think ‘yes, exactly, that’s why I think that’. Probably we fall short of this as we haven’t engaged with Sam directly.
Neither of us fully buys that short timelines and slow, continuous takeoff are the safest path to AGI. We’re writing this post to improve our (and hopefully other people’s) understanding of the position. In this post, we don’t give our overall evaluation of the case - just present what seem to us like the strongest arguments for it.
We hope this post will serve as a jumping off point for critiques which engage more deeply with OpenAI’s strategy. (And where the post doesn’t faithfully capture OpenAI views, we’d love to get comments pointing this out.)
Slow, continuous takeoff is safer than fast, discontinuous takeoff
To successfully navigate the transition to extremely powerful AI, we want AI safety and governance efforts to keep pace with AI capabilities (or ideally, to exceed them). When compared to fast discontinuous takeoff, slow continuous takeoff seems much safer from this perspective:
Fast takeoff doesn’t give society time to figure out how to respond to advanced capabilities and the destabilisation which could follow from them. It also doesn’t give us to coordinate once the danger is clearer and more imminent.
Discontinuous takeoff entails jumps where capabilities could suddenly exceed existing levels of safety/governance.
Figuring out how to make systems safe will likely depend on bootstrapping up safety using the last generation (e.g. using GPT-5 to align GPT-6). Even if takeoff is (relatively) fast, this makes continuity preferable to discontinuity, as continuity makes it more likely that bootstrapping alignment works.
While slow, continuous takeoff likely means more actors are involved and greater proliferation of powerful models (in comparison to one lab suddenly jumping far ahead of any others), this is partially mitigated if timelines are short. Short timelines make it more likely that leading actors remain concentrated in the West and among the current crop of top companies. These companies may be more likely to be able to coordinate with one another on safety than the group of companies/state actors who would replace them should the current leaders slow down.
Slow, continuous takeoff is more likely given short timelines than long ones
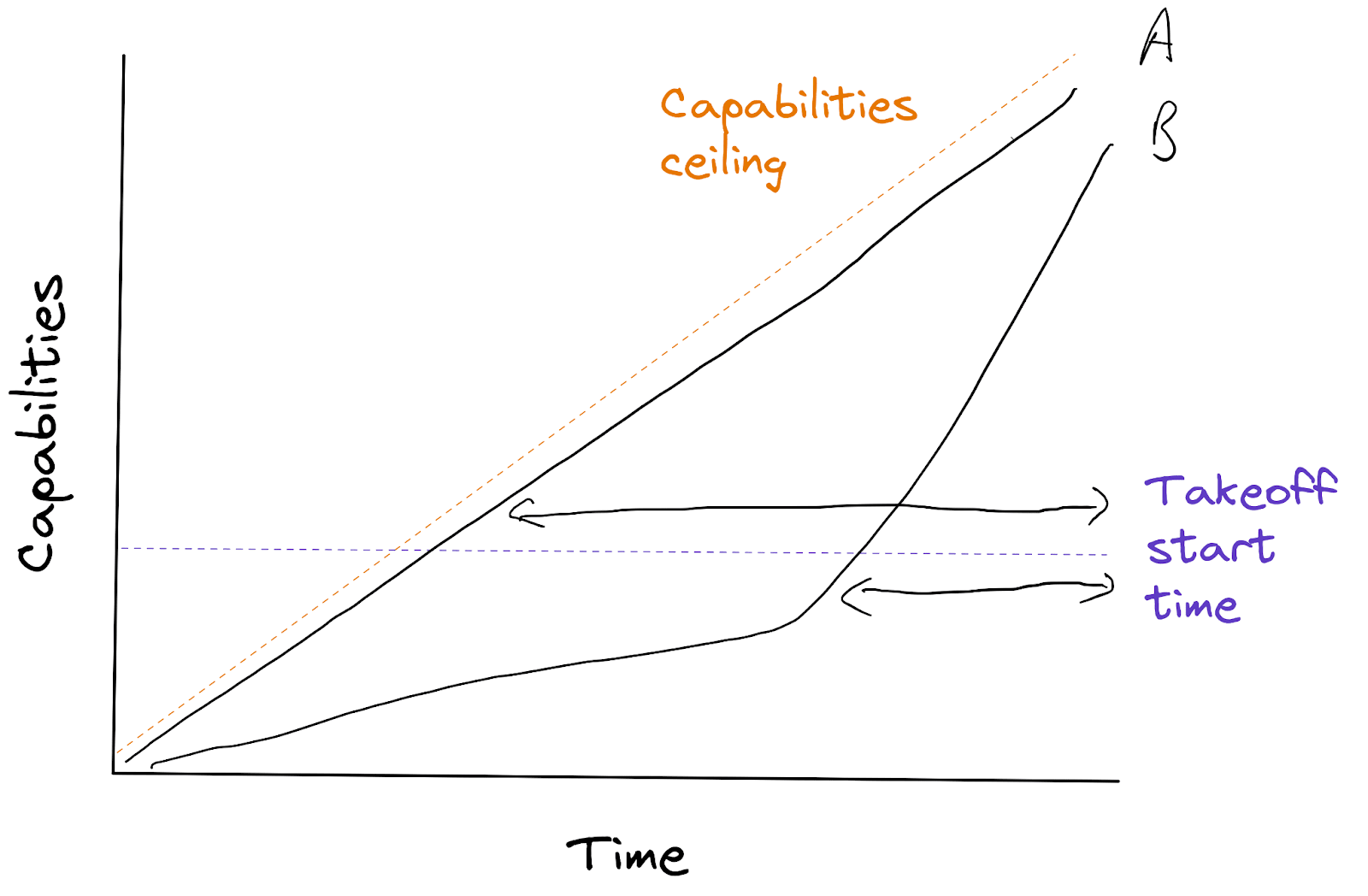
The two slow, continuous takeoff scenarios in Figure 1 above were:
The long timelines scenario looks safer: takeoff is just as continuous, we get just as much time during takeoff, and we also get more time before takeoff. It seems to strictly dominate the short timelines version.
In the abstract, we think this is true.
The argument for short timelines and slow, continuous takeoff as the safest path to AGI is that slow, continuous takeoff is more likely given short timelines - rather than the argument being that short timelines would be preferable to long timelines if you could actually get slow, continuous takeoff in both scenarios.
The strongest arguments that slow, continuous takeoff is more likely given short timelines are:
Coordination seems likely to be particularly easy now relative to later. Coordination allows us to move more slowly through takeoff, all else equal.[2]
Right now there are only a handful of frontier labs. Over time, the number of labs might increase, for instance if:
Commercial incentives get stronger.
Barriers to entry lower.
More labs catch up.
More labs splinter from existing labs.
Relatedly, currently the frontier labs are all Western. Coordination between frontier labs in China and the West seems likely to be harder than coordination between Western labs, for cultural and geopolitical/natsec reasons.
Most of the frontier labs recognise that AI risk is a thing and explicitly support AI safety work. It seems at least plausible that current labs are unusually cautious compared to labs we might see in future.[3]
AI development is compute intensive so it’s obvious who is doing it. Over sufficiently long timeframes, this might no longer hold.
It’s plausible that compute overhang is low now relative to later, and this tends towards slower, more continuous takeoff.[4]
There might be discontinuous increases in compute supply in future, via:
Advances in computing technologies.
Discontinuous increases in the capital available for compute.
Future regulation might create a compute overhang. E.g. a moratorium on large training runs directly translates to a larger compute overhang.
Time during takeoff is more valuable than time before, so it’s worth trading time now for time later
Both of the points we’ve made so far (that slow, continuous takeoff is safer; and that it’s more likely given short timelines) could be true without making short timelines and slow, continuous takeoff the safest path to AGI.
It could be the case that the safety gains from slow, continuous takeoff are dominated by larger safety gains from longer timelines. In other words, the expected gains from slow, continuous takeoff need to outweigh the expected costs of absolutely shorter timelines, for short timelines and slow, continuous takeoff to be the safest path to AGI.
So an important additional part of this argument is that time during takeoff is more valuable than time before takeoff, for various important kinds of work:[5]
AI safety.
During a slow, continuous takeoff, we’d be able to do empirical work on very powerful systems, such that most of the useful safety work might end up being done in this period.[6]
Regulation.
Regulation is often responsive, and governments and international organisations need time to draft, approve and implement new measures. Time after the deployment of very powerful systems, but before the deployment of AGI, is most useful from this perspective.
Human adaptation to AI capabilities.
The resilience of the human population might depend in part on humans adapting to AI systems, learning to make positive use of them, and learning to combat negative effects of AI. You can think of this as a kind of coevolution, or as the number of shots humanity gets at deploying AI safely.
If you buy this argument, then it can be worth trading time now for time later (i.e. reducing the absolute number of months to AGI in exchange for more months during takeoff).
The argument has a few possible implications:
Developing AI more slowly might actually be more dangerous than developing it quickly, if slowing creates compute (or other kinds of) overhang.
Compute and other kinds of overhang are really dangerous, as they increase the chances of discontinuities.
As the leading lab in an AI race, it’s plausible that it might be better to use up all of the available overhang at the expense of shorter timelines, in order to get more continuous progress and reduce expected takeoff speed.
This is especially likely to be true if you think that using up overhang will only moderately speed up timelines, or that takeoff can be lengthened significantly.
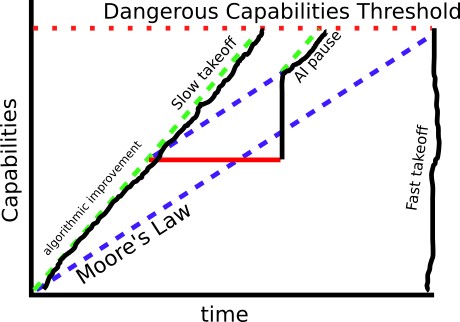
The idea that moving faster now will reduce speed later is a bit counterintuitive. Here’s a drawing illustrating the idea:
Figure 2
Deploying powerful AI systems might be safer than not deploying them (depending on how confident you are that a given system is safe, and to what degree).
Not deploying could just mean that someone else deploys similar things at some time lag.[7] This increases discontinuity in (deployed) AI capabilities, which increases risk (because of the following two bullet points).
Deployment might give us important empirical alignment information.
Deployment might further regulation or human adaptation.
It’s possible to safely navigate short timelines and slow, continuous takeoff
It might be the case that short timelines and slow, continuous takeoff are the safest path to AGI, but still incredibly dangerous, such that there aren’t viable theories of victory even assuming this path.
This is the part of the argument that we understand least well, as it mostly boils down to how hard alignment is, and neither of us have technical expertise. We’re going to try to cite what we think people’s arguments here are, but our understanding is shallow and we can’t properly unpack the claims. We’d love to see better versions of this claim in the comments.
We think that the main arguments that there are indeed safe paths to AGI assuming short timelines and slow, continuous takeoff are:
Leading actors can coordinate once it’s clear that systems are dangerous (e.g. an eval reveals dangerous capabilities) and slow down before any truly dangerous systems are released. The time bought by this slowdown is enough for us to either coordinate on a longer slowdown or to solve alignment well enough to deploy AGI.
The empirical evidence on alignment so far is positive. See Jan Leike here.
As long as progress is continuous, then we should be able to bootstrap our way to alignment using AI alignment assistants. The case here is something like:
Solving alignment is much harder than building AIs to help us solve alignment.
Evaluating alignment research is much easier than doing it.
Alignment research will only require narrow AI.
As long as progress is continuous, we don’t need to worry too much about alignment assistants themselves being dangerous. LLMs can already help with alignment research; if you think they don’t pose an existential threat, then they should also be able to help us build something better than themselves at alignment, which also doesn’t pose an existential threat, and so on.
In any given case, you're using older models to align newer ones. So developing AI alignment assistants doesn’t push forward the development frontier much.
LLMs might be unusually easy to align, relative to other systems.[8]
Possible cruxes
There are many possible disagreements with the case we’ve tried to make above. Cruxes which we expect to be most important here are:
How hard alignment is.
How feasible it is to slow AI development without increasing compute overhang.
How likely it is that there are unavoidable discontinuities in AI capabilities and/or compute supply.
How cautious you expect current labs to be relative to future labs.
Whether you expect compute overhang to increase or decrease over time.
How feasible you think coordination is and what is needed in order to make meaningful coordination happen (e.g. will a capability demonstration revealed by a safety evaluation tip the scales toward meaningful coordination being feasible).
“AGI could happen soon or far in the future; the takeoff speed from the initial AGI to more powerful successor systems could be slow or fast. Many of us think the safest quadrant in this two-by-two matrix [of short/long timelines & slow/fast takeoff] is short timelines and slow takeoff speeds; shorter timelines seem more amenable to coordination and more likely to lead to a slower takeoff due to less of a compute overhang, and a slower takeoff gives us more time to figure out empirically how to solve the safety problem and how to adapt.” Sam Altman, Planning for AGI and beyond.
On the need for coordination: “we need some degree of coordination among the leading development efforts to ensure that the development of superintelligence occurs in a manner that allows us to both maintain safety and help smooth integration of these systems with society. There are many ways this could be implemented; major governments around the world could set up a project that many current efforts become part of, or we could collectively agree (with the backing power of a new organization like the one suggested below) that the rate of growth in AI capability at the frontier is limited to a certain rate per year.” Altman, Brockman and Sutskever, Governance of superintelligence.
See e.g. Paul Christiano’s response to “RLHF (and other forms of short-term “alignment” progress) make AI systems more useful and profitable, hastening progress towards dangerous capabilities” here. Also a paraphrase of this position in Eli Tyre’s post here.
"A few years ago it looked like the path to AGI was by training deep RL agents from scratch in a wide range of games and multi-agent environments. These agents would be aligned to maximizing simple score functions such as survival and winning games and wouldn’t know much about human values. Aligning the resulting agents would be a lot of effort: not only do we have to create a human-aligned objective function from scratch, we’d likely also need to instill actually new capabilities into the agents like understanding human society, what humans care about, and how humans think.
Large language models (LLMs) make this a lot easier: they come preloaded with a lot of humanity’s knowledge, including detailed knowledge about human preferences and values. Out of the box they aren’t agents who are trying to pursue their own goals in the world and and their objective functions are quite malleable." Jan Leike here.
Whether or not this is the safest path, the fact that OpenAI thinks it’s true and is one of the leading AI labs makes it a path we’re likely to take. Humanity successfully navigating the transition to extremely powerful AI might therefore require successfully navigating a scenario with short timelines and slow, continuous takeoff.
You can't just choose "slow takeoff". Takeoff speeds are mostly a function of the technology, not company choices. If we could just choose to have a slow takeoff, everything would be much easier! Unfortunately, OpenAI can't just make their preferred timelines & "takeoff" happen. (Though I agree they have some influence, mostly in that they can somewhat accelerate timelines).
You need to think about your real options and expected value of behavior. If we're in a world where technology allows for a fast takeoff world and alignment is hard, (EY World) I imagine the odds of survival with company acceleration is 0% and the odds of survival without is 1%.
But if we live in a world where compute/capital/other overhangs are a significant influence in AI capabilities and alignment is just tricky, company acceleration would seem like it could improve the chances of survival pretty significantly, maybe from 5% to 50%.
These obviously aren't the only two possible worlds, but if they were and both seemed equally likely, I would strongly prefer a policy of company acceleration because the EV for me breaks down way better over the probabilities.
I guess 'company acceleration' doesn't convey as much information or sell as well which is why people don't use that phrase, but that's the policy they're advocating for- not 'hoping really hard that we're in a slow takeoff world.'
Yeah, good point. I guess the truer thing here is 'whether or not this is the safest path, important actors seem likely to act as though it is'. Those actors probably have more direct control over timelines than takeoff speed, so I do think that this fact is informative about what sort of world we're likely to live in - but agree that no one can just choose slow takeoff straightforwardly.
whether or not this is the safest path, important actors seem likely to act as though it is
It's not clear to me that this is true, and it strikes me as maybe overly cynical. I get the sense that people at OpenAI and other labs are receptive to evidence and argument, and I expect us to get a bunch more evidence about takeoff speeds before it's too late. I expect people's takes on AGI safety plans to evolve a lot, including at OpenAI. Though TBC I'm pretty uncertain about all of this―definitely possible that you're right here.
I think this is a great post that lays out the argument well, as I understand it.
Whether or not this is the safest path, the fact that OpenAI thinks it’s true and is one of the leading AI labs makes it a path we’re likely to take.
I want to push against this point somewhat. I don't think OpenAI's opinion is going to matter as much as the opinions of governments. OpenAI does influence government opinion, but in case there's a disagreement, I don't expect OpenAI to prevail (except perhaps if we're already deep into a takeoff).
Indeed I expect governments will generally be really skeptical that we should radically transform civilization in the next decade or so. Most people are conservative about new technologies, even if they usually tolerate them. AI is going to cause unusually rapid change, which will presumably prompt a greater-than-normal backlash.
I anticipate that people will think the argument presented in this post is very weak (even if it's not), and assume that the argument is guided by motivated reasoning. In fact, this has been my experience after trying to explain this argument to EAs several times in the last few months. I could be wrong of course, but I don't expect OpenAI will have much success convincing skeptical third parties that delaying is suboptimal.
I don't think OpenAI's opinion is going to matter as much as the opinions of governments. OpenAI does influence government opinion, but in case there's a disagreement, I don't expect OpenAI to prevail (except perhaps if we're already deep into a takeoff).
But behind the scenes, OpenAI has lobbied for significant elements of the most comprehensive AI legislation in the world—the E.U.’s AI Act—to be watered down in ways that would reduce the regulatory burden on the company, according to documents about OpenAI’s engagement with E.U. officials obtained by TIME from the European Commission via freedom of information requests.
In several cases, OpenAI proposed amendments that were later made to the final text of the E.U. law—which was approved by the European Parliament on June 14, and will now proceed to a final round of negotiations before being finalized as soon as January.
In 2022, OpenAI repeatedly argued to European officials that the forthcoming AI Act should not consider its general purpose AI systems—including GPT-3, the precursor to ChatGPT, and the image generator Dall-E 2—to be “high risk,” a designation that would subject them to stringent legal requirements including transparency, traceability, and human oversight. [...]
“By itself, GPT-3 is not a high-risk system,” said OpenAI in a previously unpublished seven-page document that it sent to E.U. Commission and Council officials in September 2022, titled OpenAI White Paper on the European Union’s Artificial Intelligence Act. “But [it] possesses capabilities that can potentially be employed in high risk use cases.” [...]
OpenAI’s lobbying effort appears to have been a success: the final draft of the Act approved by E.U. lawmakers did not contain wording present in earlier drafts suggesting that general purpose AI systems should be considered inherently high risk. Instead, the agreed law called for providers of so-called “foundation models,” or powerful AI systems trained on large quantities of data, to comply with a smaller handful of requirements including preventing the generation of illegal content, disclosing whether a system was trained on copyrighted material, and carrying out risk assessments. OpenAI supported the late introduction of “foundation models” as a separate category in the Act, a company spokesperson told TIME.
The fact that OpenAI was successful at a narrow lobbying effort doesn't surprise me. It's important to note that the dispute was about whether GPT-3 and Dall-E 2 should be considered "high risk". I think it's very reasonable to consider those technologies low risk. The first one has been around since 2020 without major safety issues, and the second merely generates images. I predict the EU + US government would win a much higher stakes 'battle' against OpenAI.
The idea that moving faster now will reduce speed later is a bit counterintuitive. Here’s a drawing illustrating the idea:
Figure 2
One minor nitpick. Slow takeoff implies shorter timelines, so B should reach the top of the capabilities axis at a later point in time than A.
If you want to think intuitively about why this is true, consider that in our current world (slow takeoff) tools exist (like codex,GPT-4) that accelerate AI research. If we simply waited to deploy any AI tools until we could build fully super-intelligent AGI, we would have more time overall.
Now, it might still be the case that "Time during takeoff is more valuable than time before, so it’s worth trading time now for time later", but it's still wrong to depict the graphs as taking the same amount of time to reach a certain level of capabilities.
This is helpful to think about when considering policies like the pause, as we are gaining some amount of time at the current level of AI development and sacrificing some (smaller) amount of time at a higher level of development. Even assuming no race dynamics, determining whether a pause is beneficial depends on the ratio of the time-now/time-later and the relative value of those types of time.
A reasonable guess is that algorithmic Improvements matter about as much as Moore's Law, so effectively we are trading 6 months now for 3 months later.
Another important fact is that in the world of fast takeoff/pause, we arrive at the "dangerous capabilities level" with less total knowledge. If we assume some fungibility of AI capabilities/safety research, then all of the foregone algorithmic improvement means we have also foregone some safety related knowledge.
Great post, good to hear these ideas. Since I studied AI risk more this year I have come to believe that a slow takeoff is more likely and there needs to be more discussion about how to handle such a situation.
A few points: You seem to treat hardware progress as fixed and steady - the opposite could be the case, to me that seems a lot easier to coordinate hardware factories than software. Chip manufacture depends on a massive very fragile supply chain across multiple countries. It wouldn't take many players to slow things down for everyone.
You can certainly make a case that short timelines are safer as there is less AI integration in society, no robots in every home, military etc.
Slow takeoff is still very fast for society to adapt and there is no guarantee it can adapt, especially the higher in capabilities the end time is. If its sufficiently high then I don't think society can adapt at all no matter what. WBE, neural lace/Neuralink and similar are needed and quickly even in a "slow" scenario.
I think time in takeoff is 10* more valuable for alignment research than time beforehand, it is becoming clear that some of the earlier alignment assumptions were not correct, I expect that to continue as we know more. Before GPT 3.5 it seemed the alignment field was essentially stuck and was making little to no progress.
Evaluating alignment research is much easier than doing it.
Alignment research will only require narrow AI.
Nice comprehension of the different takeoff scenarios!
I am no researcher in this area, and I also know I might be wrong about many things in the following. But have doubts about the two above statements.
Evaluating alignment is still manageable right now. We are still smarter than the AI, at least somewhat. However, I do not see a viable path to evaluate the true level of capabilities of AI once it is smarter than us. Once that point is reached, we will only be able to ask questions we do not know the answers to to evaluate how smart the model is, but by definition we also do not know how smart you have to be to answer the questions. Is solving the riemann hypothesis something that is just outside our grasp or is 1000x more intelligence than ours needed? We cant reliably say.
I might be wrong and there is some science or theory that does exactly that, but I do not know of one.
And the same is true with alignment. Once the AI is smarter than us we can not assume that our tests of the model output work anymore. Considering that even right now our tests are seemingly not very good (At least according to the youtube video from AI Explained) and we did not notice for this long, I do not think we will be able to rely on the questionaires we use right now anymore, as it might behave differently if it notices we test it. And it might notice we test it from the first question we ask it.
This means, evaluating alignment research is in fact also incredibly hard. We need to outwit a smarter entity or directly interpret what happens inside the model. To know we missed no cases during that process is harder than devising a test that covers most cases.
The second part I personally wonder a bit about. On the one hand it might be possible that we can use many different AIs for every field that are highly specialized. But that would struggle with connections between those fields, so if we have a chemistry and biology AI we might not fully cover biochemistry. If we have a biochemistry AI we might not fully cover medicine. Then there is food. Once we get to food, we also need to watch physics, like radiation or material sciences.
And in all of that we might still want certain things like let it write a book about Oppenheimer and how he built a nuclear bomb, so it also needs to be able to look at context in terms of an artistic standpoint. It needs to be able to evaluate if it is wrong on purpose out of context, such as a book, or if it seriously attempted to do it but got it wrong this time.
I feel like this can only be achived with another general AI, not a narrow AI that is much more narrow than the tested AI. Else the tested AI might simply get away with a wider "scheme".
Another slight note about claiming lower models will evaluate higher models, if the current trend of aligned AIs being less capabale than unaligned AIs stays this way, this is a bad idea. You showed lots of linear curves here, but the y axis should be logarithmic in terms of capabilites. This means the distance between gpt5 and gpt6 might be 10x or in a similar region, especially if the smarter model is yet to be aligned and the other model is already reigned in.
As explained earlier, external testing of the model by a less intelligent entity becomes almost impossible in my opinion. I am unsure about how much a finetuned version might be able to close the gap, but my other point also shows that finetuning will only get us so far, as we cant narrow it down too far. For better than AGI (with AGI being as smart as the best human experts in every tasks) we very likely need to fully understand what happens inside the model to align it. But I really hope this is not the case, as I do not see people pausing long enough to seriously put the effort into that.
Man I found this a bit confusing to read simply due to counterintuitive use of the word ‘slow’. I think ‘slow takeoff’ is a misleading term (ie naively read it implies “long timelines”) and particularly weird when contrasting it with fast timelines.
And, like, guys you were so close here with the phrase ‘continuous takeoff’ which is a perfectly good, non confusing term! But then went out of its way to keep both terms at once. I kept parsing “slow, continuous takeoff” as meaning “continuous as long timelines.”
[This comment is no longer endorsed by its author]Reply
"‘continuous takeoff’ which is a perfectly good, non confusing term" - but it doesn't capture everything we're interested in here. I.e. there are two dimensions:
speed of takeoff (measured in time)
smoothness of takeoff (measured in capabilities)
It's possible to have a continuous but very fast (i.e. short in time) takeoff, or a discontinuous but slow (i.e. long in time) takeoff.
Tried to capture this in figure 1, but I agree it's a bit confusing.
hmm, I might be even more confused than I thought.
I thought you were using "short timelines" / "long timelines" to refer to speed of takeoff, and "fast, discontinuous takeoff" vs "slow, discontinuous takeoff" to refer to smoothness of takeoff, and the part I was objecting to was including both "fast/slow" and "discontinuous/continuous" for the "smoothness of takeoff" labeling.
Oh, I see what you mean now. (i.e. there are three axis, one of which is "length of time overall from-now-until-takeoff-finishes" and one of which is "length of time between "takeoff starting" and "overwhelming superintelligence?").
Okay, now rather than making a somewhat pedantic complaint about which term to use, my take is "I think fast/slow takeoff is used to mean enough different things that it's worth spelling out in words what the three-axis is that the graphs are explaining." I agree that the graphs-as-shown do convey the thing. When I first read the post I thought I understood the point they were making and started skimming before actually parsing the distinction. The might just be me, but, I'd hazard a bet that it'd be a relatively common thing to get confused about.
(my first comment was more gripy/annoyed than I think I endorse, sorry about that. I do overall think the essay was a good/useful thing to write, this just happens to be a pet peeve of mine)
There are various different timelines/takeoff dynamics scenarios:
In this post, we’re going to set out our understanding of the case for short timelines and slow, continuous takeoff as the safest path to AGI.
A few reasons why laying out this case seems worth doing:
The arguments we’re going to lay out are:
Note that Sam Altman usually refers just to slow takeoff rather than slow continuous takeoff, but in this piece we discuss slow continuous takeoff, because we think that it’s the strongest way of making this case and that it’s likely that this is what Altman means.
Disclaimers:
We hope this post will serve as a jumping off point for critiques which engage more deeply with OpenAI’s strategy. (And where the post doesn’t faithfully capture OpenAI views, we’d love to get comments pointing this out.)
Slow, continuous takeoff is safer than fast, discontinuous takeoff
To successfully navigate the transition to extremely powerful AI, we want AI safety and governance efforts to keep pace with AI capabilities (or ideally, to exceed them). When compared to fast discontinuous takeoff, slow continuous takeoff seems much safer from this perspective:
Slow, continuous takeoff is more likely given short timelines than long ones
The two slow, continuous takeoff scenarios in Figure 1 above were:
The long timelines scenario looks safer: takeoff is just as continuous, we get just as much time during takeoff, and we also get more time before takeoff. It seems to strictly dominate the short timelines version.
In the abstract, we think this is true.
The argument for short timelines and slow, continuous takeoff as the safest path to AGI is that slow, continuous takeoff is more likely given short timelines - rather than the argument being that short timelines would be preferable to long timelines if you could actually get slow, continuous takeoff in both scenarios.
The strongest arguments that slow, continuous takeoff is more likely given short timelines are:
Time during takeoff is more valuable than time before, so it’s worth trading time now for time later
Both of the points we’ve made so far (that slow, continuous takeoff is safer; and that it’s more likely given short timelines) could be true without making short timelines and slow, continuous takeoff the safest path to AGI.
It could be the case that the safety gains from slow, continuous takeoff are dominated by larger safety gains from longer timelines. In other words, the expected gains from slow, continuous takeoff need to outweigh the expected costs of absolutely shorter timelines, for short timelines and slow, continuous takeoff to be the safest path to AGI.
So an important additional part of this argument is that time during takeoff is more valuable than time before takeoff, for various important kinds of work:[5]
If you buy this argument, then it can be worth trading time now for time later (i.e. reducing the absolute number of months to AGI in exchange for more months during takeoff).
The argument has a few possible implications:
It’s possible to safely navigate short timelines and slow, continuous takeoff
It might be the case that short timelines and slow, continuous takeoff are the safest path to AGI, but still incredibly dangerous, such that there aren’t viable theories of victory even assuming this path.
This is the part of the argument that we understand least well, as it mostly boils down to how hard alignment is, and neither of us have technical expertise. We’re going to try to cite what we think people’s arguments here are, but our understanding is shallow and we can’t properly unpack the claims. We’d love to see better versions of this claim in the comments.
We think that the main arguments that there are indeed safe paths to AGI assuming short timelines and slow, continuous takeoff are:
Possible cruxes
There are many possible disagreements with the case we’ve tried to make above. Cruxes which we expect to be most important here are:
“AGI could happen soon or far in the future; the takeoff speed from the initial AGI to more powerful successor systems could be slow or fast. Many of us think the safest quadrant in this two-by-two matrix [of short/long timelines & slow/fast takeoff] is short timelines and slow takeoff speeds; shorter timelines seem more amenable to coordination and more likely to lead to a slower takeoff due to less of a compute overhang, and a slower takeoff gives us more time to figure out empirically how to solve the safety problem and how to adapt.” Sam Altman, Planning for AGI and beyond.
On the need for coordination: “we need some degree of coordination among the leading development efforts to ensure that the development of superintelligence occurs in a manner that allows us to both maintain safety and help smooth integration of these systems with society. There are many ways this could be implemented; major governments around the world could set up a project that many current efforts become part of, or we could collectively agree (with the backing power of a new organization like the one suggested below) that the rate of growth in AI capability at the frontier is limited to a certain rate per year.” Altman, Brockman and Sutskever, Governance of superintelligence.
Though this might not be the case, if awareness and understanding of AI risk and AI safety increases dramatically over time.
Though this might not be the case if race dynamics intensify.
See e.g. Zach Stein-Perlman here.
See e.g. Paul Christiano’s response to “RLHF (and other forms of short-term “alignment” progress) make AI systems more useful and profitable, hastening progress towards dangerous capabilities” here. Also a paraphrase of this position in Eli Tyre’s post here.
Either because of information leakage, or because of independent progress.
"A few years ago it looked like the path to AGI was by training deep RL agents from scratch in a wide range of games and multi-agent environments. These agents would be aligned to maximizing simple score functions such as survival and winning games and wouldn’t know much about human values. Aligning the resulting agents would be a lot of effort: not only do we have to create a human-aligned objective function from scratch, we’d likely also need to instill actually new capabilities into the agents like understanding human society, what humans care about, and how humans think.
Large language models (LLMs) make this a lot easier: they come preloaded with a lot of humanity’s knowledge, including detailed knowledge about human preferences and values. Out of the box they aren’t agents who are trying to pursue their own goals in the world and and their objective functions are quite malleable." Jan Leike here.