Somewhat striking that the top 3 orgs on the career interest survey are Anthropic, DeepMind, and OpenAI.
I personally suspect that these are not the most impactful places for most MATS scholars to work (relative to say, UKAISI/USAISI, METR, starting new orgs/projects).
Regardless, curious if you have any thoughts on this & if it reflects anything about the culture/epistemics in MATS.
(And to be clear, I think the labs do have alignment teams that care about making progress & I suspect that there are some cases where joining a frontier lab alignment team is the most impactful thing for a scholar.)
I think the high interest in working at scaling labs relative to governance or nonprofit organizations can be explained by:
- Most of the scholars in this cohort were working on research agendas for which there are world-leading teams based at scaling labs (e.g., 44% interpretability, 17% oversight/control). Fewer total scholars were working on evals/demos (18%), agent foundations (8%), and formal verification (3%). Therefore, I would not be surprised if many scholars wanted to pursue interpretability or oversight/control at scaling labs.
- There seems to be an increasing trend in the AI safety community towards the belief that most useful alignment research will occur at scaling labs (particularly once there are automated research assistants) and external auditors with privileged frontier model access (e.g., METR, Apollo, AISIs). This view seems particularly strongly held by proponents of the "AI control" metastrategy.
- Anecdotally, scholars seemed generally in favor of careers at an AISI or evals org, but would prefer to continue pursuing their current research agenda (which might be overdetermined given the large selection pressure they faced to get into MATS to work on that agenda).
- Starting new technical AI safety orgs/projects seems quite difficult in the current funding ecosystem. I know of many alumni who have founded or are trying to found projects who express substantial difficulties with securing sufficient funding.
Note that the career fair survey might tell us little about how likely scholars are to start new projects as it was primarily seeking interest in which organizations should attend, not in whether scholars should join orgs vs. found their own.
Thanks for these explanations– I think they're reasonable & insightful. A few thoughts:
Most of the scholars in this cohort were working on research agendas for which there are world-leading teams based at scaling labs
I suspect there's probably some bidirectional causality here. People want to work at scaling labs because they're interested in the research that scaling labs are doing, and people want to focus on the research the scaling labs are doing because they want to work at scaling labs.
There seems to be an increasing trend in the AI safety community towards the belief that most useful alignment research will occur at scaling labs
I think this is true among a subset of the AI safety community but I don't think this characterizes the AI safety community as a whole. For example, another (even stronger IMO) trend in the AI safety community has been towards the belief that policy work & technical governance work is more important than many folks previously expected it to be (see EG Paul joining USAISI, MIRI shifting to technical governance, UKAISI being established, and not to mention the general surge in interest among policymakers).
One perspective on this could be "well, MATS is a technical research program, and we're adding some governance mentors, so shrug." Another perspective on this could be "well, it seems like perhaps MATS is shifting more slowly than one might've imagined, resulting in a culture/ecosystem/mentor cohort/selection process/fellow cohort that disproportionately wants to join scaling labs."
RE shifting more slowly or having a disproportionate focus, note that the ERA fellowship has prioritized toward governance and technical governance– 2/3 of their fellows will be focused on governance + technical governance projects. I'm not necessarily saying this is what would be best for MATS, but it at least points out that we should be seeing MATS' focus on incubating "technical researchers that want to work at scaling labs" as something that's part of its design.
I might be a bit "biased" in that I work in AI policy and my worldview generally suggests that AI policy (as well as technical governance) is extremely neglected. I personally think it's harder to make the case that giving scaling labs better alignment talent is as neglected– it's still quite important, but scaling labs are extremely popular & I think their ability to hire (and pay for) top technical talent is much stronger than that of governments.
Anecdotally, scholars seemed generally in favor of careers at an AISI or evals org, but would prefer to continue pursuing their current research agenda
Again, I think my primary response here is something like the research interests of the MATS cohort are a function of the program and its selection process– not an immutable characteristic of the world. The ERA example is a "strong" example of prioritizing people with other interests, but I imagine there are plenty of "weaker" things MATS could be doing to select/prioritize fellows who had an interest in governance & technical governance. (Or put differently, my guess is that there are ways in which the current selection process and mentor pool disproportionately attracts/favors those who are interested in the kinds of topics you mentioned).
If I could wave a magic wand, I would probably have MATS add many more governance & technical governance mentors and shift to something closer to ERA's breakdown. This would admittedly be a rather big shift for MATS, and perhaps current employees/leaders/funders wouldn't want to do it. I think it ought to be seriously considered, though, and if I were a MATS exec person or a MATS funder I would probably be pushing for this. Or at least asking some serious questions along the lines of "do we really feel like the most impactful thing a training program could be doing right now is serving as an upskilling program for the scaling labs?" (With all due respect to the importance of getting great people to the scaling labs, acknowledging the importance of technical research at scaling labs, agreeing with some of Neel's points etc.)
It seems plausible to me that at least some MATS scholars are somewhat motivated by a desire to work at scaling labs for money, status, etc. However, the value alignment of scholars towards principally reducing AI risk seems generally very high. In Winter 2023-24, our most empirical research dominated cohort, mentors rated the median scholar's value alignment at 8/10 and 85% of scholars were rated 6/10 or above, where 5/10 was “Motivated in part, but would potentially switch focus entirely if it became too personally inconvenient.” To me this is a very encouraging statistic, but I’m sympathetic to concerns that well-intentioned young researchers who join scaling labs might experience value drift, or find it difficult to promote safety culture internally or sound the alarm if necessary; we are consequently planning a “lab safety culture” workshop in Summer. Notably, only 3.7% of surveyed MATS alumni say they are working on AI capabilities; in one case, an alumnus joined a scaling lab capabilties team and transferred to working on safety projects as soon as they were able. As with all things, maximizing our impact is about striking the right balance between trust and caution and I’m encouraged by the high apparent value alignment of our alumni and scholars.
We additionally believe:
- Advancing researchers to get hired at lab safety teams is generally good;
- We would prefer that the people on lab safety teams have more research experience and are more value-aligned, all else equal, and we think MATS improves scholars on these dimensions;
- We would prefer lab safety teams to be larger, and it seems likely that MATS helps create a stronger applicant pool for these jobs, resulting in more hires overall;
- MATS creates a pipeline for senior researchers on safety teams to hire people they have worked with for up to 6.5 months in-program, observing their compentency and value alignment;
- Even if MATS alumni defect to work on pure capabilities, we would still prefer them to be more value-aligned than otherwise (though of course this has to be weighed against the boost MATS gave to their research abilities).
Regarding “AI control,” I suspect you might be underestimating the support that this metastrategy has garnered in the technical AI safety community, particularly among prosaic AGI safety thought leaders. I see Paul’s decision to leave ARC in favor of the US AISI as a potential endorsement of the AI control paradigm over intent alignment, rather than necessarily an endorsement of an immediate AI pause (I would update against this if he pushes more for a pause than for evals and regulations). I do not support AI control to the exclusion of other metastrategies (including intent alignment and Pause AI), but I consider it a vital and growing component of my strategy portfolio.
It’s true that many AI safety projects are pivoting towards AI governance. I think the establishment of AISIs is wonderful; I am in contact with MATS alumni Alan Cooney and Max Kauffman at the UK AISI and similarly want to help the US AISI with hiring. I would have been excited for Vivek Hebbar’s, Jeremy Gillen’s, Peter Barnett’s, James Lucassen’s, and Thomas Kwa’s research in empirical agent foundations to continue at MIRI, but I am also excited about the new technical governance focus that MATS alumni Lisa Thiergart and Peter Barnett are exploring. I additionally have supported AI safety org accelerator Catalyze Impact as an advisor and Manifund Regrantor and advised several MATS alumni founding AI safety projects; it's not easy to attract or train good founders!
MATS has been interested in supporting more AI governance research since Winter 2022-23, when we supported Richard Ngo and Daniel Kokotajlo (although both declined to accept scholars past the training program) and offered support to several more AI gov researchers. In Summer 2023, we reached out to seven handpicked governance/strategy mentors (some of which you recommended, Akash), though only one was interested in mentoring. In Winter 2023-24 we tried again, with little success. In preparation for the upcoming Summer 2024 and Winter 2024-25 Programs, we reached out to 25 AI gov/policy/natsec researchers (who we asked to also share with their networks) and received expressions of interest from 7 further AI gov researchers. As you can see from our website, MATS is supporting four AI gov mentors in Summer 2024 (six if you count Matija Franklin and Philip Moreira Tomei, who are primarily working on value alignment). We’ve additionally reached out to RAND, IAPS, and others to provide general support. MATS is considering a larger pivot, but available mentors are clearly a limiting constraint. Please contact me if you’re an AI gov researcher and want to mentor!
Part of the reason that AI gov mentors are harder to find is that programs like the RAND TASP, GovAI, IAPS, Horizon, ERA, etc. fellowships seem to be doing a great job collectively of leveraging the available talent. It’s also possible that AI gov researchers are discouraged from mentoring at MATS because of our obvious associations with AI alignment (it’s in the name) and the Berkeley longtermist/rationalist scene (we’re talking on LessWrong and operate in Berkeley). We are currently considering ways to support AI gov researchers who don’t want to affiliate with the alignment, x-risk, longtermist, or rationalist communities.
I’ll additionally note that MATS has historically supported much research that indirectly contributes to AI gov/policy, such as Owain Evans’, Beth Barnes’, and Francis Rhys Ward’s capabilities evals, Evan Hubinger’s alignment evals, Jeffrey Ladish’s capabilities demos, Jesse Clifton’s and Caspar Oesterheldt’s cooperation mechanisms, etc.
In Winter 2023-24, our most empirical research dominated cohort, mentors rated the median scholar's value alignment at 8/10 and 85% of scholars were rated 6/10 or above, where 5/10 was “Motivated in part, but would potentially switch focus entirely if it became too personally inconvenient.”
Wait, aren't many of those mentors themselves working at scaling labs or working very closely with them? So this doesn't feel like a very comforting response to the concern of "I am worried these people want to work at scaling labs because it's a high-prestige and career-advancing thing to do", if the people whose judgements you are using to evaluate have themselves chosen the exact path that I am concerned about.
Of the scholars ranked 5/10 and lower on value alignment, 63% worked with a mentor at a scaling lab, compared with 27% of the scholars ranked 6/10 and higher. The average scaling lab mentors rated their scholars' value alignment at 7.3/10 and rated 78% of their scholars at 6/10 and higher, compared to 8.0/10 and 90% for the average non-scaling lab mentor. This indicates that our scaling lab mentors were more discerning of value alignment on average than non-scaling lab mentors, or had a higher base rate of low-value alignment scholars (probably both).
I also want to push back a bit against an implicit framing of the average scaling lab safety researcher we support as being relatively unconcerned about value alignment or the positive impact of their research; this seems manifestly false from my conversations with mentors, their scholars, and the broader community.
implicit framing of the average scaling lab safety researcher we support as being relatively unconcerned about value alignment or the positive impact of their research
Huh, not sure where you are picking this up. I am of course very concerned about the ability of researchers at scaling labs being capable of evaluating their positive impact in respect to their choice of working at a scaling lab (their job does after all depend on them not believing that is harmful), but of course they are not unconcerned about their positive impact.
This indicates that our scaling lab mentors were more discerning of value alignment on average than non-scaling lab mentors, or had a higher base rate of low-value alignment scholars (probably both).
The second hypothesis here seems much more likely (and my guess is your mentors would agree). My guess is after properly controlling for that you would find a mild to moderate negative correlation here.
But also, more importantly, the set of scholars from which MATS is drawing is heavily skewed towards the kind of person who would work at scaling labs (especially since funding has been heavily skewing towards funding the kind of research that can occur at scaling labs).
Thanks for this (very thorough) answer. I'm especially excited to see that you've reached out to 25 AI gov researchers & already have four governance mentors for summer 2024. (Minor: I think the post mentioned that you plan to have at least 2, but it seems like there are already 4 confirmed and you're open to more; apologies if I misread something though.)
A few quick responses to other stuff:
- I appreciate a lot of the other content presented. It feels to me like a lot of it is addressing the claim "it is net positive for MATS to upskill people who end up working at scaling labs", whereas I think the claims I made were a bit different. (Specifically, I think I was going for more "Do you think this is the best thing for MATS to be focusing on, relative to governance/policy"and "Do you think there are some cultural things that ought to be examined to figure out why scaling labs are so much more attractive than options that at-least-to-me seem more impactful in expectation").
- RE AI control, I don't think I'm necessarily underestimating its popularity as a metastrategy. I'm broadly aware that a large fraction of the Bay Area technical folks are excited about control. However, I think when characterizing the AI safety community as a whole (not just technical people), the shift toward governance/policy macrostrategies is (much) stronger than the shift toward the control macrostrategy. (Separately, I think I'm more excited about foundational work in AI control that looks more like the kind of thing that Buck/Ryan have written about is separate from typical prosaic work (e.g., interpretability), even though lots of typical prosaic work could be argued to be connected to the control macrostrategy.)
- +1 that AI governance mentors might be harder to find for some of the reasons you listed.
Do you think there are some cultural things that ought to be examined to figure out why scaling labs are so much more attractive than options that at-least-to-me seem more impactful in expectation?
As a naive guess, I would consider the main reasons to be:
- People seeking jobs in AI safety often want to take on "heroic responsibility." Work on evals and policy, while essential, might be seen as "passing the buck" onto others, often at scaling labs, who have to "solve the wicked problem of AI alignment/control" (quotes indicate my caricature of a hypothetical person). Anecdotally, I've often heard people in-community disparage AI safety strategies that primarily "buy time" without "substantially increasing the odds AGI is aligned." Programs like MATS emphasizing the importance of AI governance and including AI strategy workshops might help shift this mindset, if it exists.
- Roles in AI gov/policy, while impactful at reducing AI risk, likely have worse quality-of-life features (e.g., wages, benefits, work culture) than similarly impactful roles in scaling labs. People seeking jobs in AI safety might choose between two high-impact roles based on these salient features without considering how many others making the same decisions will affect the talent flow en masse. Programs like MATS might contribute to this problem, but only if the labs keep hiring talent (unlikely given poor returns on scale) and the AI gov/policy orgs don't make attractive offers (unlikely given METR and Apollo pay pretty good wages, high status, and work cultures comparable to labs; AISIs might be limited because government roles don't typically pay well, but it seems there are substantial status benefits to working there).
- AI risk might be particularly appealing as a cause area to people who are dispositionally and experientially suited to technical work and scaling labs might be the most impactful place to do many varieties of technical work. Programs like MATS are definitely not a detriment here, as they mostly attract individuals who were already going to work in technical careers, expose them to governance-adjacent research like evals, and recommend potential careers in AI gov/policy.
Cheers, Akash! Yep, our confirmed mentor list updated in the days after publishing this retrospective. Our website remains the best up-to-date source for our Summer/Winter plans.
Do you think this is the best thing for MATS to be focusing on, relative to governance/policy?
MATS is not currently bottlenecked on funding for our current Summer plans and hopefully won't be for Winter either. If further interested high-impact AI gov mentors appear in the next month or two (and some already seem to be appearing), we will boost this component of our Winter research portfolio. If ERA disappeared tomorrow, we would do our best to support many of their AI gov mentors. In my opinion, MATS is currently not sacrificing opportunities to significantly benefit AI governance and policy; rather, we are rate-limited by factors outside of our control and are taking substantial steps to circumvent these, including:
- Substantial outreach to potential AI gov mentors;
- Pursuing institutional partnerships with key AI gov/policy orgs;
- Offering institutional support and advice to other training programs;
- Considering alternative program forms less associated with rationality/longtermism;
- Connecting scholars and alumni with recommended opportunities in AI gov/policy;
- Regularly recommending scholars and alumni to AI gov/policy org hiring managers.
We appreciate further advice to this end!
Do you think there are some cultural things that ought to be examined to figure out why scaling labs are so much more attractive than options that at-least-to-me seem more impactful in expectation?
I think this is a good question, but it might be misleading in isolation. I would additionally ask:
- "How many people are the AISIs, METR, and Apollo currently hiring and are they mainly for technical or policy roles? Do we expect this to change?"
- "Are the available job opportunities for AI gov researchers and junior policy staffers sufficient to justify pursuing this as a primary career pathway if one is already experienced at ML and particularly well-suited (e.g., dispositionally) for empirical research?"
- "Is there a large demand for AI gov researchers with technical experience in AI safety and familiarity with AI threat models, or will most roles go to experienced policy researchers, including those transitioning from other fields? If the former, where should researchers gain technical experience? If the latter, should we be pushing junior AI gov training programs or retraining bootcamps/workshops for experienced professionals?"
- "Are existing talent pipelines into AI gov/policy meeting the needs of established research organizations and think tanks (e.g., RAND, GovAI, TFS, IAPS, IFP, etc.)? If not, where can programs like MATS/ERA/etc. best add value?"
- "Is there a demand for more organizations like CAIP? If so, what experience do the founders require?"
Starting new technical AI safety orgs/projects seems quite difficult in the current funding ecosystem. I know of many alumni who have founded or are trying to found projects who express substantial difficulties with securing sufficient funding.
Interesting - what's like the minimum funding ask to get a new org off the ground? I think something like $300k would be enough to cover ~9 mo of salary and compute for a team of ~3, and that seems quite reasonable to raise in this current ecosystem for pre-seeding a org.
Yeah, that amount seems reasonable, if on the low side, for founding a small org. What makes you think $300k is reasonably easy to raise in this current ecosystem? Also, I'll note that larger orgs need significantly more.
(EDIT: I just saw Ryan posted a comment a few minutes before mine, I agree substantially with it)
As a Google DeepMind employee I'm obviously pretty biased, but this seems pretty reasonable to me, assuming it's about alignment/similar teams at those labs? (If it's about capabilities teams, I agree that's bad!)
I think the alignment teams generally do good and useful work, especially those in a position to publish on it. And it seems extremely important that whoever makes AGI has a world-class alignment team! And some kinds of alignment research can only really be done with direct access to frontier models. MATS scholars tend to be pretty early in their alignment research career, and I also expect frontier lab alignment teams are a better place to learn technical skills especially engineering, and generally have a higher talent density there.
UK AISI/US AISI/METR seem like solid options for evals, but basically just work on evals, and Ryan says down thread that only 18% of scholars work on evals/demos. And I think it's valuable both for frontier labs to have good evals teams and for there to be good external evaluators (especially in government), I can see good arguments favouring either option.
44% of scholars did interpretability, where in my opinion the Anthropic team is clearly a fantastic option, and I like to think DeepMind is also a decent option, as is OpenAI. Apollo and various academic labs are the main other places you can do mech interp. So those career preferences seem pretty reasonable to me there for interp scholars.
17% are on oversight/control, and for oversight I think you generally want a lot of compute and access to frontier models? I am less sure for control, and think Redwood is doing good work there, but as far as I'm aware they're not hiring.
This is all assuming that scholars want to keep working in the same field they did MATS for, which in my experience is often but not always true.
I'm personally quite skeptical of inexperienced researchers trying to start new orgs - starting a new org and having it succeed is really, really hard, and much easier with more experience! So people preferring to get jobs seems great by my lights
Thanks, Neel! I responded in greater detail to Ryan's comment but just wanted to note here that I appreciate yours as well & agree with a lot of it.
My main response to this is something like "Given that MATS selects the mentors and selects the fellows, MATS has a lot of influence over what the fellows are interested in. My guess is that MATS' current mentor pool & selection process overweights interpretability and underweights governance + technical governance, relative to what I think would be ideal."
I see this is strongly disagree voted - I don't mind, but I'd be curious for people to reply with which parts they disagree with! (Or at least disagree react to specific lines). I make a lot of claims in that comment, though I personally think they're all pretty reasonable. The one about not wanting inexperienced researchers to start orgs, or "alignment teams at scaling labs are good actually" might be spiciest?
Thank you for explaining the shift from scholar support to research management— I found that quite interesting and I don’t think I would’ve intuitively assumed that the research management frame would be more helpful.
I do wonder if as the summer progresses, the role of the RM should shift from writing the reports for mentors to helping the fellows prepare their own reports for mentors. IMO, fellows getting into the habit of providing these updates & learning how to “manage up” when it comes to mentors seems important. I suspect something in the cluster of “being able to communicate well with mentors//manage your mentor+collaborator relationships” is one of the most important “soft skills” for research success. I suspect a transition from “tell your RM things that they include in their report” to “work with your RM to write your own report” would help instill this skill.
This is a good question. I agree that “managing up” is a very important skill in general! It’s one of the primary focuses of our research manager training.
However, I want to acknowledge whether to focus on this with scholars seems to be a question of tradeoffs regarding MATS’s priorities: to what extent are we prioritizing scholars upskilling in deep technical/research understanding available at MATS, versus them upskilling in generalizable soft skills (that they could theoretically learn elsewhere)? If we were to theoretically prioritize solely the former, maximizing time and efficiency between scholars and mentors through taking this burden off of them seems better as this allows us time to improve research skills + time spent on their projects. If we were to prioritize soft skills, though, focusing on them managing up well seems like a good option. (And FWIW, we already do the latter indirectly - but not as a structured offering. We focus much more on things like project management + unblocking scholars with our remaining time.)
To me MATS has primarily been about providing the best environment we can for AI safety mentorship, and increasing the amount of AI safety talent+collabs in the world. I can see an argument here that teaching scholars to manage up does in fact benefit their trajectories holistically, but I would want to balance this against the tradeoff of marginal time spent helping them directly in the counterfactual, be it project management or otherwise preparing for meeting with their mentor. During the main, 10-week phase of MATS, scholars are incredibly time crunched to get a research project done. This pushes me slightly against the idea of spending much concentrated effort on this during the main phase, but not necessarily against some amount of time on this.
That all being said, this seems like a potentially good fit for:
- a workshop towards the late-middle-or-end of the main 10-week phase, or
- sometime over the 4-month extension phase, where scholars continue working with their mentors in an increasingly independent fashion.
…and maybe some time spent on this towards the end of the 10-week phase in 1-1s, but I’d want to allow wiggle room for prioritizing more critical work as needed.
the research management frame would be more helpful.
I think btw it gets more value than scholar support because it's a proactive service we offer to all scholars on a given stream, rather than waiting for them to only come to us when there's a problem.
the role of the RM should shift from writing the reports for mentors to helping the fellows prepare their own reports for mentors.
I spend a fair amount of time on my projects helping people prep for meetings with their supervisors, yeah. I also used to have scholars edit my written reports before sending to Ethan.
I'm noticing there are still many interp mentors for the current round of MATS -- was the "fewer mech interp mentors" change implemented for this cohort, or will that start in Winter or later?
Last program, 44% of scholar research was on interpretability, 18% on evals/demos, 17% on oversight/control, etc. In summer, we intend for 35% of scholar research to be on interpretability, 17% on evals/demos, 27% on oversight/control, etc., based on our available mentor pool and research priorities. Interpretability will still be the largest research track and still has the greatest interest from potential mentors and applicants. The plot below shows the research interests of 1331 MATS applicants and 54 potential mentors who have applied for our Summer 2024 or Winter 2024-25 Programs.
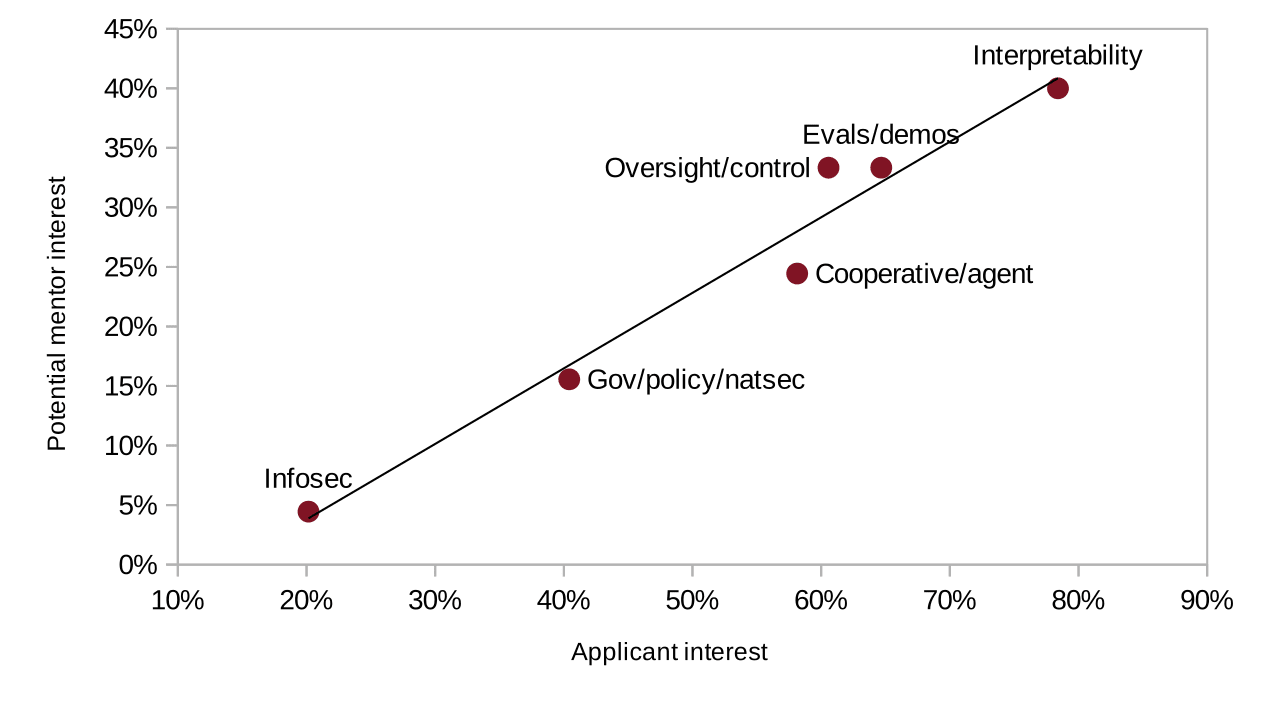
Note that number of scholars is a much more important metric than number of mentors when it comes to evaluating MATS resources, as scholar per mentors varies a bunch (eg over winter I had 10 scholars, which is much more than most mentors). Harder to evaluate from the outside though!
I don't know the answer to your actual question, but I'll note there are slightly fewer mech interp mentors than mentors listed in the "AI interpretability" area (though all of them are at least doing "model internals"). I'd say Stephen Casper and I aren't focused on interpretability in any narrow sense, and Nandi Schoots' projects also sound closer to science of deep learning than mech interp. Assuming we count everyone else, that leaves 11 out of 39 mentors, which is slightly less than ~8 out of 23 from the previous cohort (though maybe not by much).
I love this report! Shed a tear at not seeing Microsoft on the organization interest chart though 🥲. We could be a better Bing T_T.
Oh, I think we forgot to ask scholars if they wanted Microsoft at the career fair. Is Microsoft hiring AI safety researchers?
Yes, here’s an open position: Research Scientist - Responsible & OpenAI Research. Of course, responsible AI differs from interpretability, activation engineering, or formal methods (e.g., safeguarded AI, singular learning theory, agent foundations). I’ll admit we are doing less of that than I’d prefer, partially because OpenAI shares some of its ‘secret safety sauce’ with us, though not all, and not immediately.
Note from our annual report that we are employing 1% fewer people than this time last year, so headcount is a very scarce resource. However, the news reported we invested ~£2.5b in setting up a new AI hub in London under Jordan Hoffman, with 600 new seats allocated to it (officially, I can neither confirm nor deny these numbers).
I’m visiting there this June after EAG London. We’re the only member of the Frontier Model Forum without an alignment team. MATS scholars would be excellent hires for such a team, should one be established. Some time ago, a few colleagues helped me draft a white paper to internally gather momentum and suggest to leadership that starting one there might be beneficial. Unfortunately, I am not permitted to discuss the responses or any future plans regarding this matter.
Co-Authors: @Rocket, @LauraVaughan, @McKennaFitzgerald, @Christian Smith, @Juan Gil, @Henry Sleight, @Matthew Wearden, @Ryan Kidd
The ML Alignment & Theory Scholars program (MATS) is an education and research mentorship program for researchers entering the field of AI safety. This winter, we held the fifth iteration of the MATS program, in which 63 scholars received mentorship from 20 research mentors. In this post, we motivate and explain the elements of the program, evaluate our impact, and identify areas for improving future programs.
Summary
Key details about the Winter Program:
Key takeaways from scholar impact evaluation:
Key takeaways from mentor impact evaluation:
Key changes we plan to make for future cohorts:
Theory of Change
MATS expands the talent pipeline for AI safety research by empowering scholars to work on AI safety at existing organizations, found new organizations, or pursue independent research.
To this end, MATS connects scholars with senior research mentors and reduces the barriers for these mentors to take on mentees by providing funding, housing, training, office spaces, research management, networking opportunities, and logistical support. By mentoring MATS scholars, these senior researchers benefit from research assistance and improve their mentorship skills, preparing them to supervise future research more effectively.
MATS aims to select and develop research scholars on three primary dimensions:
Read more about our theory of change here. An article expanding on our theory of change is forthcoming.
Winter Program Overview
Schedule
The Winter 2023-24 Program had three phases.
Mentor Selection
Approach
At a high level of abstraction, MATS faces a complex optimization problem: how should we select mentors and, by extension, scholars that, in expectation, most reduce catastrophic risk from AI? One reason this problem is especially hard is that the value of a portfolio of mentors depends on non-additive interactions; that is, the marginal value of a mentor depends on which other mentors have already been selected working on similar or complementary research agendas. Conscious of these interactions, we aim to construct a “diverse portfolio of research bets” that might contribute to AI safety even if some research agendas prove unviable or require complementary approaches. To make this problem more tractable, we rely on a number of simplifications and heuristics.
Firstly, we take a greedy approach to program impact, focusing on improving the next program rather than committing significant efforts to future programs well in advance. We are unlikely to, for example, save significant funding for a future program when we could use that funding for an additional scholar in the upcoming program, particularly as the marginal rejected scholars are generally quite talented. Secondly, we take a mentor-centric approach to scholar selection, beginning with mentor selection and then conducting scholar selection to mentor specifications. In part this is because the number of scholars we can support in a given program depends on the level of funding we receive, which is somewhat determined by funders’ enthusiasm for the mentors in that program. Primarily, however, we adopt a mentor-centric approach because we believe that mentors are the best judge of contributors to their research projects.
We ask potential mentors to submit an expression of interest form, which is then reviewed by the MATS Executive. When evaluating potential mentors, we chiefly consider these heuristics:
Heuristics 5 and 6 are systemic considerations, where we assess the whole-field impact of supporting mentors suggested by heuristics 1-4. For example, if a mentor is already well-served by an academic talent pipeline or hiring infrastructure, perhaps we do not provide significant marginal value. Additionally, if we support too many mentors pursuing a particular style of research, we might unintentionally steer the composition of the AI safety research field, given the size of our program (~60 scholars) relative to the size of the field (~500 technical researchers).
Scholar Allocation
Because MATS was funding-constrained in Winter 2023-24, we could not admit as many scholars as our selected mentors would have preferred. Consequently, the MATS Executive allocated scholar “slots” to mentors based on the value of the marginal scholar for each mentor (up to the mentors’ self-expressed caps). For example, we might have supported an experienced mentor with four scholar slots before supporting a less experienced mentor with one scholar slot. Conversely, allocating one scholar to a new mentor might have offered higher marginal value than providing an eighth scholar to an experienced mentor.
We surveyed mentors about the opportunity cost of taking on an additional scholar.
For 95% of mentors, their time spent on an additional scholar would have traded off against progress on their own projects.
Winter Mentor Portfolio
Of the 23 mentors in the Winter 2023-24 program, 7 were returning from a previous MATS program: Jesse Clifton, Evan Hubinger, Vanessa Kosoy, Jeffrey Ladish, Neel Nanda, Lee Sharkey, and Alex Turner. We welcomed 16 new mentors for the winter: Adrià Garriga Alonso, Stephen Casper, David ‘davidad’ Dalrymple, Shi Feng, Jesse Hoogland, Erik Jenner, David Lindner, Julian Michael, Daniel Murfet, Caspar Oesterheld, David Rein, Jessica Rumbelow, Jérémy Scheurer, Asa Cooper Stickland, Francis Rhys Ward, and Andy Zou.
These mentors represented 10 research agendas:
Mentors’ Counterfactual Winters
We surveyed mentors about how they would have spent their winters if they had not mentored for MATS.
For 74% of respondents, mentoring traded off against time spent on the same projects they pursued outside of MATS. 26% would have spent some counterfactual time on projects they did not have time for during MATS.
Other Mentorship Programs
Some mentors indicated that if they had not mentored for MATS, they would have spent their counterfactual winters mentoring for a different program. Concurrent with the winter MATS Program, Constellation, a Berkeley AI safety office, ran two research upskilling programs: the Astra Fellowship, and the Visiting Researchers Program. Mentors who indicated they would have counterfactually mentored for a different program may have had Constellation or another program in mind.
Scholar Selection
Our application process for scholars was highly competitive. Of 429 applicants, 15% were accepted for the Research Phase.[1] Five of these 63 scholars participated entirely remotely; the rest participated in-person for at least part of the program. There was considerable variance in acceptance rates between mentors (2.6% to 33%). Mentors generally chose to screen applicants with rigorous questions and tasks.[2]
Why employ such a difficult application process? First, we believe that the distribution of expected impact from prospective scholars is long-tailed, such that most of MATS’ expected impact can be attributed to identifying and developing talent among the most promising applicants.
Second, we are bottlenecked on scholar funding and mentor time, so we cannot accept every good applicant. For these two reasons, it is imperative that our application process achieves resolution in the talent tail. From our Theory of Change:
In particular, given that 74% of mentors would have used their time spent mentoring on their (highly valuable) research if not in program, we feel justified in our high bar for scholar acceptance. We additionally believe, based on our conversations with past applicants and scholars, that the challenging selection problems are often seen as a fun and useful skill-building exercise.
Our rigorous application process reduces noise in our assessments of applicant quality, even at the cost of discouraging some potentially promising candidates from applying. Additional filters reduced the number of scholars admitted to the Extension Phase from the Research Phase.[3]
Strong applicants have demonstrated their abilities in terms of the depth, breadth, and taste dimensions described above. During pre-program recruiting, we informed prospective applicants that our ideal candidate possesses a breadth of AI safety knowledge equivalent to having completed AISF’s Alignment Course, experience with technical research at a postgraduate level (e.g., in CS, ML, math, or physics), and a motivation to pursue a career in AI safety to mitigate catastrophic risk. We clarified that, for some mentors, engineering experience can substitute for research experience. We also encouraged people who did not fit these criteria to apply, noting that many past applicants without high expectations were accepted.
Educational Attainment of Scholars
A variety of educational and employment backgrounds were represented among the admitted cohort. 3% of scholars had no college education, 38% of scholars had at most a bachelor’s degree or were in college, 30% had at most a master’s degree or were in a master’s program, 28% had a PhD or were in a PhD program. Almost half of scholars were students.
The high level of academic and engineering talent entering AI safety continues to impress us, but we remain committed to increasing outreach to experienced researchers and engineers.
Scholars’ Counterfactual Winters
At the start of the program, we prompted scholars, “If MATS didn't exist, this winter I would most likely be…”, instructing them to “pick the category that best describes your most likely counterfactual situation.”
Of the 8 scholars who would have conducted mentored alignment research in the absence of MATS, 4 are undergraduate students, and 3 are pursuing a graduate degree.
Elaborating on their alternative summer plans, many respondents mentioned non-safety technical roles, coursework, and independent research:
Engineering Tests
In our Summer 2023 Retrospective, we expressed our intention to improve our application filtering process.
One component of a better filter for some streams is increased screening for software engineering skill. This can be a costly evaluation process for mentors to run themselves, so for the Winter 2023-24 Program we contracted a SWE evaluation organization to screen applicants for empirical ML research streams.
At the suggestion of Ethan Perez, we contracted CodeSignal to administer engineering tests, which focused on general programming ability, rather than ML experience. Ideally, every applicant to a mentor who focused on empirical research would have been pre-screened with a CodeSignal test, saving the mentor time on scholar selection. Due to budget constraints, we only had enough tests for 20-32% of each mentor’s applicants, so mentors had to manually review each application to determine who would receive a CodeSignal test. For the next program, we expect to administer CodeSignal tests more widely (see Pre-Screening with CodeSignal below).
Of the accepted scholars, 40% achieved perfect CodeSignal scores of 600/600, compared to 15% of applicants. Notably, some applicants who achieved perfect scores were not accepted into the Research Phase. Two mentors disproportionately accounted for the accepted scholars with lower scores. One of these mentors rejected an applicant with a perfect score and an applicant with a near-perfect score, but indicated in a later survey that they wished their applicants had more programming experience.
Stipends
Financial barriers can prevent promising researchers from entering AI safety, so providing grants (referred to here as stipends) to scholars is an important component of programs like ours. While MATS does not provide funding directly to scholars (except via office and housing support and reimbursements for travel and computing costs), AI Safety Support has offered to provide grants to scholars who complete the program. During the 8-week Summer 2023 program, stipends were set at $40/h. Following that program, surveys of our alumni revealed that many would have done MATS for a lower stipend.
The average surveyed alumnus would have participated in MATS for a stipend of $2160/month, or $13.50/h at 40 h/week. Note that 35% of the surveyed alumni said they would have participated in MATS for free; if we discount these alumni, the average minimum stipend was $3486/month, or $21.79/h at 40 h/week. MATS and AI Safety Support ultimately chose a stipend of $4800/month, or $30/h, for the Winter 2023-34 Program because it would have satisfied 85% of alumni, was more than double the average minimum stipend, and was nevertheless larger than that offered by comparable academic mentorship programs. Constellation subsequently chose the same rate for those participating in their Winter programs.
We followed up with some of these alumni to ask for explanations of their low numbers. Some cited savings, alternative funding sources, jobs to return to, the in-kind benefits MATS provides (housing, office, food, etc), and expectations of low compensation as they pivoted into AI safety. One alumnus commented that, while they would have done MATS without a stipend, the stipend was an honest signal that “this is a serious programme that expects to get serious people . . . not just fresh grads with nothing else to do.”
We are cognizant that these alumni are reporting with the benefit of hindsight, so their answers may not reflect the positions of would-be applicants who do not yet know how valuable MATS will be for them. Moreover, these responses are subject to survivorship bias: we could never observe alumni for whom the stipend was too low, because such people would not have joined the program. But these caveats would still apply no matter how high of a stipend we chose. Our alumni responses indicated that we could afford to reduce the stipend without jeopardizing the talent of our applicant pool.
For a fixed budget, setting a lower stipend allows MATS to fund more scholars.[4]At $30/h, MATS was able to accept ~18 more scholars than we could have accommodated under the previous program’s rate. Anecdotally, we have heard of one individual who was deterred from applying but would have applied if the stipend was higher. Given the tradeoff we face, we expect that there will always be cases like this, even under the optimal stipend amount.
Mentor Suggestions
We surveyed mentors about their experiences with our Scholar Selection process. Mentors recommended some improvements:
Mentors elaborated on “Other improvements”:
One mentor followed up on their answer to say “I selected "more qualified candidates to choose from" because that always seems better, but I want to be clear that I'm already impressed by MATS scholars (and think it's definitely worth my time mentoring them).”
We also asked mentors how their scholars could have been better suited for MATS.
One mentor elaborated, “I mean I'd love for my scholars to be better at everything for sure! But at some point they wouldn't want to be my scholars anymore. I think as it was my scholars were very good. One or two are hidden talents where lack of e.g. communication is blocking them from being a great researcher but otherwise they would be.”
To improve scholars along these dimensions, MATS could offer targeted training, but we could also strengthen the quality of the applicant pool and improve our selection process to choose the most qualified applicants.
Neel Nanda’s Training Phase (Nov 20-Dec 22)
In past programs, MATS has used AI Safety Fundamentals’ Alignment 201 course to prepare incoming scholars for the Research Phase. Due to time constraints and scholar feedback, we replaced Alignment 201 with a custom curriculum that scholars completed throughout the Research Phase (see Strategy Discussions below).
Neel Nanda followed an expedited schedule to run his Training Phase, which plays an indispensable role in his scholar selection process, as well as providing a valuable program in its own right. Neel accepted 30 scholars into the Training Phase, of whom 10 progressed to the Research Phase.[5] The first three weeks included live sessions of Neel doing research, brainstorming open problems, and lecturing on Mechanistic Interpretability (core techniques, SAEs); readings groups for papers (Mathematical Framework, Indirect Object Identification, Toy Models of Superposition, and Towards Monosemanticity); discussion groups on topics like “Is Mech Interp Useful?”; and remote opportunities to connect with collaborators. Participants worked together on research challenges, including extensive pair programming.
The second two weeks were dedicated to a Research Sprint, which participants completed in pairs. Neel made acceptance decisions for the Research Phase primarily on the basis of performance in the Sprint. We think that participating in Neel’s Training Phase was likely worth it even for those scholars who did not progress to the next phase, as evidenced by the large number of trainees who elected to audit Neel’s Training Phase without the possibility of progressing and testimonials from past trainees.[6] 24 of Neel’s trainees received a prorated stipend for their participation: $4.8k for this program. 15 others participated in the Training Phase without a stipend due to funding constraints. Accepted pairs of scholars continued work on their Sprint projects in the Research Phase.
Research Phase Elements (Jan 8-Mar 15)
While mentorship is the core of MATS, additional program elements supply other sources of learning and upskilling. Guest researchers host seminars to deliver technical information to scholars, workshops teach research tools that scholars can apply in their projects, and Research Management aims to improve working relationships between scholars and mentors. The next sections elaborate on each of these elements, along with six more elements that fill out our program offerings: Milestone Assignments, the Lighthaven Office, Strategy Discussions, Networking Events, Social Events, and Community Health.
Mentorship
We believe conducting research under an experienced mentor is a crucial input to the development of research leads. Mentors meet with their scholars at least once a week, and some meet more frequently. Mentors differ in their priorities, styles, and expectations. To communicate these differences to applicants, each mentor composed a personal fit statement. For example, the NYU ARG mentorship team broadcasted:
According to scholar ratings, the median scholar’s mentor spent 2.0 hours communicating with them every week, and 3.0 hours for the average scholar.
The average mentor was effective at communicating (8.0/10), engaged with some details of scholars’ projects while delivering high-level feedback on research directions, and balanced an emphasis on research outputs with an emphasis on process.
Mentors also differed in their influence on scholars’ project selections.
The most common arrangement involved mentors “shaping” their scholars’ research, but some mentors had a stronger hand in project selection, assigning topics or presenting a list of possibilities.
Research Management
In previous programs, MATS offered one-on-one “Scholar Support” sessions dedicated to research planning, career planning, productivity improvements, and communication advice. Scholar Support took on some responsibilities that mentors often bear by default, such as brainstorming, rubber-ducking, conflict resolution between scholars, and some goal-setting, which freed up mentors to focus on their comparative advantages: mentoring and providing technical expertise. Scholar Support also offered coaching assistance not typically expected of mentors, such as accountability reminders, helped scholars get more value out of their mentor meetings, and assisted scholars with program milestones. Scholar Support Specialists did not typically meet with mentors, just scholars and MATS leadership.
However, the MATS team noticed gaps in the support Scholar Support was able to offer, so during the Autumn 2023 Extension Phase, the MATS Program Coordinator (London) and mentor Ethan Perez piloted an alternative model of scholar/mentor support we call Research Management. Instead of opt-in Scholar Support meetings emphasizing issues indirectly related to scholars’ research, such as time-management and accountability, MATS staff held a mandatory weekly check-in with each of Ethan’s scholars focused more directly on research questions:
The Research Manager distilled scholars’ responses into weekly reports, which apprised Ethan of his scholars’ progress and challenges. In this way, the Research Manager cultivated a relationship with Ethan, and gained visibility across Ethan’s scholars. These features marked a departure from the Scholar Support model, under which two scholars with the same mentor could meet with two different members of the Scholar Support team, making it difficult to identify common themes.
Our foray into Research Management exceeded our expectations. Ethan testified,
Due to this success, we decided to primarily offer Research Management instead of Scholar Support. In our previous retrospective, we anticipated this shift:
In offering research management help to mentors, Scholar Support will take a more direct role in understanding research blockers, project directions, and other trends in scholar research, and summarizing that information to mentors with scholar consent.
Of the 56 scholars who filled out our final survey, 92% met with a Research Manager at least once. These scholars reported benefiting from Research Management in multiple ways.
Some of the “Other” ways that Research Management helped scholars included:
We also asked mentors how Research Management helped them:
One mentor elaborated on the “other” support, saying, “Specifically I gather the RM gave some useful structure to executing my scholars' projects, which I didn't quite have the ability or time for.”
Seminars & Workshops
As foreshadowed in our previous retrospective, we reduced the volume of seminar offerings for the Winter program. MATS hosted 12 seminars with guest speakers: Buck Shlegeris (twice), Lennart Heim, Fabien Roger, Adam Gleave, Neel Nanda, Vanessa Kosoy, Jesse Hoogland, Evan Hubinger, Marius Hobbhahn, David Krueger, and Owain Evans.
Additionally, some scholars invited their own guests to present, including Logan Riggs, Tomáš Gavenčiak, and Jake Mendel.
We held workshops on EA Global Conference Preparation, Research Idea Concretization (with Erik Jenner), Theories of Change (with Michael Aird), Preventing and Managing Burnout (with Rocket Drew), and Language Model Evals and Workflow Tips (with John Hughes).
As with seminars, scholars organized workshops of their own, including speed meetings, a Neuronpedia interpathon, and a career planning workshop.
Milestone Assignments
Research Plans
Halfway through the Research Phase, every scholar was required to submit a Research Plan (RP), outlining the AI threat model or risk factor motivating their research, a theory of change to address that threat model, and a plan (based on SMART principles) for a project to enact that theory of change. Using this rubric, 10 MATS alumni graded the RPs to offer scholars constructive feedback, provide MATS with an internal metric of success, and occasionally inform Extension Phase acceptance decisions (see Extension Phase below). To ensure success on this milestone, the Research Management team held an RP workshop and office hours session.
We required Research Plans to develop scholars’ ability to contribute to goal-oriented research strategy and to make it easier for scholars to write a subsequent grant proposal. Many scholars repurposed components of their RPs in applications to the Long-Term Future Fund (LTFF) for post-MATS grant support, primarily in the MATS Extension Phase. Thomas Larsen, an LTFF grantmaker, held a workshop to demystify the LTFF’s decision process and funding constraints.
Symposium Presentations
The Research Phase concluded with a two-day Scholar Symposium, during which scholars delivered 10-minute talks on their research projects to their peers and members of the Bay Area AI safety community. In previous programs, we compressed the Symposium to one day by holding simultaneous presentations in two different rooms. We expanded the event to two days so attendees, including scholars, would not have to choose between presentations, and to ease the operational burden of hosting the event. Attendees graded talks according to the rubric, providing scholars with constructive feedback and the MATS team with evaluation data (see Milestone Assignments below). We helped scholars practice their talks and held office hours to answer questions about the assignment. During the week of the Symposium, we also hosted “PowerPoint Karaoke,” at which scholars presented someone else’s slides.[7]
We also held weekly lightning talk sessions, which afforded scholars an opportunity to develop their presentation skills in a low-stakes setting.
Lighthaven Office
The Research Phase took place at the Lighthaven campus in Berkeley. While some scholars lived in one Lighthaven building during the Summer 2023 program, this was our first program using the full property and using it for office space in addition to housing. MATS shared the space with the Lightcone Infrastructure team and a few independent researchers. As a renovated inn, Lighthaven possesses unique features that distinguish it from a traditional office: the property includes six detached buildings, an outdoor event space, common spaces conducive to focused work, and an extensive library.
Strategy Discussions
For this program, we introduced a 7-week AI strategy discussion group series to substitute for our typical pre-program Training Phase. The Alignment 201 curriculum we used in past programs was designed to respect multiple constraints, including remote participation, moderate time commitments, limited facilitation, varied backgrounds, varied career interests, and wide diffusion. Since these constraints do not necessarily apply to MATS, it is unlikely that a curriculum designed under them is the optimal curriculum for training MATS scholars. We structured our new material around the key AI safety strategy cruxes that we observed were relevant for MATS scholars’ research.
During each of the first 7 weeks, scholars participated in a facilitated discussion group on an opt-out basis. From our curriculum post:
The topics of each week were:
The median scholar attended 4 of the 7 strategy discussions. 51% of scholars would have preferred “fewer” discussions, and 5.7% would have preferred “many fewer.” Based on this and other feedback, we intend to make discussion groups opt-in for scholars in future cohorts (see Modified Discussion Groups below). Discussion groups benefited scholars in different ways:
One scholar elaborated on the “Other” value: “Because of the random groups, I met and talked with more MATS scholars than I otherwise would have. There are also a few scholars who are not so talkative on topics other than AI safety, so it was nice to speak to them during the AI strategy discussion groups.”
Networking Events
We believe that a large benefit of holding the Research Phase in Berkeley and the Extension Phase in London is the ease of connecting scholars to the researchers who work in these global AI safety hubs. To facilitate such connections, MATS organized a number of networking events:
Prior to our career fair, 23 scholars submitted a survey indicating which organizations they would most like to see at the event. Their responses form a snapshot of the current career interests of aspiring AI safety researchers.
To obtain a sense of the popularity of the organization categories, we show how many scholars, out of 23, voted for the average organization in each category:
This distribution is similar to the one we saw for last summer’s career fair, with the exception of the government organizations, which did not exist at the time.
Social Events
In addition to the networking socials, we held a number of social events, including outings for scholars from underrepresented backgrounds (younger, older, religious, women, people of color, and LGBTQ+). Multiple scholars took the initiative to organize social events, including music nights, movie nights, an origami social, DnD games, exercise outings, excursions into San Francisco, and a hike.
Community Health
Scholars had access to a Community Manager to discuss community health concerns, such as conflicts with other scholars or their mentors, and to provide emotional support and referrals to health resources. We believe that community health concerns like imposter syndrome and undiagnosed conditions like ADHD can detriment promising researchers entering AI safety. Furthermore, interpersonal conflicts, mental health concerns, and a lack of connection can inhibit research productivity by contributing to a negative work environment, detracting from the cognitive resources that scholars could allocate toward research and precluding fruitful collaborations. It is important for programs like MATS to provide support in these areas, while air-gapping evaluation and community health when appropriate to incentivize scholars to seek help when they need it without fear of adverse effects on themselves or others.
A small number of scholars met with the Community Manager frequently, while 67% of scholars met with the Community Manager just once.
Even scholars who do not seek out community health support benefit from the existence of this safety net (see Community Health below).
The Community Manager aims to equip scholars with the skills and resources to work productively and sustainably after they leave MATS. Scholars reported how the Community Manager helped them:
Some of the “Other” ways that Community Health helped scholars included:
Extension Phase (Apr 1 - Jul 19)
By the end of the main program, many scholars are looking for a structured way to continue their projects while they plan their transition into the next phase of their career. The extension phase allows scholars to pursue their research projects with gradually increasing autonomy from their mentors and MATS. The MATS Executive Team accepts scholars into the Extension Phase based on:
Funding from an outside organization, typically the LTFF or Open Philanthropy, is an important input to MATS’ evaluation process because it provides external evaluation of scholars’ research. Of the 50 scholars who applied, 72% were accepted into the Extension Phase, and 4% have pending applications. Of the 36 accepted scholars, 56% are completing the Extension at the London Initiative for Safe AI (LISA) office, 11% are continuing in Berkeley from FAR Labs, and the remainder are working remotely.
During the Extension Phase, we expect scholars to formalize their research projects into publications and plan future career directions. To support these efforts, we continue to offer Research Management (see above) and programming such as seminars, workshops, and networking events, especially for the scholars in the LISA office. FAR Labs offers its own programming, including a weekly seminar series. We tailor this programming to prepare scholars for the transition out of the MATS environment by encouraging them to develop longer term plans and make connections that advance those plans. We additionally offer scholars the support and resources to coordinate their own events and programming, giving them opportunities to take ownership of networking activities and further develop their independence. Concurrently, scholars continue to receive support from their mentors, though with less frequency than during the Research Phase.
Winter Program Evaluation
In this section, we lay out how scholars rated different elements of the program and how we evaluated our impact on scholars’ depth, breadth, and taste, among other metrics.
Evaluating Program Elements
The median scholar rated the following program elements as follows:
Overall Program
Scholars rated the Research Phase highly when considering their likelihood of recommending MATS to others (mean = 9.2/10).
In many industries, this type of question is commonly used to calculate a “net promoter score” (NPS). Based on our respondents, the NPS for MATS is +74, evidencing a very successful program.
We also asked mentors about their likelihood to recommend MATS.
The average mentor responded 8.2/10, and the NPS was +37. One mentor reported a likelihood to recommend of 2, which we suspect to be artificially low due to extenuating circumstances unrelated to the quality of the program.
Mentorship
Overall, scholars rated mentors highly (mean = 8.1/10).
For 38% of scholars, the mentorship they received was the most valuable component of MATS.
Note that 15/61 respondents did not select any program element as the “Most valuable part of MATS.” Here are some representative comments from scholars in each of these categories:
Among scholars for whom mentorship was not the most valuable component of MATS, 50% said that the cohort of peers was the most valuable component.
Research Management
Overall Rating by Scholars
Scholars rated Research Management highly when considering their likelihood of recommending it to future scholars.
The average likelihood to recommend among scholars was 7.9/10, and the NPS was +23.
We asked scholars how RM contributed to the value of MATS:
Scholars elaborated on their experiences with Research Management:
Overall Rating by Mentors
We asked mentors about their likelihood to recommend RM, and the average mentor responded 7.7/10; the NPS was +7.0.
We also asked mentors to rate the support they received from their RM, where
The average response to this question was 7.3/10.
We asked mentors, “Would you want to continue working with your RM in the extension phase, and/or future cohorts?” All respondents said “Yes, same RM”, except for one mentor who said “Yes, different RM.” Their RM is no longer in this role, and this mentor followed up to say “I got the impression that different RMs had quite different working styles. Would be keen to try working with someone else to see what type of RM works best for me.” Some mentors who expressed interest in continuing with their RM from the winter explained their reasoning. One said “Experience was good overall. It's nice to have updates from someone else so I have a check if there's anything [my scholar] doesn't say directly to me, but that I should know.”
One mentor offered a testimonial about their experiences with Research Management:
We also asked mentors who did not have RM if they thought they would have benefited from it. One mentor responded “My a priori guess is that RM is pretty great. I expect that RMs are better at many of the things they can help scholars with than I would be (for example, productivity debugging, discussing personal conflicts, potentially also helping scholars generate next steps).” A different mentor wrote, “I'm not sure what it entails as a mentor. It may have been useful for my scholars -- I have found a research manager useful in the past.”
Finally, we asked mentors how much RM improved their scholar meetings. Some mentors reported a modest improvement, but others benefited significantly.
Mentors elaborated on these improvements:
Vs Mentor Counterfactual
Recall that Research Management aims to take on some responsibilities that mentors often bear by default. To evaluate Research Management’s impact, we can compare it to the counterfactual in which scholars requested support directly from their mentors. We asked two questions:
The first question identifies the value that could have been recovered from mentors, conditional on mentor willingness; the second question elicits mentor willingness. The following heatmap displays the joint distribution of responses.
Cells in the top rows and the left columns represent scholars for whom Research Management provided an improvement over the counterfactual: their mentors could not or would not have replaced Research Management. The cells in the bottom-right represent scholars for whom Research Management detracted value: their mentors would have stepped in to provide Research Management functions. 7% of scholars were in this second category: they thought their mentors probably or certainly would have provided superior support.
One scholar elaborated on a benefit unique to Research Managers: “I think it is very valuable to have an orthogonal perspective alongside the research process that is *not* your mentor. I generally think the structure that was in place was overall helpful for accountability and sharpening the research process in general.”
Even if mentors were willing and able to perform Research Management roles, there would still be a case for dedicated Research Managers:
Scholars are sometimes disincentivized from seeking support from mentors. Because mentors evaluate their mentees for progression within MATS (and possibly to external grantmakers), scholars can feel disincentivized from revealing problems that they are experiencing.
We asked mentors the same pair of questions. All respondents agreed that they could provide “some of the value from RM.” 57% said they would “probably not” have spent the time; 36% said “probably yes”, and the remaining 7% said “almost certainly yes.”
Grant Equivalent Valuation
We asked scholars, “Assuming you got a grant instead of receiving 1-1 Research Management meetings during MATS, how much would you have needed to receive in order to be indifferent between the grant and Research Management?[8] Please answer ex post, i.e. knowing what you know now. If you respond with some number X, that means you value these two the same:
- a grant of $X
- all of the 1-1 Research Management meetings you've had during MATS, collectively.”
The average response was $1711, the median response was $1000, and the sum was $95,810.
We asked mentors the same question. The average response was $5900, the median was $3000, and the sum was $88,000. Mentors expressed higher valuations than scholars for Research Management, perhaps because mentors have higher-paying jobs than scholars, many of whom are students, or mentors value their productivity more highly than scholars. As shown below, Research Management did not create more productive hours for mentors than scholars, on average.
Accomplishments and Productive Hours
Finally, we asked scholars and mentors two (functionally similar) questions about the value of Research Management.
The first question was: “By what percent would you estimate Research Management changed the amount you accomplished during MATS? An answer of X% means you accomplished X% more than you would have otherwise.” The average increase in accomplishments was 14%, and the median was 10%.
We asked mentors the same question. Their average increase in accomplishments was 12%, and the median was 10%.
The second question we asked scholars was: “How many more productive hours in the last 10 weeks would you estimate you had because of your Research Management meetings? For reference, MATS research phase was 10 weeks long. If you estimate you got X more productive hours per week on average, then you should respond 10*X. If you only got a 1-time productivity boost of Y hours, you should respond Y.”
The average increase in productive hours was 21 hours, the median was 10 hours, and the sum was 1200 hours.
We also asked mentors this question. The average increase was 8.9 hours, the median was 4.0 hours, and the sum was 130 hours. Productive hours were not the only benefit that Research Management provided, as evidenced by scholars and mentors who reported 0 increase in productive hours but a nonzero grant equivalent. But if we look at the grant equivalents for mentors and scholars who reported an increase in productive hours, the average mentor valued their time at $690/h, and scholars value their time at $160/h.
Improvements
We asked mentors how we could improve Research Management for future programs.
One mentor elaborated on the “other” ways RM could improve, noting, “My scholar had various questions about the extension application that the research manager was not able to answer and I had to reach out directly to people in charge of the extension evaluation process.” Another mentor wrote, “I wish my RM was more proactive in seeking mentor feedback on scholars.”
We asked mentors about the skills that RMs could develop to improve their RM abilities. 40% of mentors with RMs suggested that their RM could have more research experience.
We asked mentors, “Are you satisfied with the amount of time your RM spent on your stream? Would you have preferred more, less, or the same amount of RM time?” All respondents said “I am satisfied with the amount of time my RM spent on my stream”, except one, who said they “would have preferred my RM spent more time on my stream.”
Seminars & Workshops
While seminars and workshops were optional, MATS encouraged scholars to attend them. By exposing scholars to experienced researchers and novel agendas, seminars remain a pillar of scholar development.
In optional surveys, scholars rated seminars 6.8/10, on average, where 1/10 represented “Not worth attending,” and 10/10 represented the high bar “It significantly updated your research interests or priorities." These surveys also solicited scholars’ expectations about the value of the events. 33% of ratings exceeded expectations; 23% of ratings were worse than expected. A seminar that was “about as valuable as expected,” received an average rating of 6.8/10.
Workshops were a relatively minor program element—MATS held five workshops on topics other than Research Milestones—so it is unsurprising that they contributed less value than other program elements.
Lighthaven Office
We were interested to see how scholars would rate Lighthaven because the campus differed from our previous offices, as explained above.
Comparing this result against alumni surveys, we see that Lighthaven was not a noticeably more important program element than office spaces in earlier MATS programs.
Note that this question asks about the value of the office relative to other program elements, and we believe other program elements have improved over time, so this question may reflect an improvement in the value of the office, in absolute terms. These responses should also be taken lightly because, for many scholars, this was their first experience working in any office, so their answers may not accurately reflect the quality of the office.
At the end of the program, scholars suggested some minor improvements to the facilities. Some also provided positive feedback:
Mentors gave feedback as well:
Before the program, we tried to identify the space needs of all mentors; if the first two mentors above had brought their concerns to us during the program, we would have worked to provide private meeting areas for them.
Though we took steps to separate office and living spaces, we were concerned that the thin boundary between professional and personal spaces might lead to an unhealthy work-life balance for scholars. In the words of the previous scholar, we were worried the experience would “be a little bit much.” This proved to not be a significant problem. During the first week of the program, we polled scholars about their concerns, and the most notable change from our previous program was fewer scholars indicating a concern with work-life balance. After the program, we surveyed scholars again: 44 said the “balance felt appropriate,” 8 indicated “too much work,” and 4 said they “didn’t work enough.”
Because scholars were living at Lighthaven, and it had previously been a hotel, we were concerned that the atmosphere might become too informal for a professional program like ours. To investigate this possibility, we asked scholars about the “cozy”/professional balance. Among in-person scholars, 47 said “the balance was just right,” 8 said they “would have preferred a more professional office environment,” and 1 said they “Would have preferred more ‘cozy vibes.’” Based on this feedback, we are satisfied with the level of professionalism that Lighthaven offered.
Strategy Discussions
Scholars had mixed experiences with the Strategy Discussion groups.
Scholars elaborated on the limitations of our discussion format:
An AI safety curriculum remains an important lever by which MATS can improve our scholars’ breadth of knowledge about the AI safety field, but these results have underscored some shortcomings of our approach during the past program. In our next program, we will hold Discussion Groups, but we will update the readings, format, and timeline in response to scholar feedback, and we will offer discussions on an opt-in basis, to ensure they do not absorb the time of scholars who are unlikely to benefit from them.
Networking Events
Facilitating connections to the wider Berkeley AI safety research community was an important way MATS provided value to scholars. We asked scholars about the value of the connections they made, clarifying, “This includes connecting with non-MATS members of the alignment community, e.g., at MATS networking events.”
The most highly-rated networking event of the program was the EA Global: Bay Area conference, which many scholars chose to attend. The cause of dissatisfaction with the FAR Labs Lunch, and to some extent the Constellation Dinner, was the high ratio of MATS scholars to office members. The Constellation Dinner was rated about 1 point higher than the same event in the previous program; we think the increase was due to hosting the event at Constellation rather than our office, which helped with the ratio of MATS scholars to office members. We also think the presence of Astra participants and Visiting Researchers may have improved scholars’ experiences at the dinner.
This figure excludes networking socials, the Symposium, and intra-cohort networking events.
To measure the success of our networking events, we asked scholars two questions at the beginning and end of the program about their professional connections:
Responding to both questions, scholars reported an increase in professional connections during MATS.
The median change in professional connections was +5.0, and the median change in potential collaborators was +5.0. As in our previous program, decreases are most likely explained by some day-to-day variance in scholars’ judgments, as they did not have access to their previous responses. These measures also pick up on connections made to other scholars, in addition to researchers outside of MATS, but we believe networking events contributed because remote scholars reported smaller increases.
Community Health
As expected, many scholars did not use Community Health support, but a minority of scholars benefited substantially.
To investigate these benefits, we asked scholars the same question about productive hours we used to evaluate Scholar Support, along with a question about their well-being.
The median scholar gained 0 productive hours, but the sum was 170 hours.
The median scholar’s well-being increased by 5.0% due to Community Health support. Scholars elaborated on the ways that Community Health improved their quality of life:
As in last summer’s program, many scholars who did not meet frequently with the Community Manager reported benefitting indirectly from a positive atmosphere and the knowledge of an emotional safety net.
Compared to other program elements, the benefits of Community Health were concentrated among fewer scholars, but this small segment of scholars benefited greatly. We continue to believe that Community Health is important and neglected based on its benefits to these scholars and the diffuse benefits it provides to the MATS community.
Evaluating Key Scholar Outcomes
Scholar Self-Reports
To measure scholars’ improvements in the depth, breadth, and taste aspects of conducting research, including the quality of their theories of change, scholars assessed themselves on these dimensions at the beginning and end of the program. The specific questions we asked were:
Depth: How strong are your technical skills as relevant to your chosen research direction? e.g. if the research is pure theory, how strong is your math? If the research is mechanistic interpretability, how well can you use TransformerLens and other tools?
Breadth: How do you rate your understanding of the agendas of major alignment organizations?
Research Taste: How well can you independently iterate on research direction? e.g. design and update research proposals, notice confusion, course-correct from unproductive directions
Theory of Change: How strong are your mental models of AI risk factors and your ability to make impactful plans based on these models? Do you have a mental model for how AI development will happen that you think captures many of the relevant dynamics? Do you have a theory of change for why your chosen research direction will make beneficial AI outcomes more likely?
The average change in depth was +1.53/10, and the average change in breadth was +1.93/10.
The decreases could be explained by calibration variance, as with professional connections above, or by scholars realizing their previous understandings were not as comprehensive as they had thought.
The average change in research taste was +1.35/10, and the average change in theory of change was +1.25/10.
Mentor Evaluations
Halfway through the program, we asked mentors to evaluate their scholars on these same four dimensions. Average depth was 7.4/10, average breadth was 6.9/10, average taste was 7.2/10, and average theory of change was 7.0/10.
We can compare mentors ratings to their scholars’ self reports. Because mentors evaluated scholars halfway through the program, we use the average of scholars’ self-assessments from the beginning and end of the program.
If mentors and scholars agreed on the abilities of scholars, the data would be concentrated on the grey dashed line. Instead, scholars and mentors diverge in their assessments of breadth and depth. The greater concentration of data below the calibration line indicates that mentors tend to rate scholars higher than scholars rate themselves.
We asked mentors to assess the career outcomes that “you find it likely that your scholar could achieve in the next year if they wanted to.” According to mentors, of the 56 scholars who received an evaluation, 43 could achieve a “First-author paper at top conference,” 23 could receive a “Job offer from AI lab safety team,” and 9 could “Found a new AI safety research org.”
Finally, mentors assessed their overall enthusiasm for their scholars’ continued research: “Taking the above into account, how strongly do you believe this scholar should receive further support from MATS/grantmakers to continue AI safety research?
The mean of this distribution was 8.1/10, demonstrating mentors’ enthusiasm for their scholars to continue their work.
Milestone Assignments
Research Plans
Per the rubric, MATS alumni graded Research Plans on three components:
The median scores on the three respective sections were 15/20 points, 32/40 points, and 32/40 points. The median overall score was 76/100 points, showing that most scholars can effectively formulate and present a research plan.
Symposium Presentations
Over the two days of the Symposium, scholars presented research on a range of agendas. The entire first day was dedicated to interpretability, which was heavily represented among the talks.
Grouped into more coarse categories:
As detailed in the rubric, symposium presentations were graded on three components:
The average scholar’s overall score was an excellent 86/100 points. Unlike Research Plans, which were graded by contracted MATS alumni, evaluations of Symposium Presentations were submitted by Symposium attendees, including scholars, alumni, members of MATS team, and members of the extended Bay Area AI safety research community. The talk with the fewest evaluations received 4; the average talk received 15 evaluations.
Funding and Other Career Obstacles
At the beginning and end of the program, scholars answered “What do you feel are the obstacles between you and a successful AI safety research career?” In aggregate, MATS reduced almost all barriers that scholars faced.
The “Other” obstacles that scholars faced at the end of the program included:
These are the obstacles that scholars reported at the end of the program:
Similarly to last summer’s program, publication record was the career obstacle faced by more scholars than any other. While funding was the second-highest obstacle, we can see that challenges with writing grant proposals decreased dramatically, making it the least important obstacle for alumni leaving our Winter program, and indicating that grant writing is not a primary obstacle for obtaining funding. We attribute this improvement to the updated Research Plan milestone, designed around the LTFF grant application, and associated theory of change and grant application workshops. Additionally, the Strategy Discussion Groups might have helped scholars write theories of change.
Unlike last summer’s program, the number of scholars facing publication record as an obstacle decreased, instead of increasing. This suggests that scholars in the most recent program focused more deliberately on a publishable project instead of pivoting repeatedly or working on unpublishable work, which is consistent with our anecdotal experience. Similarly, software engineering experience decreased as an obstacle during the past program but increased last summer, suggesting that scholars found more opportunities to develop their coding abilities or realized that generic programming skills are less of an obstacle than they had previously believed. The magnitude of the changes in software engineering in the most recent program and last Summer was small enough that the difference could easily be explained by randomness in scholar selection.
Funding became a larger barrier during the program, as opposed to last Summer, when it decreased. One difference that could be responsible is fewer mentors who hired their scholars immediately following the program. In general, we are not surprised to see funding increase as a barrier: at the start of the program, scholars have just received a grant for participating in MATS, which lowers this barrier, or at least makes it less salient.
Despite funding obstacles, fewer scholars reported grant writing as a barrier. The increase in grant-writing ability is apparent from responses to a question about scholars’ confidence in submitting a grant proposal. We asked, “How confident would you feel about submitting a grant proposal right now? Confidence levels could come from familiarity with grant processes, criteria used by grantmakers, experience writing grants, and the strength of a possible proposal.” At the start of the program, 69% of scholars felt “Unconfident” or “Very unconfident” in their grant-writing abilities, but 82% of scholars felt “Confident” or “Very confident” by the end of the program. Indeed, of the 42 scholars who applied to the Long-Term Future Fund for the MATS Extension (76% of the cohort), 30 were funded (acceptance rate = 71%). In addition, 5 scholars already had grant funding they could use for the extension program before they came to MATS.
Evaluating Key Mentor Outcomes
Self-Reported Benefits
We asked mentors about their motivations for mentoring: “Why did you want to mentor for MATS? What did you hope to get out of mentoring?” We also asked them about the benefits they received from mentoring: “What benefits did you, in fact, get out of mentoring for MATS?"
In general, there was a tight relationship between expected and actual benefits. Slightly more mentors than expected found that they helped new researchers through MATS and gained mentorship experience. The largest exception was that many fewer mentors reported that MATS helped advance their specific agenda than expected. We believe that this result was primarily caused by high initial expectations from first-time mentors that failed to match what was possible in the 10-week program.
Biggest Impact
We asked mentors, “What is the biggest counterfactual impact that happened as a result of you mentoring at MATS? E.g. some percentage increased productivity on your preferred research agendas, counterfactual publication(s), new hires…” Mentors gave varied answers:
Testimonials
Some mentors offered testimonials about the value of MATS.
– Adrià Garriga-Alonso
– Asa Cooper-Strickland
– Francis Rhys Ward
– Jérémy Scheurer
– Jesse Hoogland
– Stephen Casper
– Vanessa Kosoy
Improved Mentor Abilities
We asked mentors to evaluate the improvement to their mentorship abilities that they received from MATS, compared to a counterfactual in which they did not mentor during the winter program.
The average mentor improved their mentorship abilities by 18%.
Lessons and Changes for Future Programs
Advisory Board for Mentorship Selection
For future programs, we intend to establish an Advisory Board, consisting of senior figures in AI safety who possess in-depth knowledge of the research landscape and expert judgment on prioritizing AI safety research agendas. The board’s input will inform our mentor selection process, improving our decisions and providing accountability to a wider set of stakeholders.
Fewer Mechanistic Interpretability Mentors
While mechanistic interpretability remains a strong interest among would-be scholars and mentors, we believe this agenda was relatively over-represented among the research interests of the Winter cohort, featuring in 37% of scholar talks. During mentor selection and scholar allocation for our next program, we intend to reduce the mechanistic interpretability proportion of the MATS “portfolio” and increase the proportion of evaluations, scalable oversight, and control research.
More AI Governance Mentors
A growing consensus holds that governance and policy stand to make important contributions to reducing existential risks from AI. Occasionally, MATS scholars have conducted research for a policymaking audience, such as demonstrations of dangerous model capabilities, but MATS has historically focused on technical research to the exclusion of governance. At present, we believe that AI governance would benefit from further research mentorship programs, and MATS is well-positioned to fill this gap. Technical AI governance is a particularly natural fit for us, but we also have the experience and infrastructure to accommodate more traditional forms of governance research, where our efforts would complement preexisting AI governance fellowship programs. Indeed, during the Summer 2024 Program, MATS will have at least two technical governance mentors. Results from the Summer 2024 Program will influence whether MATS continues to pursue technical governance as part of the MATS mentor portfolio.
Pre-Screening with CodeSignal
We have secured sufficient CodeSignal tests for the next program that we can pre-screen applicants to mentors who require engineering experience. Pre-screening will save these mentors valuable time, which they could spend more meticulously reviewing the applicants that pass the programming filter, thereby selecting better qualified scholars.
Research Manager Hiring
In order to meet scholars’ and mentors’ demonstrated needs, we currently anticipate hiring 3-4 additional Research Managers for the MATS Summer 2024 Program. Given the feedback from mentors on the skills they would most like to see more of in their Research Managers, prior research experience will be a key factor in our hiring decisions.
Modified Discussion Groups
We will continue to offer discussion groups focused on AI safety strategy, following a custom MATS curriculum. We think this approach has more potential to expand scholars’ breadth of knowledge about the field than the pre-program Training Phase and AISF curriculum we employed in previous programs. For our next program, we intend to improve on our curriculum, craft stronger guidance and instruction for our TAs, frontload more of the sessions, and require that scholars opt-in, rather than opt-out.
Acknowledgements
This report was produced by the ML Alignment & Theory Scholars Program. Rocket Drew was the primary contributor, Ryan Kidd managed and edited the project, and Laura Vaughan contributed writing. Additionally, Laura Vaughan, McKenna Fitzgerald, Christian Smith, Juan Gil, Henry Sleight, and Matthew Wearden edited particular sections. We thank Open Philanthropy, DALHAP Investments, and many Manifund donors, especially Manifund Regrantor Tristan Hume, without whose donations we would have been unable to run the Winter 2023-24 Program or retain team members essential to this report. We are also grateful to Lightcone Infrastructure and AI Safety Support for their commitment and support. Finally, thank you to the inimitable John Wentworth and David Lorell, who may not belong to “MAT” but certainly belong in our hearts.
To learn more about MATS, please visit our website. We are currently accepting donations for our upcoming programs via BERI and Manifund!
Some applicants applied to multiple mentors. This number includes scholars accepted to Neel Nanda’s Research Phase, rather than scholars accepted into Neel’s Training Phase.
Examples of selection questions:
What is your favorite definition/formalization of a stochastic hybrid system, and why? (Davidad)
Spend ~10 hours (for fairness, max 16) trying to make research progress on a small open problem in mechanistic interpretability, and show me what progress you’ve made. (Neel Nanda)
You have access to a trained model’s outputs in response to any input. You can provide an unlimited number of inputs and receive responses. You do not have access to gradient information. What can you find out about what this model has learned from its training data? How does this change if you have access to gradients of inputs w.r.t. outputs? (Jessica Rumbelow)
Neel’s scholars faced additional filters between the Training Phase and Research Phase.
In reality, our budget is not given exogenously. A lower marginal cost per scholar, for example, might encourage donations, resulting in a larger budget.
These numbers exclude 14 Auditors who participated in the Training Phase knowing they would not be able to continue to the Research Phase. Auditors were allowed to complete the Research Sprint, but to our knowledge, none did.
Jay Bailey, a trainee from Winter 2022-23, attests,
Itamar Pres, a trainee from Summer 2023, corroborates,
Thank you to John Wentworth for proposing this idea!
This survey question and the following one come from Lynette Bye’s 2020 review of her coaching impact.