This is a linkpost for https://www.youtube.com/playlist?list=PLJ9u8EFfTLel8wpw4mZClAgVufYx9aAlF
New Comment
I increased the volume and did noise suppression on them:
https://www.youtube.com/playlist?list=PLJ9u8EFfTLel8wpw4mZClAgVufYx9aAlF
Enjoy :)
One thing I notice I'm confused about: What causes problems to be factorizable?
To me, there seems to be several different ways you can factor a problem:
-
Symmetry exploitation. Example: Binary search is a good example here. I have an upper and lower bound for a value, and I want to find the value. I only evaluate whether points between my upper and lower bounds are less than or greater than the value I want to find, and I can ignore all other points because if I have an upper bound, everything greater than that is going to also be greater than my target value.
-
Bottleneck/constraint enumeration. Example: The maze example from your video.
-
Bottleneck/constraint relaxation. Example: In maze solving, you can ignore the constraining walls in order to decide on heuristics in your search algorithm for which actions to evaluate the feasibility of next. Dual problems in convex optimization can also be seen as examples of this.
-
Inferences between local and global structures. Example: If we have a smooth objective, we can do gradient descent, and be confident we'll at least get a pretty good value by the end.
-
Structure exploitation. Example: Lots of dynamic programming stuff I'm given to understand. Potentially just a collection of heuristics for maps from problem properties to solution symmetries induced by those problems.
-
Problem reformulation. Example: If you have a non-convex optimization problem, you can sometimes find an equivalent convex optimization problem if you do the right sorts of manipulations.
1, 4, and 5 seem similar because they're all creating bounds on where the optimal solution could be according to misleadingly few observations. Though also they don't have to be targeted at the bounds of the optimal solution. You can find symmetries in your constraints.
2 and 3 seem similar because they both have to do with bottlenecks.
6 is only doable when the problem reformulation step is factorizable (or else the operations you can do for the reformulation are small, which I guess potentially they can be even when your problem is very big).
These seem like they potentially have some common root which causes them all.
The obvious explanation to me mostly lies in number 5. The problem you have is often generated by the universe. Or at least, the solution space of your problem is a state space of the universe. And because our universe has locality and symmetry, the space of our problem and solution space also has symmetry and locality elements, which can often be exploited.
-
Symmetry comes directly.
-
Bottleneck/constraint enumeration. Due to locality, there are usually fairly few bottlenecks you can target independently.
-
Bottleneck/constraint relaxation. In the maze example, we can ignore the walls to construct heuristics both for the enumeration of constraints, and to decide on next actions. For deciding on next actions, if we had some insane
geometryedit: topology with no kinds of nice symmetries that our [edit]: spacial topologies have (I'm picturing in my head a random assortment of pockmarked [edit:] branching topological holes throughout the maze), then shortest-path distances are difficult to calculate, and our heuristic takes the form of a potentially arbitrarily difficult shortest-path optimization problem (I don't actually know if this is actually arbitrarily difficult, though I'm pretty sure it is, since you should be able to encode an arbitrary search problem into the shortest path in the topology). So I claim the usefulness of this comes from symmetries. -
Inferences between local and global structures. Yeah, this is kinda just what "symmetry" means. Also potentially locality too, since lots of things are continuous in our universe, with derivatives easy to calculate, and so we can use SGD a bunch for solving stuff.
-
Structure exploitation. The inspiration for this hypothesis.
-
Problem reformulation. This one still feels kinda like a mystery. If I had to hazard a guess, this is because if we're given a problem, the problem fundamentally has symmetry and locality properties for the reason given in the previous (non-enumerated) paragraph. And so if we got a problem, and it seems hard, in a sense, this is because there's been some kind of (probably random) processing done to it so that these properties take more effort to figure out. But that processing likely wasn't all that computationally intense, and likely wasn't generated by a particularly computationally intense process, which itself wasn't generated by a computationally intense process, etc. etc. and so undoing the process is doable.
Board is sometimes hard to see in the videos, so here are some photos.
Proto-lecture 1:
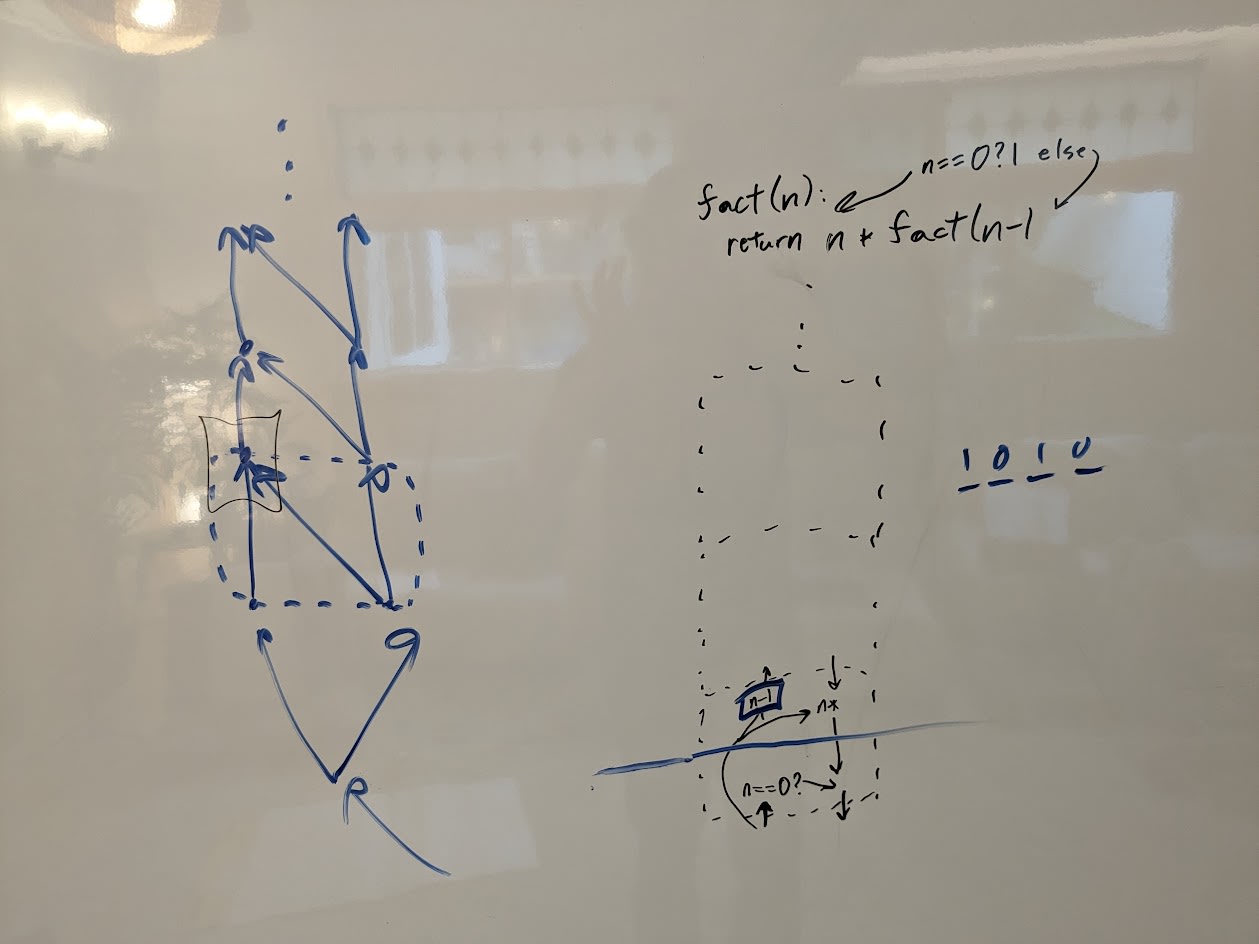
Proto-lecture 2 (and beginning of 3):
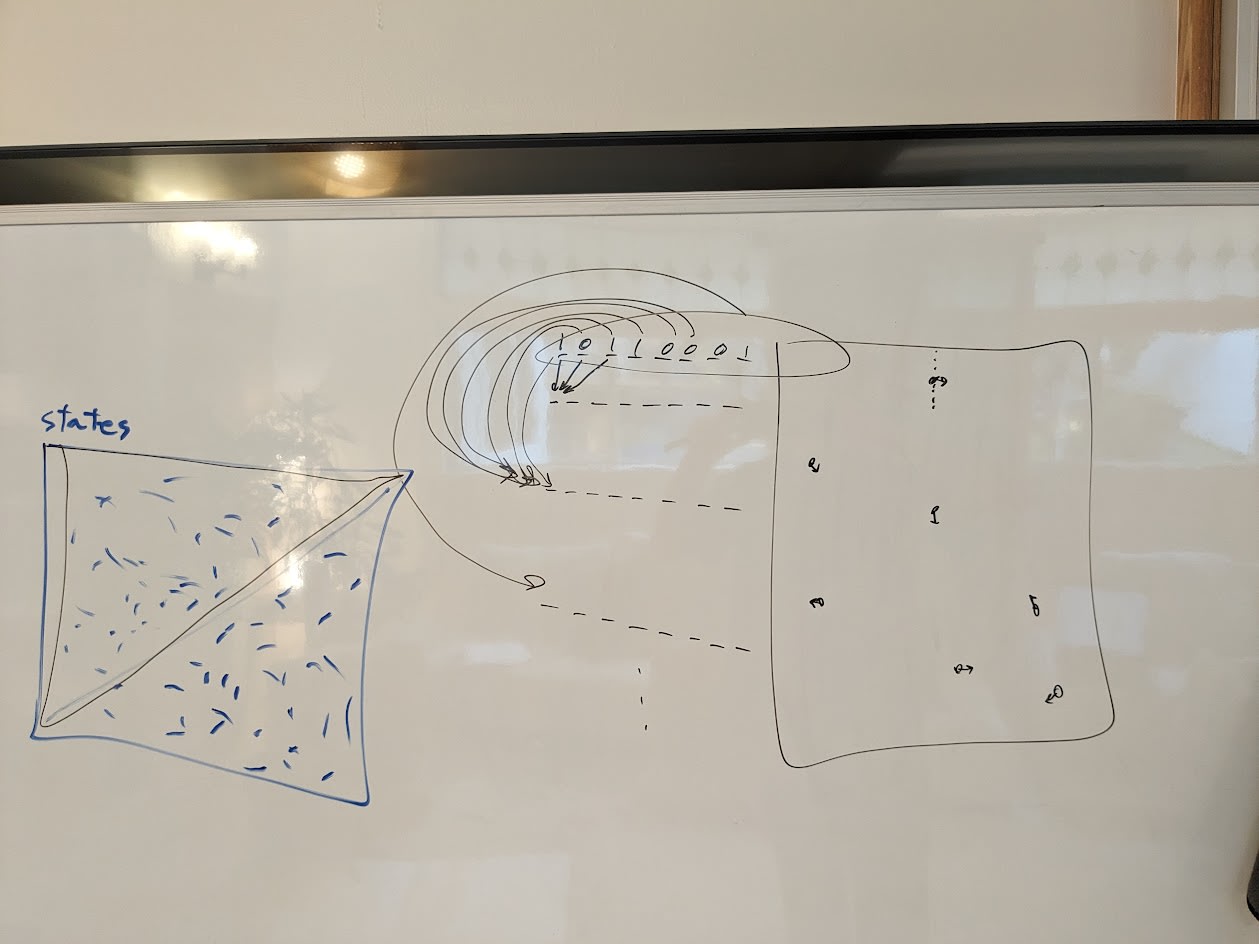
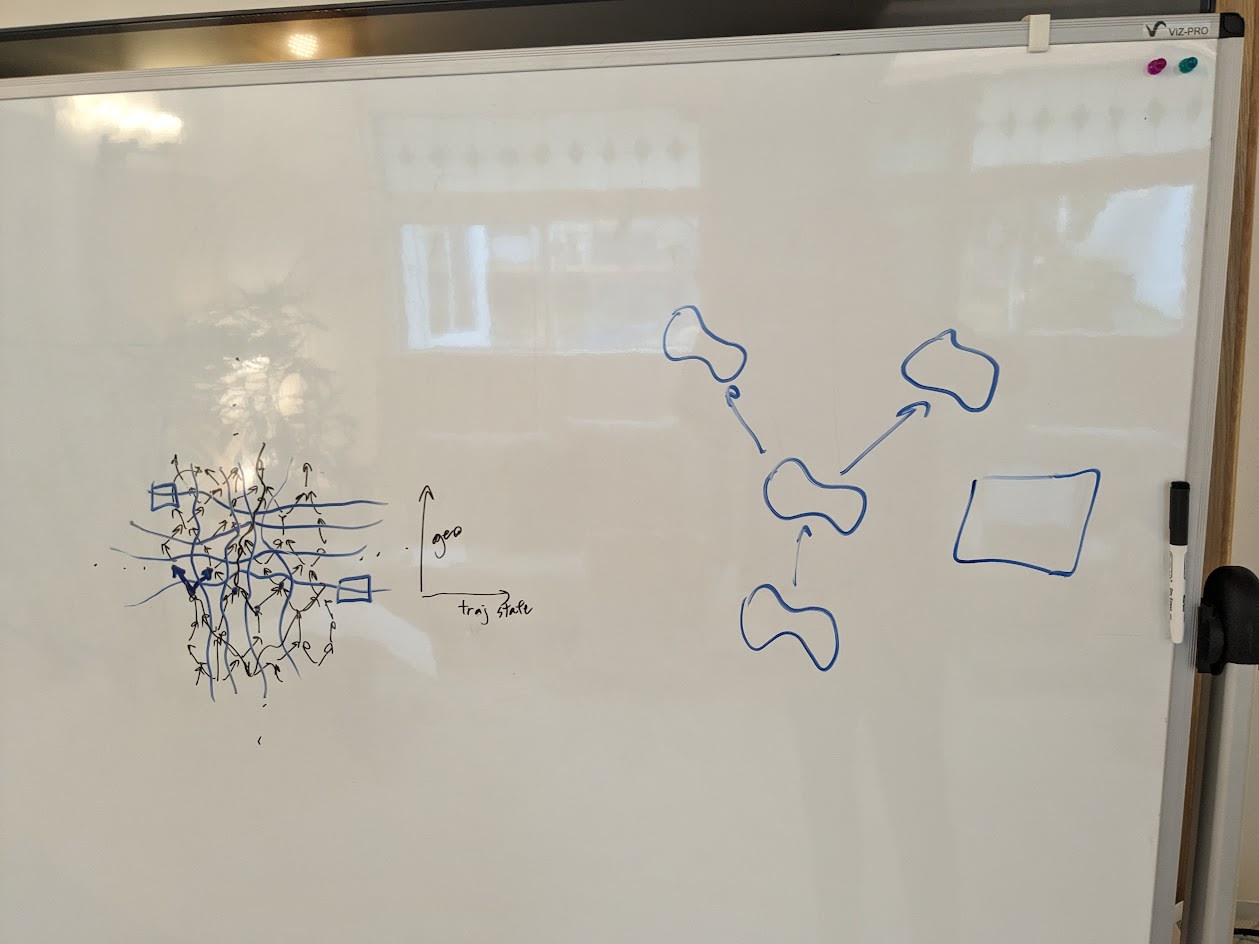
Proto-lecture 3 (and beginning of 4):
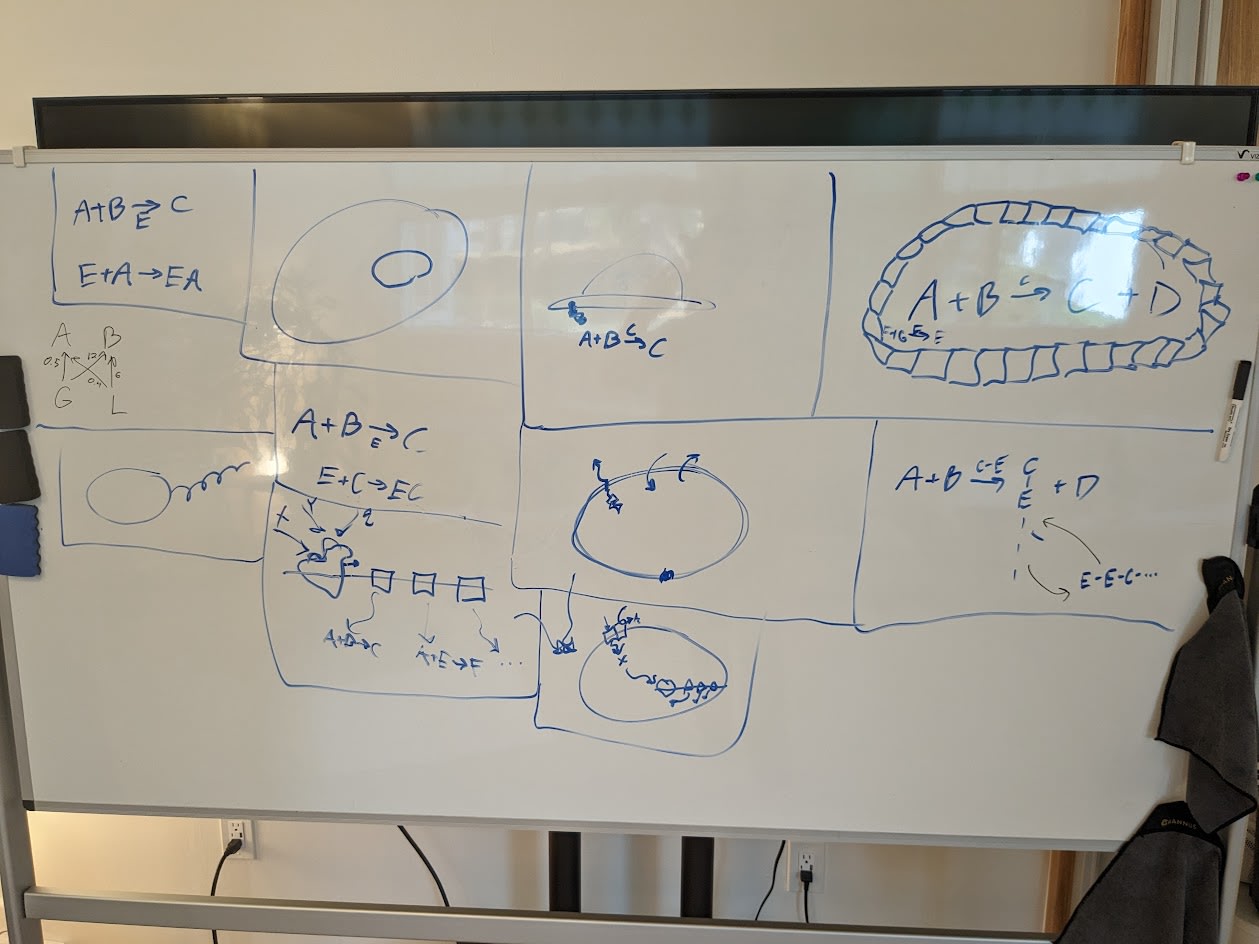
Proto-lecture 4:
Proto-lectures 5 & 6:
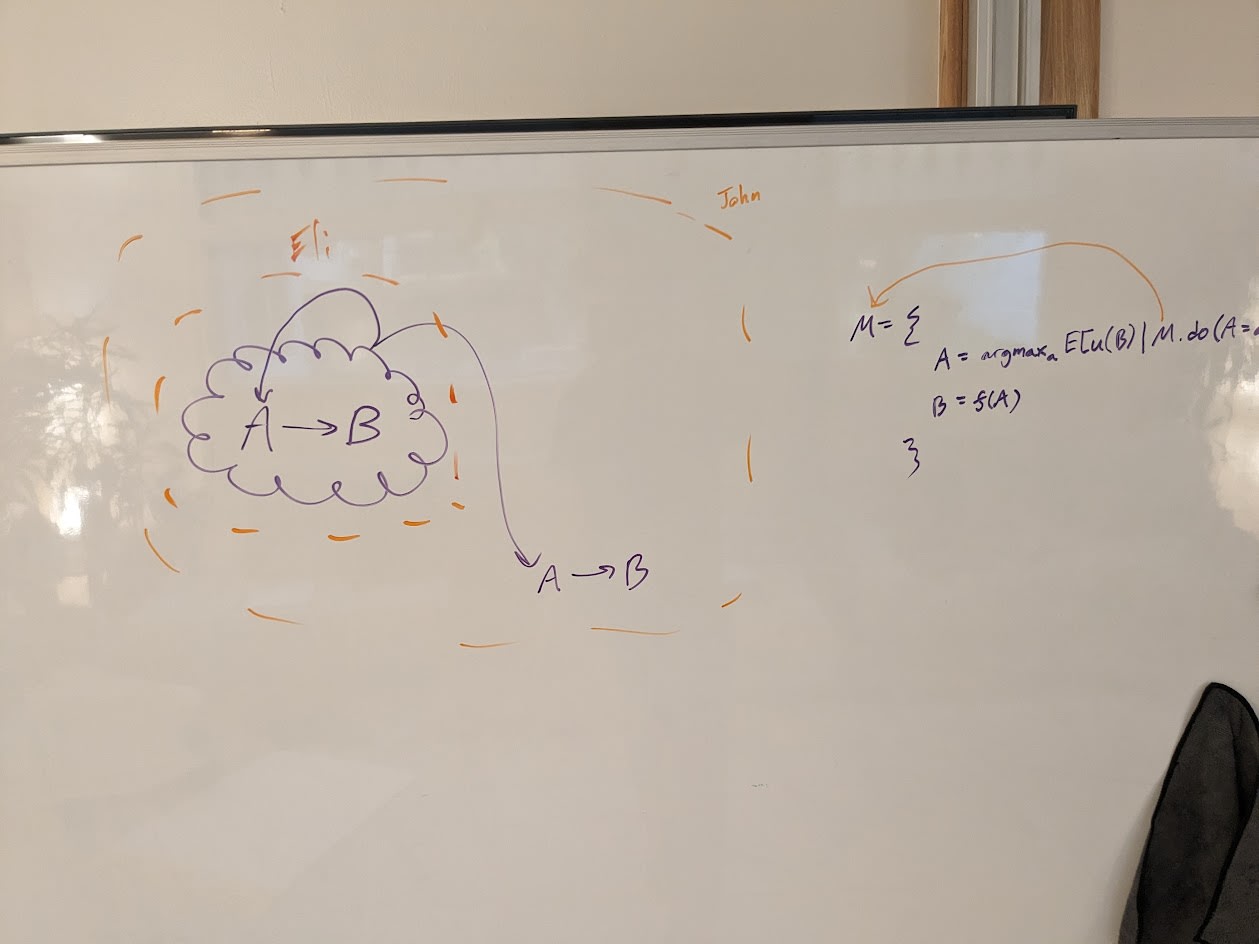
- A program-like data structure is natural for representing locality + symmetry
Didn't quite get this from the lecture. For one, every rookie programmer has probably experienced that programs can work in ways with mysterious interactions that sure don't seem very local... but maybe in your case you'd still say that at the end of the day it would all just be unpackable into a graph of function calls, respecting locality at each step?
Question: what's an example of a data structure very similar to program-like ones, while failing to respect locality + symmetry?
maybe in your case you'd still say that at the end of the day it would all just be unpackable into a graph of function calls, respecting locality at each step?
We typically implement highly nonlocal functions using very local computations. For instance, a hash function is typically very nonlocal with respect to its input and output bits - everything effects everything else. But the "internals" of that function represent it by repeatedly using symmetric, local parts (e.g. logic gates etc).
It's usually computations (including e.g. the computation performed by a physical chunk of spacetime) which are local + symmetric. The I/O behavior of those computations (once we identify part of the computation as "input" and another as "output") is not necessarily local + symmetric.
Question: what's an example of a data structure very similar to program-like ones, while failing to respect locality + symmetry?
First, I'll answer a slightly different question: what's an example of a computation which doesn't respect locality + symmetry? For that, imagine a gridworld in which the state at each gridpoint-time is some big function of the state of all the other gridpoint-times before it chronologically. That's nonlocal, and if the functions differ at each gridpoint-time then it's also nonsymmetric. Space and time wouldn't have much meaning at all to beings living in that world (assuming that it's even possible for minds to live in that world, which I'd weakly guess it isn't).
Now back to data structures. Even to represent that nonlocal, nonsymmetric world we'd probably still use a data structure which depends on locality + symmetry internally; that's built in to our intuitive notion of a "data structure" to a large extent. (For instance, a data structure is supposed to interact with the rest of a program via a defined API; that implies some degree of locality, since the data structures internals mostly don't directly interact with all the stuff going on outside.) Data structures can generally be represented as programs; specific data structures add additional structure on top of a generic program. That's part of why I called programs a "natural" representation for locality + symmetry: roughly speaking, they're the "most general"/"least constrained" data structure for representing locality + symmetry, while other data structures add additional structure/constraints.
and use it!!
note: if you plug it in to your computer, your computer may automatically try use it for audio output too for some reason. Remember this if you plug it in and realize you can't hear anything.
Also, if that happens, when you change the audio output to fix it, make sure that you don't also change the audio input and forgo the microphone. (If you're on a mac, hit the volume button in the menu bar while holding Alt to manually select the audio input separate from the output.)
Thanks for making this!
I'm wondering if you've spent time engaging with any of Michael Levin's work (here's a presentation he gave for the PIBBS 2022 speaker series)? He often talks about intelligence at varying scales/levels of abstractions composing and optimizing in different spaces. He says things like "there is no hard/magic dividing line between when something is intelligent or not,". I think you might find his thinking on the subject valuable.
You might also find Designing Ecosystems of Intelligence from First Principles and The Markov blankets of life: autonomy, active inference and the free energy principle + the sources they draw from relevant.
You know the "NAND to Tetris" book/course, where one builds up the whole stack of a computer from low-level building blocks? Imagine if you had that, but rather than going from logic gates, through CPUs and compilers, to a game, you instead start from physics, go through biology and evolution, to human-like minds.
The Atoms to Agents Proto-Lectures are not that. They don't even quite aspire to that. But they aspire to one day aspire to that.
Basically, I sat down with Eli Tyre and spent a day walking through my current best understanding/guesses about the whole agency "stack", both how it works and how it evolved. The result is unpolished, full of guesswork, poorly executed (on my part), and has lots of big holes. But it's also IMO full of interesting models, cool phenomena, and a huge range of material which one rarely sees together. Lots of it is probably wrong, but wrong in ways that illuminate what answers would even look like.
The whole set of proto-lectures is on youtube here; total runtime is about 6 hours, broken across six videos. Below is a rough outline of topics. [EDIT: ATheCoder cleaned up the audio and posted now-better videos here; I've also updated the link at the top of this post to point there. Thankyou!]
Meta Commentary
Please feel free to play with these videos. I put zero effort into editing; if you want to clean the videos up and re-post them, go for it. (Note that I posted photos of the board in a comment below.)
Also, I strongly encourage people to make their own "Atoms to Agents" walkthroughs, based on their own models/understanding. It's a great exercise, and I'd love it if this were a whole genre.
This format started at a Topos-hosted retreat back in January. Eliana was posing questions about how the heck minds evolved from scratch, and it turned into a three-hour long conversation with Eliana, myself, Davidad, Vivek, Ramana, and Alexander G-O working our way through the stack. Highlight of the whole retreat. I tried a mini-version with Alex Turner a few months later, and then recorded these videos recently with Eli. The most fun version looks less like a lecture and more like a stream of questions from someone who's curious and digs in whenever hands are waved. (Eli did a decent job of this, but also I was steering a lot to cover particular topics; the goals of a lecture series are less fun than a freewheeling stream of questions.)