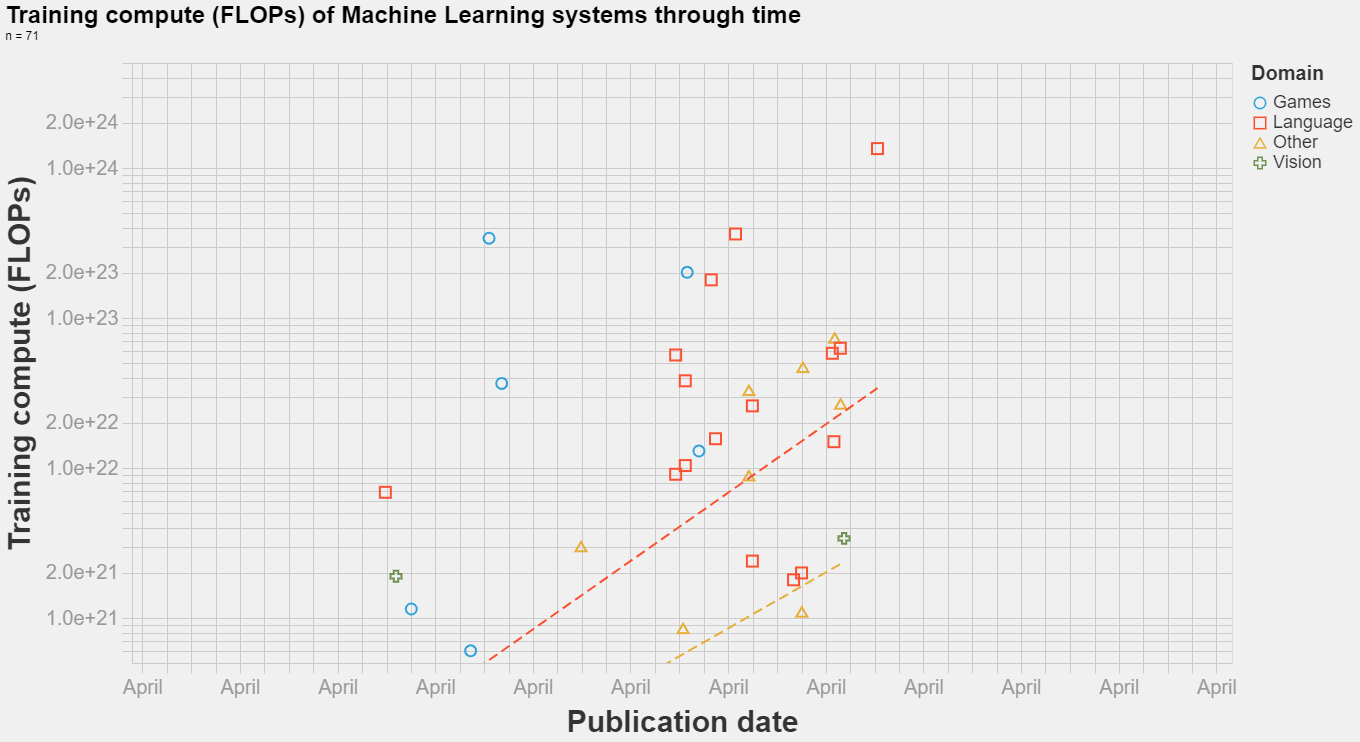
In addition to reporting aggregate metrics on benchmark tasks, we also qualitatively analyzed model outputs and have intriguing findings (Figure 4). We observed that the model can infer basic mathematical operations from context (sample 1), even when the symbols are badly obfuscated (sample 2). While far from claiming numeracy, the model seems to go beyond only memorization for arithmetic.
We also show samples (the last row in Figure 4) from the HANS task where we posed the task containing simple syntactic structures as a question and prompted the model for an answer. Despite the structures being simple, existing natural language inference (NLI) models often have a hard time with such inputs. Fine-tuned models often pick up spurious associations between certain syntactic structures and entailment relations from systemic biases in NLI datasets. MT-NLG performs competitively in such cases without finetuning.
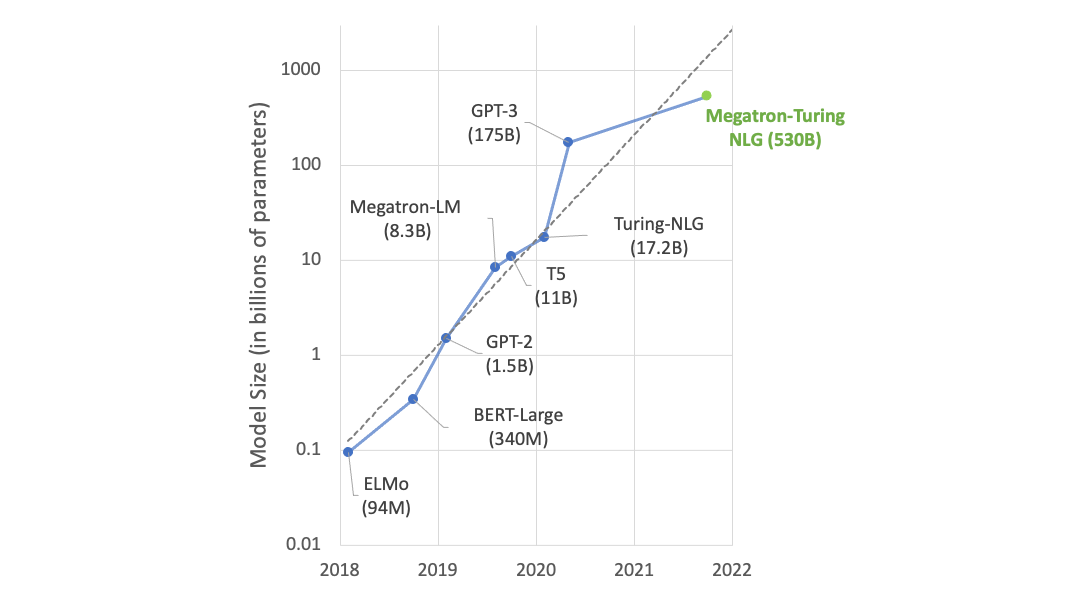
Seems like next big transformer model is here. No way to test it out yet, but scaling seems to continue, see quote.
It is not mixture of experts, so parameters mean something as compared to WuDao (also it beats GPT-3 on PiQA and LAMBADA).
How big of a deal is that?
I should clarify that we aren't data-limited in the sense of large natural data dumps, but we are data-limited in other kinds of data in terms of triggering interesting latent capabilities.
In terms of raw data, The Pile and CC have more data than you need for the foreseeable future. This does not apply to other kinds of data, like curated sets of prompts. If you think of the pretraining paradigm, the point of large natural real world datadumps is not to be large or because we care about them or because the updates on 99% of the data will be useful, but that by virtue of their sheer size and indiscriminateness, they happen to contain, hidden throughout like flecks of gold in a giant river of sand, implicit unlabeled 'hard tasks' which foster generalization and capabilities through the blessing of scale. One might go through a gigabyte of text before finding an example which truly stresses a model's understanding of "whether a kilogram of feathers weighs more than a kilogram of toasters" - these are simply weird things to write, and are mostly just implicit, and most examples are easily solved by shortcuts. The more easy examples you solve, the more gigabytes or terabytes you have to process in order to find a bunch of examples you haven't already solved, and the bigger your model has to be to potentially absorb the remainder. So there are diminishing returns and you rapidly run out of compute before you run out of raw data.
However, if you can write down a few examples of each of those tasks and produce a highly concentrated dose of those tasks (by distilling the dumps, collating existing challenging benchmarks' corpuses, recruiting humans to write targeted tasks, using adversarial methods to focus on weak points etc.), you can potentially bring to the surface a lot of learning and meta-learning. This is hard to do because we don't know what most of those hard tasks are: they are the water in which we swim, and we don't know what we know or how we know it (which is much of why AI is hard). But you can still try. This has been a very effective approach over the past year or so, and we have yet to see the limits of this approach: the more varied your prompts and tasks, the better models work.