In addition to reporting aggregate metrics on benchmark tasks, we also qualitatively analyzed model outputs and have intriguing findings (Figure 4). We observed that the model can infer basic mathematical operations from context (sample 1), even when the symbols are badly obfuscated (sample 2). While far from claiming numeracy, the model seems to go beyond only memorization for arithmetic.
We also show samples (the last row in Figure 4) from the HANS task where we posed the task containing simple syntactic structures as a question and prompted the model for an answer. Despite the structures being simple, existing natural language inference (NLI) models often have a hard time with such inputs. Fine-tuned models often pick up spurious associations between certain syntactic structures and entailment relations from systemic biases in NLI datasets. MT-NLG performs competitively in such cases without finetuning.
Seems like next big transformer model is here. No way to test it out yet, but scaling seems to continue, see quote.
It is not mixture of experts, so parameters mean something as compared to WuDao (also it beats GPT-3 on PiQA and LAMBADA).
How big of a deal is that?
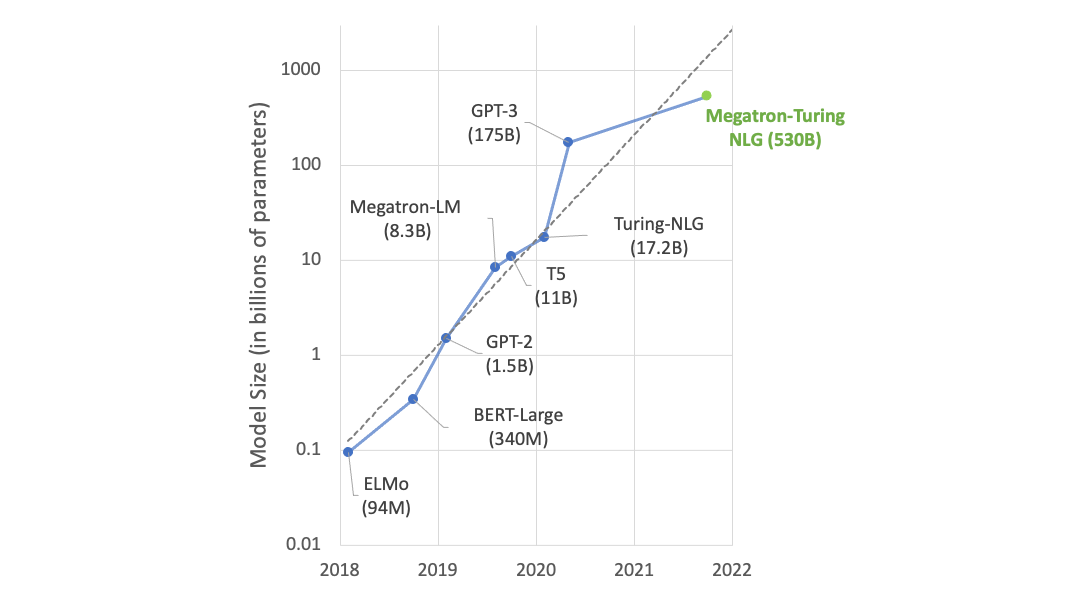
If you just look at models before GPT-3, the trend line you’d draw is still noticeably steeper than the actual line on the graph. (ELMO and BERT large are below trend while T5 and Megatron 8.3B are above.) The new Megatron would represent the biggest trend line undershoot.
Also, I think any post COVID speedup will be more than drown out by the recent slow down in the rate at which compute prices fall. They were dropping by an OOM every 4 years, but now it’s every 10-16 years.