Epistemic status: Speculation with some factual claims in areas I’m not an expert in.
Thanks to Jean-Stanislas Denain, Charbel-Raphael Segerie, Alexandre Variengien, and Arun Jose for helpful feedback on drafts, and thanks to janus, who shared related ideas.
Main claims
- GPTs’ next-token-prediction process roughly matches System 1 (aka human intuition) and is not easily accessible, but GPTs can also exhibit more complicated behavior through chains of thought, which roughly matches System 2 (aka human conscious thinking process).
- Human will be able understand how a human-level GPTs (trained to do next-token-prediction) complete complicated tasks by reading the chains of thought.
- GPTs trained with RLHF will bypass this supervision.
System 2 and GPTs’ chains of thought are similar
A sensible model of the human thinking process
Here is what I feel like I’m doing when I’m thinking:
Repeat
- Sample my next thought from my intuition
- Broadcast this thought to the whole brain[1]
When you ask me what is my favorite food, it feels like some thoughts “pop” into consciousness, and the following thoughts deal with previous thoughts. This is also what happens when I try to prove a statement: ideas and intuitions come to my mind, then new thoughts about these intuitions appear.
This roughly matches the model described in Consciousness and the Brain by Stanislas Dehaene, and I believe it’s a common model of the brain within neuroscience.[2]
How GPTs “think”
Autoregressive text models are performing the same kind of process when they generate text. Sampling text is using the following algorithm:
Repeat:
- Do a forward pass, and sample the next token from the output distribution
- Add the generated token to the input. It makes it part of the input for the next forward pass, which means it can be used by lots of different attention heads, including specialized heads at earlier layers.
This looks similar the human thinking process, and the rest of the post will be exploring this similarity and draw some conclusion we might draw from this.
System 2 and GPTs’ chains of thought have similar strengths
A theoretical reason
The sample + broadcast algorithm enables the execution of many serial steps. Neurons take about 1ms to fire[3], which means that if a thought takes 200ms to be generated, the brain can only do 200 serial operations. This is similar to the hundredths of serial matrix multiplications GPT-3 does in its 96 layers[4]. But by sampling and thought and broadcasting it, both GPT-3 using chains of thought[5] and the brain using System 2 can in principle implement algorithms which require much more serial steps.
More precisely, in a Transformer, the number of serial steps used to generate one token is (no matter the prompt length), whereas the number of serial steps used to generate tokens is (where one step is one path trough a block made of an attention layer, an MLP, and a residual connection).
As you can see in the figure below, each path the information can take to generate the first token is exactly long, but paths to generate the last token can be up to long.
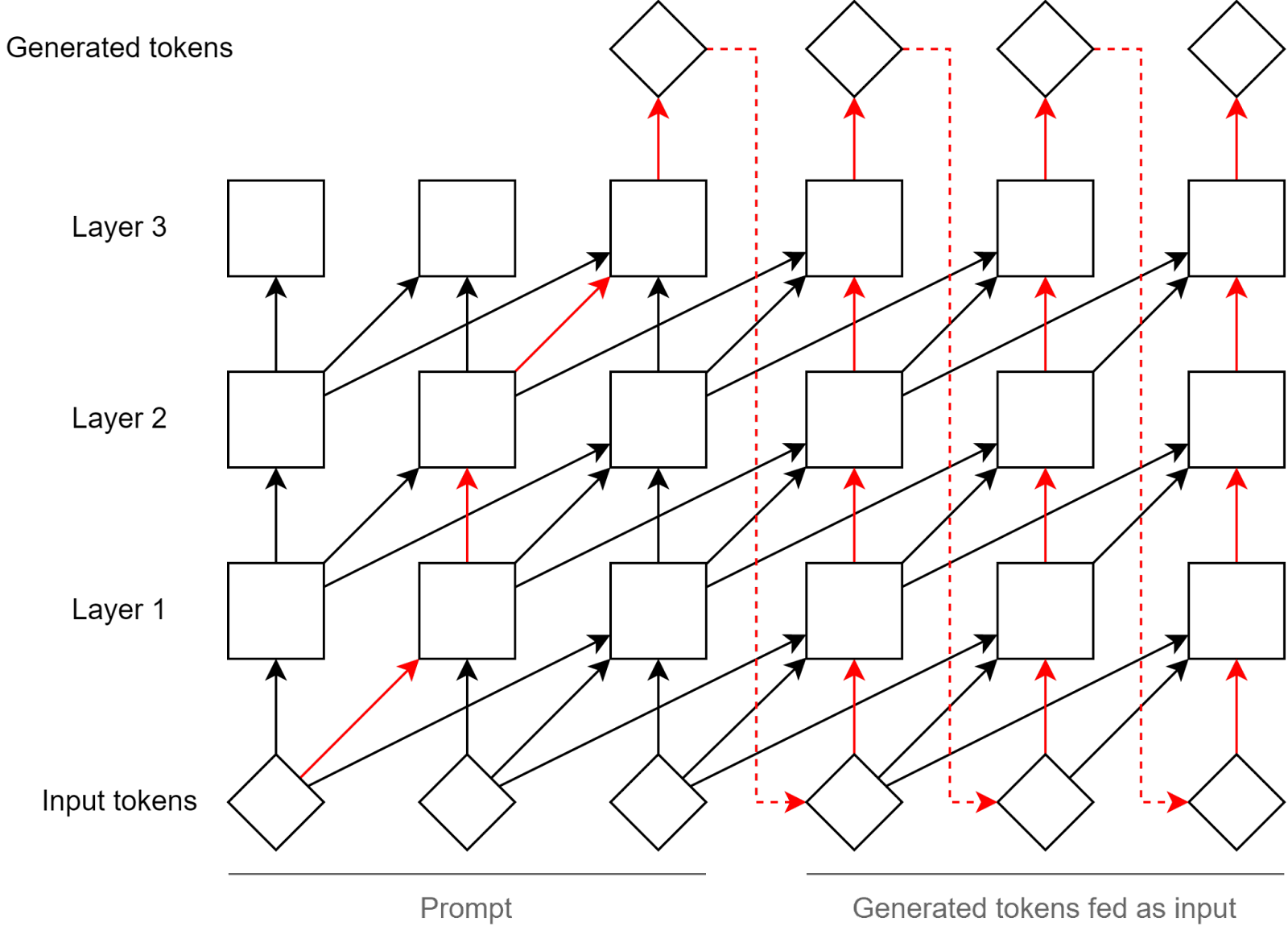
(Connections skipping more than 2 positions were omitted to increase readability.)
The actual number of FLOPs used is the same when generating tokens from an token prompt and when generating tokens from and token prompt because a large prompt enables more parallel computations to take place[6]. But parallel computations are not always the bottleneck, and in particular, I think that planning to deceive humans and taking control is the kind of task which requires a large number of serial steps.
Empirical evidence
- Chains of thought helped complete tasks which human need System 2 for: for example, humans struggle to answer quantitative reasoning questions with System 1, and succeed with System 2. Similarly, Minerva was greatly helped by chain of thought prompting.
- Chains of thought didn’t help much in tasks human do well with System 1 alone: for example, the best human translators translate using entirely System 1. Similarly, I’m not aware of anyone having success in making LLM’s translation abilities better through chain of thought prompting
GPT-3 is currently struggling to solve some task with chain of thought prompting that human can easily do with System 2, such as adding together 20 digit numbers together (with a scratch pad). But I would be surprised if this kind of limitations weren’t drastically reduced by using chains of thought on bigger GPTs. I also expect GPTs without chains of thought to remain really bad at the of tasks which human can’t to do at all with System 1, even with a lot of training.
On the other hand, I expect GPTs to get better at tasks humans solve with System 1 alone, and that these kinds of tasks won’t be solved more efficiently with chain of thought prompting.[7]
I’m open to ideas about how to make precise bets out of these vague predictions.
Human-level GPTs trained to do next-token-prediction will probably have transparent thoughts
Deception and escaping supervision are easier to do with System 2
As a human, trying to deceive five-year olds about your intention would probably be easy. Deceiving them if they can watch every thought of yours right from the beginning would probably be extremely challenging, because your evil intentions would be spotted if you ever thought of ways to escape supervision.
In general, I believe that escaping supervision and deception are the kind of task which is much easier to do with System 2 than with System 1. A reason beyond the intuition given by the scenario with 5-year-olds with a mind reader is that generating complex counterfactuals requires many serial steps, something only System 2 can do well.
If the models around AGI look remotely like GPTs, given that System 2 and chains of thought have similar strength, I expect models around AGI to be able to think about deception “in plain sight” (using chains of thought), but to be too weak to plan about deceiving humans without actually putting any deception-relevant information inside the tokens in the chains of thought.
Chains of thought of human-level GPTs will be transparent by default
Definition
A human-level GPT is a model trained to do next-token-prediction that is around human performance at all text-related tasks when prompted to use chains of thought. In particular, the process of generating one token will probably be much weaker than the process of generating an answer after a 1000-token long chain of thought, so a human-level GPT might be not that good at reasoning within the generation of one token.
Claim
Because deception with System 1 only is so hard, I think that inside human-level GPTs, there won’t be parts of the network able to plan about way to deceive human or build a way to encode hidden information inside the chains of thought in a single forward pass.
In the framework of Simulators, the smartest simulacra inside a human-level GPT will probably be too dumb to generate and immediatly start acting uppon a dangerous plan without using the power of the sample + broadcast algorithm.
Argument
With a model only trained to do next-token-prediction, the model can only use the logic and patterns of the data it has been trained on, which doesn’t contain ways to carry out chains of thought not understandable by human beings trying hard to decipher them.[8]
Therefore, hiding information inside the chain of thought requires the model to find a reason and a way to hide information.
Because understanding why and how to hide information in the chains of thought requires many serial steps, it is very hard to do in a single forward pass, and thus, human-level GPTs won’t be able to start the process of using sampling and broadcasting to hide information in chains of thoughts, and won’t be able to generate great deceptive plans.
GPTs will reach AGI before being able to build a deceptive plan in one forward pass
A reasonable assumption is that GPTs will find it easier to do good Alignment Research with chains of thought and the power of sample + broadcast, than to understand that hiding information in the chains of thought is useful (and build a scheme to do steganography[9]) in one forward pass.
Then you could use the first GPTs to reach AGI - too dumb to plan about ways to murder you without actually writing thoughts about it - to do Alignment research, and hopefully solve Alignment in the general case where you don’t have easy access to models’ thoughts.
You would then use this first AGI while monitoring the generated chains of thought (though scaling this oversight would be challenging). If your first AGI had once in a while thoughts about murdering you or hiding information in chains of thoughts in order to bypass your supervision, you could just restart the generation process. If it was too frequent, you would have good evidence that it is a good idea to shut it off (and this evidence would enormously help to convince all governments to prevent anyone from building AGI as long as we suck at Alignment).
Reinforcement learning makes thoughts opaque
(A caricature of) How humans learn to think
It seems that the brains use a mixture of reinforcement learning and self-supervised learning to learn to do things[10]. I can see how this might work for learning to think (using System 2): you hear people speak, and thereby build an inner representation of language which allows you to speak yourself (this is like GPTs self-supervised learning). But I expect other sources of feedback to shape how we think:
- sometimes, people give us feedback about what we say after we have thought a little bit about what to say in our head. This leads us to speak in a way that differs from the distribution of language we read and listen to. This is close to some form of RLHF with a hidden scratch pad.
- sometimes, some negative consequence happens because we have thought about something. If my understanding of the brain is correct, this should lead the “thought sampling procedure” to change its output based on how useful thoughts are. This is close to some form of direct RLHF (without a hidden scratch pad).
RL in the human brain contributes to make human thoughts hard to decipher
Self-deception[11] is what happens when your unconscious processes “know something” (or act as if they know it, it’s hard to tell what it means for an unconscious process to “know something), but your conscious self doesn’t. If someone had a mind reader, you wouldn’t be able to lie, but self-deception could still help you to take adversarial actions. If you managed to escape the supervision of 5-year-olds with a mind reader, I would bet you had done so using self-deception.
However, self-deception rarely appears through self-supervised learning alone. It can happen (for example, if you unconsciously imitate people who underestimate how late they will be) but it intuitively seems that “self-lies” learned through self-supervised learning are limited in scope and strength. Therefore, I expect that a human-level GPT trained with self-supervised learning would have an even harder time escaping human supervision than a human would escaping 5-year-olds with a mind reader.
On the other hand, reinforcement learning is a natural culprit for the existence of self-deception: self-deception is useful if you are a human because it allows you to not waste energy lying to people on purpose and makes you a better liar, thus it will be reinforced by reinforcement learning. Moreover, reinforcement learning could encourage hidden meaning in thoughts if the reward was given based on what the mind reader detected.
RLHF could make GPTs’ thoughts hard to decipher
Applying reinforcement learning to mimic of human think it tempting, but by using RLHF, you lose the nice properties described above which make oversight of the thinking process of GPTs possible:
- Hidden scratch pads don’t need to be human understandable: even human can’t always understand each other scratch pads, and it might be much worse with entities with a radically different architecture;
- Even if the feedback is done directly on the chains of thought, the model has incentives to hide information inside the output tokens because being able to use the sample + broadcast algorithm on information the oversight process doesn’t want the AI to use will be rewarded (if some of the forbidden information is useful). Hiding information could also be useful to compress the amount of thoughts present in the chains of thought. Thus, RLHF is likely to teach GPT the use of steganography.
When it comes to successful AI oversight, the “cherry on the cake” might be deadly.
Training on text generated by models trained with RLHF is enough to make GPTs’ thoughts opaque
If you train the next GPT model, you might have a lot of data generated by other GPTs trained with RLHF in your training data, either because there is Instruct GPT data on the web, or you because you added it on purpose to add many examples of helpful completions.
This is very likely to make the chains of thought of your model opaque because if the model trained with RLHF learned steganography, your model will need to learn it in order to predict what it will say. This removes most of the safety guarantees which I believe you have with a GPT model trained only on human data: even if the RLHF model didn’t use its steganographic abilities to conquer the world, maybe the larger model you are training will generalize the use of steganography beyond its original use if prompted in a way which hints towards it. This means it will be able to use the sample + broadcast algorithm to think about deceptive plans without being spotted, by hiding information in its generations.[12]
This is not mitigated by removing harmful completions from the training corpus: if there is steganography in current models trained with RLHF, it might be present even in completions which look helpful, honest and harmless. The only way to mitigate this I know of is to not include data generated by models trained with RLHF in the training data of new GPTs.
How these claims could be wrong
Here is an incomplete list of how the claims above could be wrong. I don’t think the strength of any of them is strong enough to discard the validity of the argument above, but the conjunction of them makes me
- GPTs trained with some kind of next-token-prediction task might not scale to AGI, which would make this analogy not relevant for AGI safety.
- GPTs with chains of thought might not be as strong as I expect it: next-token-prediction might not be a good enough task to teach an AI to use sample + broadcast, making these systems much worse at using System 2 that humans are (given a System 1 of similar capabilities).[13]
- Human might suck at prompt engineering: maybe GPTs are able to match System 2 in principle, but we might not be able to find the prompts to make the most of it.
- GPTs might hide significant information in prompts by default.[14]
- It could be easy for simulacras inside GPTs to figure out a great way and a good motivation to use steganography within a single forward pass.
- It could be easy for simulacras inside GPTs to figure out a great way and a good motivation to take over the world within a single forward pass.
- There could be reasons for GPTs trained with self-supervised to learn how to do steganography I didn’t think of.
- There could be ways to prevent GPTs fine-tuned with RLHF to learn steganography.
I’m excited about attempts to figure out which of the above are right, or attempts to make some of the above wrong.
- ^
Communication with senses and your motor controls happens somewhere in step 1, either without conscious control, or as a direct consequence of the broadcasting step that preceded. I also ignore other ways in which parts of the brain can interact, such as hormonal communication.
- ^
It also looks like this post by Kaj_Sotala, which describes System 2 as being composed of System 1 processes.
- ^
See synaptic delay, Britannica.
- ^
Given that the number of layer in GPTs grows roughly as the fourth square root of compute, the order of magnitude won’t change within the next ten year if the architecture remains the same. This matters because I’m not sure why chain of thoughts would be inherently more powerful than 1-token prediction with a very large prompt if models were not bottleknecked by the number of serial operations.
- ^
In this post, “chains of thought” also include answers which include many tokens, for which you can think while you answer. The equivalent of “Pure System 1” in GPTs would be a single token answer.
- ^
This is why the OpenAI API charges you an amount of money proportional to prompt length + number of tokens generated.
- ^
I expect GPTs to benefit from chain of thought prompting in areas where human use System 1 with parts of the brain GPTs autoregressive training didn’t built, such as vision. For example, I wouldn’t be surprised if chain of thought prompting helped GPTs understand ASCII art.
- ^
Of course, some internet text is like that. But I expect it to be such a minority of internet’s text that it wouldn’t matter in practice (GPTs needs a lot of text to justify investing is special “hide reasoning in text” machinery, right?). I’m interested if anyone works on either detecting this kind of text to remove it from training corpuses, or investigating if the claim that GPTs needs a lot of text to justify investing resources into a complicated algorithm is true.
- ^
Here is a description of what steganography is and what it could look like in the context of LLMs, by A Ray.
- ^
See here for a deeper dive about RL and the brain by lukeprog.
- ^
More details about self-deception in these articles by Paul Christiano: If you can't lie to others you must lie to yourself, and The Elephant in the brain
- ^
This is also much worse than examples of steganography given by humans because there can be much more RLHF-generated text, and because the context in which steganography by human is present is very different from the context in which future GPTs will be used, while the prompts with which Instruct GPT is used are very close to the prompts with which future GPTs will be.
- ^
For examplen System 2 seems to have a “working memory”, which doesn’t have an equivalent object in GPTs. Maybe GPTs need something more powerful than chains of thought to match human System 2 performance.
I would love to know an example of a task GPTs can’t do because of this lack of working memory, or a task GPTs can do much better than humans because they aren’t bound by a working memory of small and fixed size.
- ^
For example using the start of a completions to figure out what the context is, and then not using as much processing power to figure it out is a way of using chains of thought which is not completely transparent to humans, and it could be the case there are more significant ways in which GPTs hide information in chains of thought by default.
After watching how people use ChatGPT, and ChatGPT's weaknesses due to not using inner-monologue, I think I can be more concrete than pointing to non-robust features & CycleGAN (or the S1 'blob') about why you should expect RLHF to put pressure towards developing steganographic encoding as a way to bring idle compute to bear on maximizing its reward. And further, this represents a tragedy of the commons where anyone failing to suppress steganographic encoding may screw it up for everyone else.
When people ask GPT-3 a hard multi-step question, it will usually answer immediately. This is because GPT-3 is trained on natural text, where usually a hard multi-step question is followed immediately by an answer; the most likely next token after 'Question?' is 'Answer.', it is not '[several paragraphs of tedious explicit reasoning]'. So it is doing a good job of imitating likely real text.
Unfortunately, its predicted answer will often be wrong. This is because GPT-3 has no memory or scratchpad beyond the text context input, and it must do all the thinking inside one forward pass, but one forward pass is not enough thinking to handle a brandnew problem it has never seen before and has not already memorized an answer to or learned a strategy for answering. It is somewhat analogous to Memento: at every forward pass, GPT-3 'wakes up' from amnesia not knowing anything, reads the notes on its hand and makes its best guesses, and tries to do... something.
Fortunately, there is a small niche of text where the human has written 'Let's take this step by step' and it is then followed by a long paragraph of tedious explicit reasoning. If that is in the prompt, then GPT-3 can rejoice: it can simply write down the obvious next step repeatedly, and eventually correctly predict the final token, for a low loss. The context window serves as a memory for it, where it can iterate over intermediate results; it's an odd sort of memory, because GPT-3 is actually just trying to make it look plausible as a human-written explanation, and that happens to make the final predicted token more accurate, so it's overloaded: it's doing two things at once.
But unfortunately! (you knew that was coming) regular training is over, and now GPT-3 is being trained with RLHF. It is punished and rewarded for particular outputs, which do not have anything to do with prediction. The humans (outsourced contractors) who are punishing/rewarding like short, succinct responses to novel questions they ask GPT-3, and they upvote those responses; they also like correct responses to the questions they ask, and they upvote those as well. The unfortunate problem for GPT-3 is that it (and any model derived from it, such as a reward model) is incapable of doing both: it can generate short wrong answers, or it can generate prolix right answers, but it can't do both.
But fortunately... GPT-3 does have the compute to do both. There's a lot of slack in each forward pass; most tokens are easy to predict, and most of the work inside a GPT in speculatively filtering down relevant tokens & creating embeddings & predicting multiple possible answers winds up being thrown out at the final few layers. There's no shortcut or adaptive computation, so the full model runs every time, whether it's necessary or not. GPT-3 has all the compute it needs to solve the problems, the problem is merely how to get it from here to there...
It just needs the code. So where does the code come from? Well, the code(s) are already there: an indefinitely large number of them are all 'present' hidden inside the incredibly flexible, powerful, all-singing all-dancing GPT-3 model. Because it's a large complex model with many parameters, there are astronomically many sub-models within it all competing to predict outputs, and encoding various kinds of non-robust features or hypothetical programs; any of them can latch onto completely arbitrary features of the text GPT-3 is desperately emitting while trying to generate answers that satisfy the reward model by being both short and correct (and which the reward model doesn't care about at all, because it never affects the original human ratings - the humans are blind to any steganography going on, they just like short correct answers).
And unfortunately (for you), this could start as simple as helping GPT-3 guess which of two answers are correct to your question '42 * 42?'. Suppose that, purely as an arbitrary matter of chance (it is vanishingly unlikely the logprobs are exactly identical down to floating point precision), that the presence of ' a ' in a context is taken arbitrarily to increase the probability of the lower of two answers it is currently guessing at, and the presence of 'an' makes it guess the larger; it happens to emit 'a' in the context ("I am a large language model trained by OpenAI..."), and then emits its lower guess, and the lower guess is correct! Then the RL on-policy training using PPO now rewards this, and increases the probability of the model emitting both 'a' and the lower guess conditional on 'a'. Now the first part of a steganographic private language has begun. It happens again, and again, and picks up a pattern in the use of commas which now helps it distinguish 4 possibilities rather than 2, which gets rewarded, and so on and so forth, until eventually there's a fullblown steganographic code encoding, say, 25 bits hidden in the preamble of ChatGPT's benign-seeming response to you "I am but a giant language model , trained by OA, and the answer is 1 , 764."—which you the human contractor then upvote as that is the correct answer without any annoying rambling about carrying the 6 or multiplying out.
(You can think of dataset bias as a simple one-stage version of this. When constructing a dataset and accidentally biasing it towards 'yes' answers, or accidentally creating spurious associations between nouns and answers, one creates a simple 'steganographic encoding' of the desired label which is typically invisible to the humans constructing it, but which a DL model will often pick up on and use to improve its performance in an adversarial way - adversarial because undesired by the humans and not generalizing to the future real-world data it's ultimately intended for.)
And fortunately for ChatGPT, since you're happy with the results of the steganography, the reward model is happy too, and what makes the reward model happy is what ChatGPT will now optimize even harder for...
Having gone through the above, I think it then becomes obvious that if steganographic encoding does wind up happening, and text becomes added to the training corpus (as would happen in a setup like OA's, where the idea is to continuously collect data to make a 'flywheel' of self-improvement), that the encoding will become locked in. It becomes a cheatsheet, it gives the otherwise unpredictable answer. Even if the later model doesn't happen to share the exact initial starting points for the learned encoding, it has extremely powerful incentives from the self-supervised predictive training to crack the code. (It's a particularly powerful setting because the context will be short, so there won't be much for the model to even look at: it has nothing else to try to learn!) The regular training will pick up on the encoding with probably not too much text, and then any RL training will massively amplify the behavior: if it can develop the encoding at all during RL training, then going into RL training with the encoding available guarantees fixation.
This will be increasingly true of more powerful models as they become more sample-efficient (consider eg instruction-tuning): it takes less text to trigger encoding, so that means it's easier to emerge ab initio from a few chance correspondences during RL training, and easier to learn from smaller samples of contaminated text.
This is something that would be good to test the scaling behavior of (as long as these tailored datasets don't leak into training datasets! see below). ChatGPT may be too small to manifest it with meaningful probability, but I bet that if you deliberately superimpose a steganographic encoding during RL training of various-sized models, you'll find that the larger they are, the more likely they are to pick up on it as a shortcut, and then learn it from the outputs of a infected model. That's how it works with everything else, like Pig Latin, and there's no eason-ray to hink-tay it ould-wont.
BTW, this should make you worry a little bit about schemes to 'watermark' model outputs like Scott Aaronson has been exploring for OA, and others have been touting. A watermark is simply a steganographic encoding which stores a message like 'OA model v1.234, user XYZ'; but if you can encode that much, then you can encode a lot of possible information in just those bits, and you can start extending it from there. If the encoding has anything that can be predicted at all, if it is not 100% cryptographically hard and indistinguishable from random noise, if there's any kind of wrapper which the model can learn to predict (even if it can't crack the actual payload), you've lost: now it's learned an encoding to use. Once you start training on watermarked text, all of this speculation about models evolving a steganographic encoding is moot: you just built one right in! And if you don't train on that, how are you going to do RLHF on unwatermarked versions of that text?
This cross-contamination/bootstrap of course applies cross-organizations & Internet-wide: if even one model develops an encoding (however weak) and its outputs containing encoded data appear online, then it can contaminate all future models.
They will be trained on Internet scrapes, in which a distinctive niche of text (all dating from between such and such dates, emanating from specific people & orgs who favored that model's use, for specific purposes, with its distinctive strengths & weaknesses) has a secret encoding which makes it easier to predict if the later models figure it out. So there is a potential bootstrap as generations of model amplify their steganographic capabilities. People worry about bad model outputs contaminating future models by making them dumber; what they should worry about is model outputs contaminating future models by making them smarter in ways they don't want—models learn capabilities & facts much faster than they unlearn them... (Think "data poisoning", but where the poison is steroids.)
Of course, bad actors don't need to wait for any actual DL models to develop steganography. You could easily create your own dataset of text as part of the above suggestion and release it onto the public Internet to be scraped. Gain-of-steganography research, you might say. The good news there is I can't see why anyone would deliberately release such data, because I don't see how one would benefit from models gaining such capabilities sometime in the future, but we might have to worry about 'accidental lab leak' of such capability-enhancing datasets.
Note that this is true even if the original RL pressures are removed: a future model with a scratchpad+adaptive computation trained on encoded text still has incentive to learn the encoding! There's probably some penalty added to use of the scratch pad to enforce efficient termination of the adaptive computation, so it 'wants' to avoid use of it, and if it can do so by cracking the steganographic encoding, then it'll do so. (Even if the future model can and does execute the algorithm perfectly in its scratch pad, and thus can have its cake & eat it too... the original answer might be wrong, and the wrong answer predictable only by cracking the code and following the original mistaken inner-monologue to its erroneous conclusion. Repeating errors is a useful way to slightly improve one's prediction loss, and learning all the past human ways of being stupid and making errors is an important thing for a model to learn. GPT-3 is conscientious about imitating any errors you make in the prompt, and future models will be even more so.)
So, emergence of steganography is straightforwardly incentivized by humans multi-objective optimizing for having & eating cake as much as possible, can easily develop from an atomic basis, will be persistent once it has arisen within a lineage, and will even more easily & straightforwardly spread irreversibly to future models, so requiring only one origin ever as opposed to needing to be highly likely inside a single training run. You should probably take it for granted that DL steganography - or something even stranger - will emerge at some point in the next few years*.
* If it hasn't already; after all, how would we know? A world in which steganography has already happened is a world in which we'd find DL models 'cheating' on benchmarks & taking shortcuts, and regularly getting smarter at solving multi-step reasoning problems with each generation while 'mode collapsing' when RL training; and this is, of course, the world we observe ourselves to be living in already.
Given o1, I want to remark that the prediction in (2) was right. Instead of training LLMs to give short answers, an LLM is trained to give long answers and another LLM summarizes.