Solution:
#!/usr/bin/env python3
import struct
a = [1.3, 2.1, -0.5] # initialize data
L = 2095 # total length
i = 0
while len(a)<L:
if abs(a[i]) > 2.0 or abs(a[i+1]) > 2.0:
a.append(a[i]/2)
i += 1
else:
a.append(a[i] * a[i+1] + 1.0)
a.append(a[i] - a[i+1])
a.append(a[i+1] - a[i])
i += 2
f = open("out_reproduced.bin","wb") # save in binary
f.write(struct.pack('d'*L,*a)) # use IEEE 754 double format
f.close()
Then one can check that the produced file is identical:
$ sha1sum *bin
70d32ee20ffa21e39acf04490f562552e11c6ab7 out.bin
70d32ee20ffa21e39acf04490f562552e11c6ab7 out_reproduced.bin
edit: How I found the solution: I found some of the other comments helpful, especially from gjm (although I did not read all). In particular, interpreting the data as a sequence of 64-bit floating point numbers saved me a lot of time. Also gjm's mention of the pattern a, -a, b, c, -c, d was an inspiration.
If you look at the first couple of numbers, you can see that they are sometimes half of an earlier number. Playing around further with the numbers I eventually found the patterns a[i] * a[i+1] + 1.0 and a[i] - a[i+1].
It remaine...
I have mixed thoughts on this.
I was delighted to see someone else put forth an challenge, and impressed with the amount of people who took it up.
I'm disappointed though that the file used a trivial encoding. When I first saw the comments suggesting it was just all doubles, I was really hoping that it wouldn't turn out to be that.
I think maybe where the disconnect is occurring is that in the original That Alien Message post, the story starts with aliens deliberately sending a message to humanity to decode, as this thread did here. It is explicitly described as such:
From the first 96 bits, then, it becomes clear that this pattern is not an optimal, compressed encoding of anything. The obvious thought is that the sequence is meant to convey instructions for decoding a compressed message to follow...
But when I argued against the capability of decoding binary files in the I No Longer Believe Intelligence To Be Magical thread, that argument was on a tangent -- is it possible to decode an arbitrary binary files? I specifically ruled out trivial encodings in my reasoning. I listed the features that make a file difficult to decode. A huge issue is ambiguity because in almost all...
Even more obviously, why do aliens adhere to the IEEE 754 standard? My interpretation is that the cryptanalyst from the post has indeed been pranked by their friend at NASA.
Interpreting each 8-byte block as an IEEE double-precision float (endianity whatever's default on x86-64, which IIRC is little-endian) yields all values in the range -4 .. 4.2. FFT of the resulting 2095 values gives (ignoring the nonzero DC term arising from the fact that the average isn't quite zero) is distinctly not-flat, indicating that although the numbers look pretty random they are definitely not -- they have more high-frequency and less low-frequency content than one would get from truly random numbers.

By the way, it's definitely not aliens. Aliens would not be sending messages encoded using IEEE754 double-precision floats.
The first few numbers are mostly "nice". 1.3, 2.1, -0.5, 0.65, 1.05, 0.675, -1.15, 1.15, 1.70875, 0.375, -0.375, -0.3225, -2.3, 2.3. Next after that is 1.64078125, which is not so nice but still pretty nice.
These are 13/10, 21/10, -1/2, 13/20, 21/20, 27/40, -23/20, 23/20, 1367/800, 3/8, -3/8, -129/400, -23/10, 23/10, 10501/6400, ...
A few obvious remarks about these: denominators are all powers of 2 times powers of 5; 13 and 21 are Fibonacci numbers; shortly after 13/10 and 21/10 we have 13/20 and 21/20; we have three cases of x followed by -x.
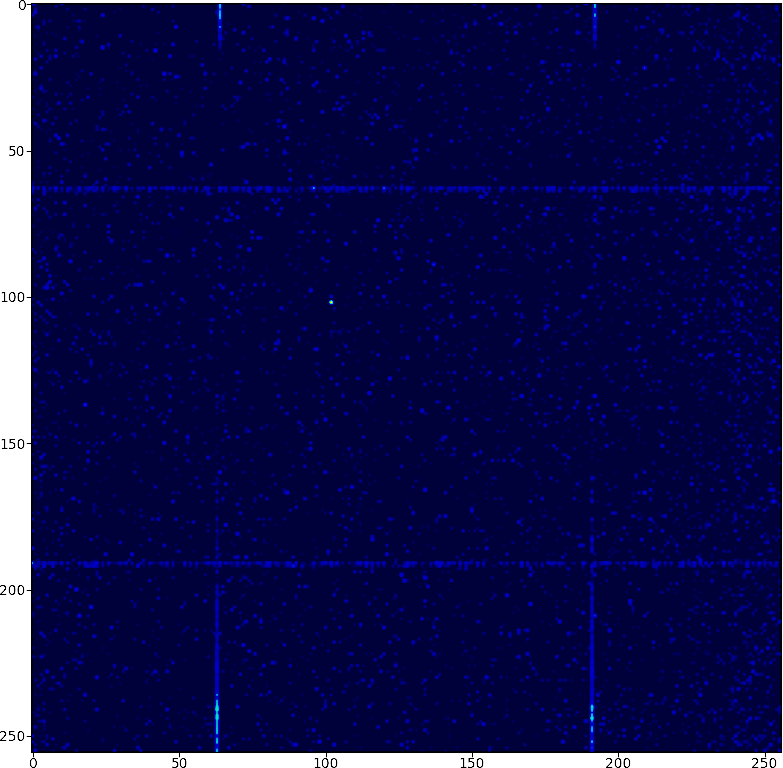
If you plot the correlation of consecutive pairs of bytes, it looks like this. The bright dot is 102, which repeats itself a fair bit at the start. The horizontal and vertical lines are 63,64,191,192 as every 8th number is one of those four values. Most of the space is 0. when a pattern appears once, it usually appears more than once. 2,4,6,8,10,12 all appear frequently.
Just wanted to say I think this is a cool experiment and look forward to seeing how it plays out.
(This is somewhat betting on the contest turns out to be a well crafted experience/goal, so I guess also specifically looking to see the debrief on that)
Without looking at the data, I’m giving a (very rough) ~5% probability that this is a version of the Arecibo Message.
Enumerating our unfair advantages:
- We know the file was generated by code
- We know that code was written by a human 2a. That human was trying to simulate an extraterrestrial signal
- We know that this is a puzzle, though not a "fair" puzzle like those found in escape rooms or that MIT contest. 3a. An exhaustive brainstorming of different domains of solution is warranted.
Well, looking at the binary data reveals some patterns; the first 6 bytes of each block of 8 start out highly repetitive, though this trend lessens later in the file. This is what it looks like as an image.
{kind=link}
{kind=link}
Thanks for doing this. I was considering offering my own version of this challenge, but it would have just been the last 50% of a file in a standard media format. That may stump one unmotivated person but probably would be easy for a large community to crack. (But what an update it would be if LWers failed that!) Anyway, I didn't have the time to do the challenge justice, which is why I didn't bother. So again, thanks!
If you let w be the first of the negation pairs, and q come before it. So the sequence goes ..., q, w, -w, ...
Then a plot of q (x axis) and w(y axis) looks like.
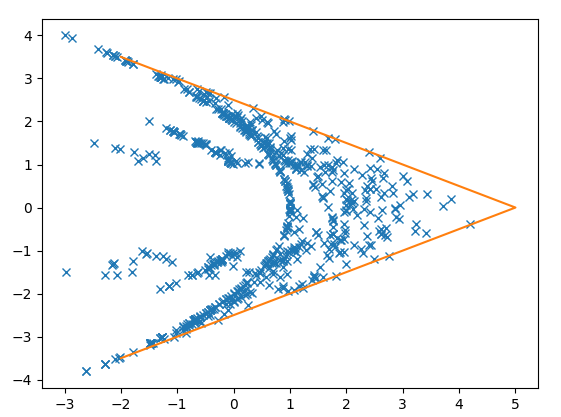
All points are within the orange line (which represents absolute(w)<-0.5*q+2.5 )
Note also that this graph appears approximately symmetric about the x axis. You can't tell between ...q,w,-w... and ...q, -w, w, ... The extra information about which item of the pair is positive resides elsewhere.
For comparison, the exact same graph, but using an unfiltered list of all points, looks like...
Here is the image you get if you interpret the data as floats, consider the ratio of all possible pairs, and color those with a simple ratio blue.

The pattern of horrizontal and vertical lines in the top left corner is straightforward, those numbers are individually simple fractions, so their ratio is too. The main diagonal is just numbers having a simple 1:1 ratio with themselves. The shallower diagonal lines tell us something interesting.
The non_diagonal line that is closest to diagonal means some process must be refering back to values around 73% a...
Misc. notes:
- As we've all discovered, the data is most productively viewed as a sequence of 2095 8-byte blocks.
- The eightth byte in each block takes the values 64, 63, 192, and 191. 64 and 192 are much less common than 63 and 191.
- The seventh byte takes a value between 0 and 16 for 64/192 rows, weighted to be more common at the 0 end of the scale. For 63/191 rows, it takes a value between ??? and 256, strongly weighted to be more common at the 256 end of the scale (the lowest is 97 but there's nothing special about that number so the generator probably
Some thoughts for people looking at this:
- It's common for binary schemas to distinguish between headers and data. There could be a single header at the start of the file, or there could be multiple headers throughout the file with data following each header.
- There's often checksums on the header, and sometimes on the data too. It's common for the checksums to follow the respective thing being checksummed, i.e. the last bytes of the header are a checksum, or the last bytes after the data are a checksum. 16-bit and 32-bit CRCs are common.
- If the data represents
I'm treating the message as a list of 2095 chunks of 64 bits. Let d(i,j) be the Hamming distance between the i-th and j-th chunk. The pairs (i,j) that have low Hamming distance (namely differ by few bits) cluster around straight lines with ratios j/i very close to integer powers of 2/e (I see features at least from (2/e)^-8 to (2/e)^8).
Hex dump of the first chunk of the file:
00000000: cdcc cccc cccc f43f cdcc cccc cccc 0040 .......?.......@
00000010: 0000 0000 0000 e0bf cdcc cccc cccc e43f ...............?
00000020: cdcc cccc cccc f03f 9a99 9999 9999 e53f .......?.......?
00000030: 6666 6666 6666 f2bf 6666 6666 6666 f23f ffffff..ffffff.?
00000040: d8a3 703d 0a57 fb3f 0000 0000 0000 d83f ..p=.W.?.......?
00000050: 0000 0000 0000 d8bf a070 3d0a d7a3 d4bf .........p=.....
00000060: 6666 6666 6666 02c0 6666 6666 6666 0240 ffffff..ffffff.@
00000070: 713d 0ad7 a340 fa3f d8a3 703d 0a57 Solution domain brainstorms (reply ti this thread with your own:
- A deliberate message in an alien language
- Sensor data from a pulsar, comet, or other astronomical event
- An encoded image in an alien encoding scheme
- A mathematical "test pattern" - possibly to serve as a key for future messages
The zipped version of the message is 59.47% the size of the orginal. DEFLATE (the zipping algorithm) works by using shorter encodings for commonly-used bytes, and by eliminating duplicated strings. Possible next steps include investigating the frequencies of various bytes (histograms, Huffman trees).
Interpreting the data as unsigned 8-bit integers and plotting it as an image with width 8 results in this (only the first few rows shown):

The rest of the image looks pretty similar. There is a almost continuous high-intensity column (yellow, the second-to-last column), and the values in the first 6 columns repeat exactly in the next row pretty often, but not always.
Scenario
You're not certain that aliens are real. Even after receiving that email from your friend who works at NASA, with the subject line "What do you make of this?" and a single binary file attached, you're still not certain. It's rather unlikely that aliens would be near enough to Earth to make contact with humanity, and unlikelier still that of all the humans on Earth, you would end up being the one tasked with deciphering their message. You are a professional cryptanalyst, but there are many of those in the world. On the other hand, it's already been months since April Fools, and your friend isn't really the prankster type.
You sigh and download the file.
Rules
No need to use spoiler text in the comments: This is a collaborative contest, where working together is encouraged. (The contest is between all of you and the difficulty of the problem.)
Success criteria: The people of LessWrong will be victorious if they can fully describe the process that generated the message, ideally by presenting a short program that generates the message, but a sufficiently precise verbal description is fine too.
The timeframe of the contest is about 2 weeks. The code that generated the message will be revealed on Tuesday July 12.
Why is this interesting?
This contest is, of course, based on That Alien Message. Recently there was some discussion under I No Longer Believe Intelligence to be "Magical" about how realistic that scenario actually was. Not the part where the entire universe was a simulation by aliens, but the part where humanity was able to figure out the physics of the universe 1 layer up by just looking at a few frames of video. Sure it may be child's play for Solomonoff Induction, but do bounded agents really stand a chance? This contest should provide some experimental evidence.