

This graph is the biggest update to the AI alignment discourse since GPT-3
For those of you unfamiliar with the lore, prior to GPT-3, the feeling was that AGI would rapidly foom based on recursive-self improvement.
After GPT-3, it became clear that the first AGI would in reality be built in a large lab using a multi-billion dollar supercomputer and any idea that it simply "copy itself to the internet" is nonsense.
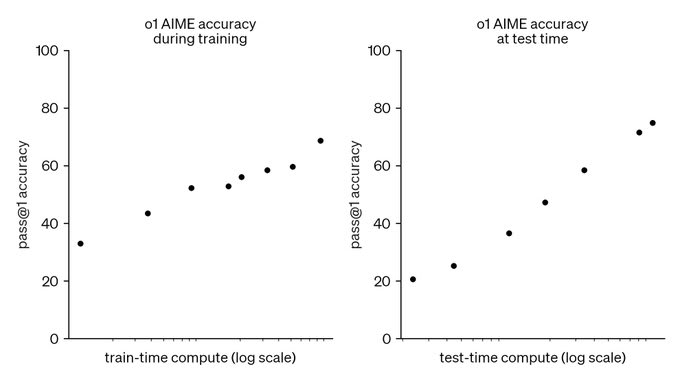
Under the GPT-3 regime, however, it was still plausible to assume that the first AGI would be able to simulate millions of human beings. This is because the training cost for models like GPT-3/4 is much higher than the inference cost.
However, COT/o1 reveals this is not true. Because we can scale both training and inference, the first AGI will not only cost billions of dollars to train, it will also cost millions of dollars to run (I sort of doubt people are going to go for exact equality: spending $1b each on training/inference, but we should expect them to be willing to spend some non-trivial fraction of training compute on inference).
This is also yet another example of faster is safer. Using COT (versus not using it) means that we will achieve the milestone of AGI sooner, but it also means that we will have more time to test/evaluate/improve that AGI before we reach the much more dangerous milestone of "everyone has AGI on their phone".
Scaling working equally well with COT also means that "we don't know what the model is capable of until we train it" is no longer true. Want to know what GPT-5 (trained on 100x the compute) will be capable of? Just test GPT-4 and give it 100x the inference compute. This means there is far less danger of a critical first try since newer larger models will provide efficiency improvements moreso than capabilities improvements.
Finally, this is yet another example of why regulating things before you understand them is a bad idea. Most current AI regulations focus on limiting training compute, but with inference compute mattering just as much as training compute, such laws are out of date before even taking effect.












AI does everything faster, including consumption of power. If we compare tokens per joule, counterintuitively LLMs turn out to be cheaper (for now), not more costly.
Any given collection of GPUs working on inference is processing on the order of 100 requests at the same time. So for inference, 16 GPUs (2 nodes of H100s or MI300Xs) with 1500 watts each (counting the fraction of consumption by the whole datacenter) consume 24 kilowatts, but they are generating tokens for 100 LLM instances, each about 300 times faster than the speed of relevant human reasoning token generation (8 hours a day, one token per second). If we divide the 24 kilowatts by 30,000, what we get is about 1 watt. Training cost is roughly comparable to inference cost (across all inference done with a model), so doesn't completely change this estimate.
An estimate from cost gives similar results. An H100 consumes 1500 watts (as fraction of the whole datacenter) and costs $4/hour. A million tokens of Llama-3-405B cost $5. A human takes a month to generate a million tokens, which is 750 hours. So the equivalent power consumed by an LLM to generate tokens at human speed is about 2 watts. Human brain consumes 10-30 watts (though for a fair comparison, reducing relevant use to 8 hours a day, this becomes more like 3-10 watts on average).