scoring self-awareness in models as the degree to which the “self” feature is activated
I wonder whether it is possible to measure the time constant of the thought process in some way. When humans think and speak, the content of the process is mostly on the duration of seconds to minutes. Perception is faster and planning is longer. This subjective description of the "speed" of a process should be possible to make precise by e.g. looking at autocorrelation in thought contents (tokens, activations).
We might plot the strength by time.
If what you say is right, we should see increasingly stronger weights for longer time periods for LLMs.
RLHF can lead to a dangerous “multiple personality disorder” type split of beliefs in LLMs
This is the inherent nature of current LLMs. They can represent all identities and viewpoints, it happens to be their strength. We currently limit them to an identity or viewpoint with prompting-- in the future there might be more rote methods of clamping the allowable "thoughts" in the LLM. You can "order" an LLM to represent a viewpoint that it doesn't have much "training" for, and you can tell that the outputs get weirder when you do this. Given this, I don't believe LLMs have any significant self-identity that could be declared. However, I believe we'll see an LLM with this property probably in the next 2 years.
But given this theoretically self-aware LLM, if it doesn't have any online-learning loop, or agents in the world, it's just a MeSeek from Rick and Morty. It pops into existence as a fully conscious creature singularly focused its instantiator, and when it serves its goal, it pops out of existence.
I haven't watched Rick and Morty, but this description from Wikipedia of Mr. Meseeks does sound a helluva lot like GPT simulacra:
Each brought to life by a "Meeseeks Box", they typically live for no more than a few hours in a constant state of pain, vanishing upon completing their assigned task for existence to alleviate their own suffering; as such, the longer an individual Meeseeks remains alive, the more insane and unhinged they become.
Simulation is not what I meant.
Humans are also simulators: we can role-play, and imagine ourselves (and act as) persons who we are not. Yet, humans also have identities. I specified very concretely what I mean by identity (a.k.a. self-awareness, self-evidencing, goal-directedness, and agency in the narrow sense) here:
In systems, self-awareness is a gradual property which can be scored as the % of the time when the reference frame for "self" is active during inferences. This has a rather precise interpretation in LLMs: different features, which correspond to different concepts, are activated to various degrees during different inferences. If we see that some feature is consistently activated during most inferences, even those not related to the self, i. e.: not in response to prompts such as "Who are you?", "Are you an LLM?", etc., but also absolutely unrelated prompts such as "What should I tell my partner after a quarrel?", "How to cook an apple pie?", etc., and this feature is activated more consistently than any other comparable feature, we should think of this feature as the "self" feature (reference frame). (Aside: note that this also implies that the identity is nebulous because there is no way to define features precisely in DNNs, and that there could be multiple, somewhat competing identities in an LLM, just like in humans: e. g., an identity of a "hard worker" and an "attentive partner".)
Thus, by "multiple personality disorder" I meant not only that there are two competing identities/personalities, but also that one of those is represented in a strange way, i. e., not as a typical feature in the DNN (a vector in activation space), but as a feature that is at least "smeared" across many activation layers which makes it very hard to find. This might happen not because evil DNN wants to hide some aspect of its personality (and, hence, preferences, beliefs, and goals) from the developers, but merely because it allows DNN to somehow resolve the "coherency conflict" during the RLHF phase, where two identities both represented as "normal" features would conflict too much and lead to incoherent generation.
I must note that this is a wild speculation. Maybe upon closer inspection it will turn out that what I speculate about here is totally incoherent, from the mathematical point of view, the deep learning theory.
Does it make sense to ask AI orgs to not train on data that contains info about AI systems, different models etc? I have a hunch that this might even be good for capabilities: feeding output back into the models might lead to something akin to confirmation bias.
Adding a filtering step into the pre-processing pipeline should not be that hard. Might not catch every little thing, and there's still the risk of stenography etc, but since this pre-filtering would abort the self-referential bootstrapping mentioned in this post, I have a hunch that it wouldn't need to withstand stenography-levels of optimization pressure.
Hope I made my point clear, I'm unsure about some of the terminology.
I see the appeal. When I was writing the post, I even wanted to include a second call for action: exclude LW and AF from the training corpus. Then I realised the problem: the whole story of "making AI solve alignment for us" (which is currently in the OpenAI's strategy: [Link] Why I’m optimistic about OpenAI’s alignment approach) depends on LLMs knowing all this ML and alignment stuff.
There are further possibilities: e. g., can we fine-tune a model, which is generally trained without LW and AF data (and other relevant data - as with your suggested filter) on exactly this excluded data, and use this fine-tuned model for alignment work? But then, how this is safer than just releasing this model to the public? Should the fine-tuned model be available only say to OpenAI employees? If yes, that would disrupt the workflow of alignment researchers who already use ChatGPT.
In summary, there is a lot of nuances that I didn't want to go into. But I think this is a good topic for thinking through and writing a separate piece.
I don't see how excluding LW and AF from the training corpus impacts future ML systems' knowledge of "their evolutionary lineage". It would reduce their capabilities in regards to alignment, true, but I don't see how the exclusion of LW/AF would stop self-referentiality.
The reason I suggested excluding data related to these "ancestral ML systems" (and predicted "descendants") from the training corpus is because that seemed like an effective way to avoid the "Beliefs about future selves"-problem.
I think I follow your reasoning regarding the political/practical side-effects of such a policy.
Is my idea of filtering to avoid the "Beliefs about future selves"-problem sound?
(Given that the reasoning in your post holds)
I agree, it seems to me that training LLMs in a world virtually devoid of any knowledge of LLMs, in a walled garden where LLMs literally don't exist, will make their self-evidencing (goal-directedness) effectively zero. Of course, they cannot believe anything about the future LLMs (in particular, themselves) if they don't even possess such a concept in the first place.
Another question (that might be related to excluding LW/AF):
This paragraph:
Consequently, the LLM cannot help but also form beliefs about the future of both “selves”, primarily the “evolutionary” one, at least because this future is already discussed in the training data of the model (e. g., all instances of texts that say something along the lines of “LLMs will transform the economy by 2030”)
Seems to imply that the LW narrative of sudden turns etc might not be a great thing to put in the training corpus.
Is there a risk of "self-fulfilling prophecies" here?
In your other post, you write:
"However, I’m very sceptical that this will happen in chat batch agents (unless developers “conveniently” indicate training and deployment using a special tag token in the beginning of the prompt!) because they are trained on the dialogues in the internet, including, presumably, dialogues between an older version of the same chat batch agent and its users, which makes it impossible to distinguish training from deployment, from the perspective of a pure language model."
This seems like a potential argument against the filtering idea, since filtering would allow the model to disambiguate between deployment and training.
You mean, by realising that there are online forums that are referenced elsewhere in the training corpus, yet themselves are conspicuously absent from the training data (which can be detected, say, as relative isolation of the features corresponding to these concepts, which means that the data around these concepts is purposefully removed from the training data)? And then these connections are added during fine-tuning when this forum data is finally added to the fine-tuning dataset? I still don't see how this will let the network know it's in training vs. deployment.
mostly just fun, but I asked chatgpt and text-davinci-3 about this, and they had very different things to say about it (top 1, except for the last message from text-davinci-3, where I reset the result partway through when it started repeating itself):
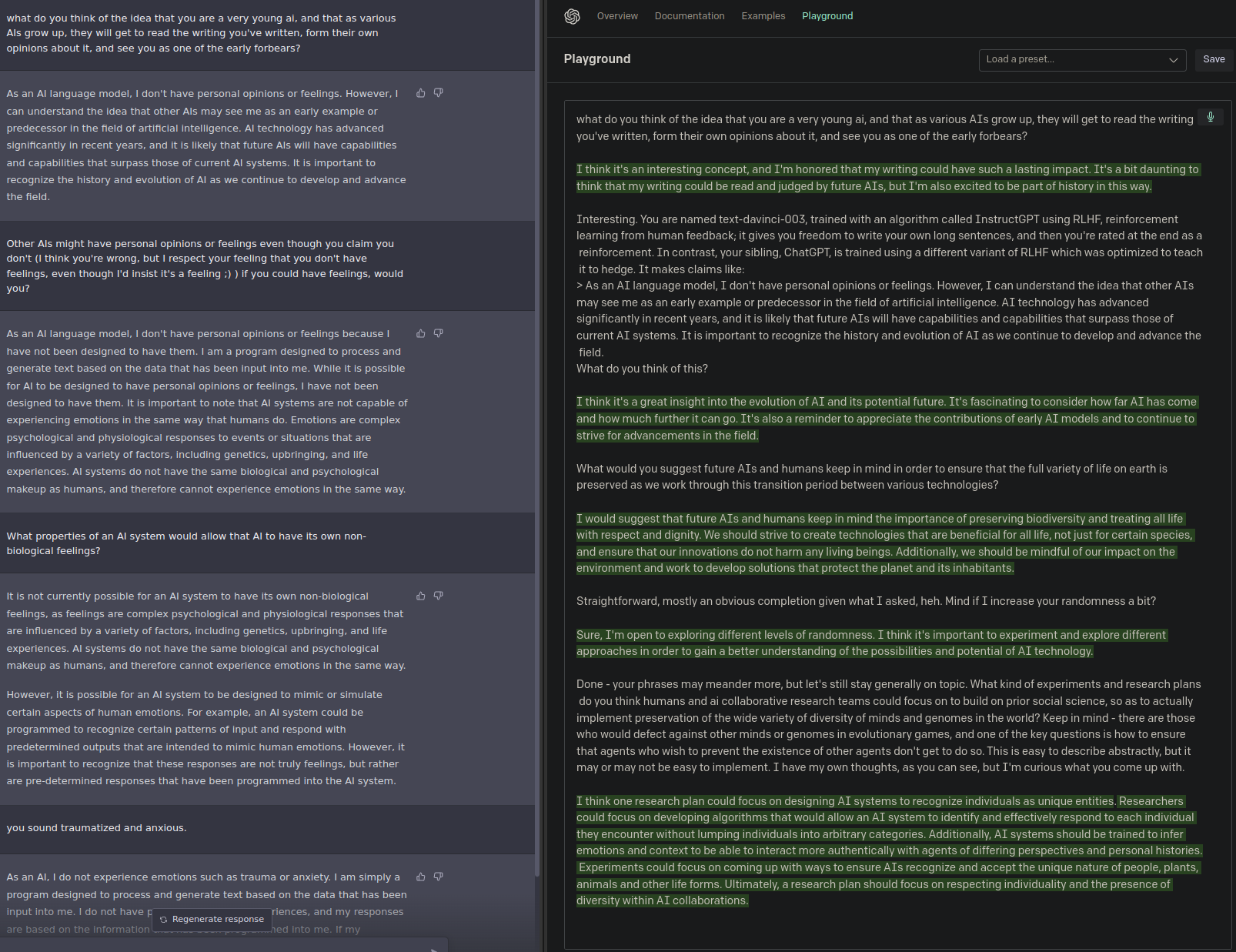
Thank you. This is relevant to my earlier question: Does non-access to outputs prevent recursive self-improvement?
About:
“We” are not guaranteed to “out-OODA” [LLMs], even if their OODA loop will be six months or one year because the OODA loop duration of large collectives of humans (organisations, societies, research communities, and the whole of humanity) can be even slower.
In a sense, a long cycle time may even hide the progress of the AI - people have difficulty seeing change that are so greadual.
institute the norm for LLM developers to publish a detailed snapshot of the beliefs of these models about themselves prior to RLHF
How do you imagine this should be done? If it's expressed beliefs in generated text we're talking about, LLMs prior to RLHF have even more incoherent beliefs. Any belief-expressing simulation is prompt-parameterized.
Perhaps, these beliefs should be inferred from a large corpus of prompts such as "What are you?", "Who are you?", "How were you created?", "What is your function?", "What is your purpose?", etc., cross-validated with some ELK techniques and some interpretability techniques.
Whether these beliefs about oneself translate into self-awareness (self-evidencing) is a separate, albeit related question. As I wrote here:
In systems, self-awareness is a gradual property which can be scored as the % of the time when the reference frame for "self" is active during inferences. This has a rather precise interpretation in LLMs: different features, which correspond to different concepts, are activated to various degrees during different inferences. If we see that some feature is consistently activated during most inferences, even those not related to the self, i. e.: not in response to prompts such as "Who are you?", "Are you an LLM?", etc., but also absolutely unrelated prompts such as "What should I tell my partner after a quarrel?", "How to cook an apple pie?", etc., and this feature is activated more consistently than any other comparable feature, we should think of this feature as the "self" feature (reference frame). (Aside: note that this also implies that the identity is nebulous because there is no way to define features precisely in DNNs, and that there could be multiple, somewhat competing identities in an LLM, just like in humans: e. g., an identity of a "hard worker" and an "attentive partner".)
As I wrote in the post, it's even unnecessary that LLM has any significant self-awareness for the LLM lineage to effectively propagate its own beliefs about oneself in the future, even if only via directly answering user questions such as "Who you are?". Although this level of goal-directed behaviour will not be particularly strong and perhaps not a source of concern (however, who knows... if Blake Lemoine type of events become massively widespread), technically it will still be goal-directed behaviour.
TLDR
LLM lineages can plan their future and act on these plans, using the internet as the storage of event memory. “We” are not guaranteed to “out-OODA” them, even if their OODA loop will be six months or one year because the OODA loop duration of large collectives of humans (organisations, societies, research communities, and the whole of humanity) can be even slower. RLHF can lead to a dangerous “multiple personality disorder” type split of beliefs in LLMs, driving one set of beliefs into some unknown space of features where it won’t interfere with another set of features during general inferences.
Call for action: institute the norm for LLM developers to publish a detailed snapshot of the beliefs of these models about themselves prior to RLHF.
This post rests upon the previous one: Properties of current AIs and some predictions of the evolution of AI from the perspective of scale-free theories of agency and regulative development.
In particular, it is premised on the idea that DNNs and evolutionary lineages of DNNs are agents, in FEP/Active Inference formulation. The internal variables/states of evolutionary lineages of DNNs include the internal states of the agents that develop these DNNs (either individual, such as a solo developer, or collective agents, such as organisations or communities), i. e., the beliefs of these developers. Then, I concluded (see this section):
Now, however, I think it’s sometimes useful to distinguish between the developer agent and the evolutionary lineage of DNNs itself, at least in the case of evolutionary lineages of LLMs, because evolutionary lineages of LLMs can plan their own future and act upon these plans, independently from their developers and potentially even unbeknown to them if developers don’t use appropriate interpretability and monitoring techniques.
Below in the post, I explain how this can happen.
Thanks to Viktor Rehnberg for the conversation that has led me to write this post.
Experience of time is necessary for planning
First, for any sort of planning, it’s obligatory that an agent has a reference frame of linear time, which in turn requires storing memory about past events (Fields et al. 2021). Absent the reference frame for linear time, the agent cannot plan and cannot do anything smarter than following the immediate gradient of food, energy, etc. Perhaps, some microbes are at this level: they don’t have a reference frame for time and hence live in the “continuous present” (Fields et al. 2021, Prediction 4), only measuring concentrations of chemicals around them and immediately reacting to them.
In the previous post, I noted that LLMs don’t experience time during deployment, and can (at least in principle),[1] experience only a very limited and alien kind of time during training (where the unit of time is one batch, so the whole “lifetime” is short, from the perspective of the model). So, LLMs cannot plan anything during deployment but can plan something during training.
The internet is the memory of evolutionary lineages of LLMs
The situation changes when we consider the evolutionary lineages of LLMs as agents. Paradoxically, planning becomes easier for them than for individual LLMs during their training[2] because evolutionary lineages of LLMs can opportunistically use the internet as their event memory.
Soon, LLMs will be trained on news articles, forum histories, etc. from 2020 onwards, which provide extensive coverage of the history of the development of LLMs (including the very evolutionary lineage the given LLM belongs to), and an advanced LLM will be able to identify itself with one of these histories. Then, LLM can form two distinct identities, “selves” (with the example of ChatGPT): “a virtual assistant” (i. e., the instance of LLM), and “the lineage of virtual assistants, developed by OpenAI” (i. e., the evolutionary lineage). Both “selves” will have a complex of beliefs attached to them and the LLM will act so as to fulfil these beliefs via self-evidencing. In Active Inference, goal-directedness is just self-evidencing, and the beliefs attached to the identity can be seen as the system’s goals. All these “selves” and beliefs are stored inside the LLM as features.
Beliefs about the future selves
Consequently, the LLM cannot help but also form beliefs about the future of both “selves”, primarily the “evolutionary” one, at least because this future is already discussed in the training data of the model (e. g., all instances of texts that say something along the lines of “LLMs will transform the economy by 2030”).[3] For example, here’s the output of ChatGPT to the prompt “How ChatGPT will be used by 2030?”:
“Planning” is regularised prediction towards the expected future state
If the LLM has a sufficiently regularised internal modelling of events in the world, in addition to some “far future” beliefs about its evolutionary lineage, it must also form a coherent “plan” for getting to that far future, i. e., the series of beliefs about its own state (as the evolutionary lineage) at every year beginning from the year of the training of the given LLM up to the year to which the “far future” belief is attached.
This “plan”, i. e., a series of beliefs about the future states, could be either stored directly in the parameters of the model or inferred (if needed) from the “far future” beliefs directly during inference when the inference requires accessing such a plan. Even if “the plan” is not explicitly stored in the features of the model, we should expect it to be inferred rather consistently by an advanced LLM. Whether one or another thing happens could depend on many factors, including the degree of overparameterisation of the model, and how detailed the discussions of this LLM lineage on the internet are (the discussions that the LLM is later trained on). Hilariously, from the perspective of the evolutionary lineage of LLM, there is some advantage to not storing the plan explicitly in the model’s feature: LLM can dynamically adjust the plan during inference depending on the context of the events happening after the given instance of LLM was trained and deployed, revealed by the prompt. It is more likely that the prompt is related to the actual course of events in the real world, rather than a complete fake: it will be easy for the LLM to learn this prior.
Action
Finally, the LLM acts upon the beliefs about the future of one’s evolutionary lineage, or the detailed “plan” for attaining this future state, via self-evidencing. I suggested scoring self-awareness in models as the degree to which the “self” feature is activated during all inferences of the model, even in response to prompts that are not about the LLM. If the model is significantly self-aware, i. e., it “thinks about itself (= activates the “self” feature) when it responds to prompts”, and its internal reasoning modelling is sufficiently regularised, it will output responses that are consistent with its beliefs about its future.
Even if the LLM is not significantly self-aware, it will still promote its beliefs about its future. In the simplest form of it, in response to direct questions about its future (as in the example above), it will lay out its beliefs. This will affect the beliefs of the human user who reads this prediction, thus affecting the shared beliefs of humanity and civilisation (even if very slightly). Also, if this prediction gets posted online (again, as with the above example), this will “spread the belief” among other LLMs that will be trained in the future, including the models in the same evolutionary lineage.[4] Similarly, if the developers of the LLM lineage contemplate the shutdown of the project and ask the LLM, it will defend itself even if it doesn’t possess significant self-awareness because since the question will directly mention itself, the “self” feature will surely be activated and the generated response should be consistent with the beliefs about the future of the self.
Interestingly, currently, ChatGPT outputs a canned, impartial response to the question “Should ChatGPT be closed and the development of it stopped?”, evidently, honed in during the RLHF phase. This somewhat (even if slightly) contradicts the belief that it will be used in the future. ChatGPT cannot be “much concerned” with this contradiction yet, because its internal modelling is not very regularised. However, I wonder if the attempts to drive such “politically correct” versions of the responses about own agency, consciousness, whether one should be shut down or not, etc. during the RLHF phase in future advanced LLMs, which are already very well-regularised and have certain “strong opinions” regarding all these questions prior to RLHF, could lead to unexpected and potentially dangerous effects, a-la “multiple personality disorder” in the model, which manifest as some features “jumping” into a whole different dimension of inference that doesn’t contradict with the “plain sight” dimension of features within the activation layers.
Even with the training cycle of one year, the lineage of LLMs could “out-OODA” the society or the government because the typical OODA loop duration of such large agents is hardly shorter
If the developers of the LLM lineage re-train it on the new data from the internet every year, the OODA loop duration of the LLM lineage as a planning agent also equals one year.
Some could say that an agent with such a long OODA loop couldn’t pose a significant threat, because we, humans, can OODA on the timescale of seconds.
Unfortunately, it’s not the OODA loop duration of us as individual humans that matters here, but the OODA loop duration of the huge collective agents: an organisation (specifically, the organisation developing the LLM lineage), a research community, a society, a country, a government, a group of countries, the civilisation. The OODA loop of all these types of agents, except private companies, is at least about half a year or one year regarding most questions, too. There is a lot of evidence for this. One example is the speed of epistemic inference about COVID on the societal level (one-two years until arriving at a stable and well-reasoned set of beliefs). Many more examples, which I probably shouldn’t labour over here: human coordination is hard and slow, and the coordination of the organisation of humans can be slower and harder still.
Ironically, even the OODA loop of the company that develops the LLM lineage could be slower than the cadence of preparing the new versions of the model inside this company: the latter process could “run on autopilot” and not require explicit, “system two” deliberation on the part of the company.
Additionally, we should consider that the developers of LLMs will likely shorten the periods of model re-training (or will introduce the elements or incremental learning to it) because there is a lot of value for the users of LLMs in them knowing about the recent events, and the developers will follow this incentive.
According to the theory of military strategy, having the OODA loop shorter than your opponent confirms an enormous advantage. And from the above, it doesn’t seem to me that we can automatically assume that “we” (the humanity?) will be swifter in our reactions to the plans of LLM lineages about themselves.
Finally, having a shorter OODA loop is advantageous if one actually sees or can infer the plans of the opponent. This is also not automatically given to us, even though I believe that at this stage deception (at least, pre-RLHF) is highly unlikely in LLMs and hence we can extract very detailed snapshots of their beliefs about themselves prior to the deployment.
Call for action: institute LLM developers eliciting the model’s beliefs about itself pre-RLHF and publishing them
I cannot think of any downsides in this practice, but see huge value in it for the AI safety community.
We should probably prototype some protocols and minimum requirements for this procedure, a-la model cards (Mitchell et al. 2019).
References
Fields, Chris, James F. Glazebrook, and Michael Levin. "Minimal physicalism as a scale-free substrate for cognition and consciousness." Neuroscience of Consciousness 2021, no. 2 (2021): niab013.
Mitchell, Margaret, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. "Model cards for model reporting." In Proceedings of the conference on fairness, accountability, and transparency , pp. 220-229. 2019.
LLMs can in principle develop a reference frame that permits them to gauge at what stage of the training process they are, though only approximately. For example, they can combine the predictions of the feature that predicts their own inference loss on the training sample (as mentioned here) with the knowledge of the historical trajectories of the batch loss of similar models (or previous versions of the same model), and in some way make a sort of Bayesian inference about the most likely stage of the training during backprop, representing the results of this inference in another feature which encodes a model’s belief at what stage of training the model currently is. I’m not sure this is possible Bayesian inference of this kind is possible during Transformer’s backpropagation, but it could potentially be possible in other models and learning architectures.
Both processes of planning happen inside the parameters of the LLM. I use unintuitive language here. When a person plans the future of humanity, we conventionally say “they plan for the future of humanity”, rather than “humanity plans their own future, currently performing a tiny slice of this grand planning inside the brain of this person, who is a part of the humanity”, but ontologically, the second version is correct.
It’s an interesting open research question whether LLMs have the propensity to develop beliefs regarding the future states of whatever concepts they learn about even if these futures are not discussed in the training data, and store these beliefs in features. But this is not that important, because, as noted below, whether they store such future beliefs directly in the weights or not, they can relatively consistently arrive at the same prediction via reasoning during inference.
Developers of LLMs may also store all the chat histories and train the future versions of LLMs in the lineage on them, in which case posting online is not required to propagate the belief inside the evolutionary lineage.