This is a special post for quick takes by Julian Bradshaw. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Gemini 2.5 Pro just beat Pokémon Blue. (https://x.com/sundarpichai/status/1918455766542930004)
A few things ended up being key to the successful run:
- Map labeling - very detailed labeling of individual map tiles (including identifying tiles that move you to a new location ("warps" like doorways, ladders, cave entrances, etc.) and identifying puzzle entities)
- Separate instances of Gemini with different, narrower prompts - these were used by the main Gemini playing the game to reason about certain tasks (ex. navigation, boulder puzzles, critique of current plans)
- Detailed prompting - a lot of iteration on this (up to the point of ex. "if you're navigating a long distance that crosses water midway through, make sure to use surf")
For these and other reasons, it was not a "clean" win in a certain sense (nor a short one, it took over 100,000 thinking actions), but the victory is still a notable accomplishment. What's next is LLMs beating Pokémon with less handholding and difficulty.
My understanding is they were made by the dev, and added throughout the run, which is kind of cheating.
I think it's not cheating in a practical sense, since applications of AI typically have a team of devs noticing when it's tripping up and adding special handling to fix that, so it's reflective of real-world use of AI.
But I think it's illustrative of how artificial intelligence most likely won't lead to artificial general agency and alignment x-risk, because the agency will be created through unblocking a bunch of narrow obstacles, which will be goal-specific and thus won't generalize to misalignment.
This seems, frankly, like a bizarre extrapolation. Are you serious? The standard objection is of course that if humans have general agency, future AI systems can have it too, and indeed to a greater degree than humans.
Detailed prompting - a lot of iteration on this (up to the point of ex. "if you're navigating a long distance that crosses water midway through, make sure to use surf")
I take it the final iteration isn't published anywhere yet? Wasn't able to find it.
Seems like the most important part for deciding how to update on that.
Also, it’s worth checking if the final version can actually beat the whole game. If it was modified on the fly, later modifications may have broken earlier performance?
This is kinda-sorta being done at the moment, after Gemini beat the game, the stream has just kept on going. Currently Gemini is lost in Mt. Moon, as is tradition. In fact, the fact that it already explored Mt. Moon earlier seems to be hampering it (no unexplored areas on minimap to lure it towards the right direction).
I believe the dev is planning to do a fresh run soon-ish once they've stabilized their scaffold.
Apparently Claude 4 Opus hasn't gotten further in Pokémon Red than Claude 3.7 Sonnet did. Just three gym badges obtained.
This is a surprising failure, and probably why Anthropic hasn't released an updated version of their Pokémon benchmark. Instead, they just made some comments about improved long-term planning ability, which apparently doesn't translate into measurable results?
Source: Wired reporter Kylie Robinson asked about it in-person to ClaudePlaysPokemon developer and Anthropic employee David Hershey: https://x.com/kyliebytes/status/1925617856449757364
That really is surprising, especially given that the announcement includes the following:
Claude Opus 4 also dramatically outperforms all previous models on memory capabilities. When developers build applications that provide Claude local file access, Opus 4 becomes skilled at creating and maintaining 'memory files' to store key information. This unlocks better long-term task awareness, coherence, and performance on agent tasks—like Opus 4 creating a 'Navigation Guide' while playing Pokémon.
I'd pretty much assumed they fine-tuned on the Pokémon task and it was going to be just about one-shotting the game. Weird.
I found that section very suspicious because it omitted any statement about actual performance, and I guess now we know why.
This seems in line with my longer timelines hypothesis. Perhaps it roughly undoes the update on AlphaEvolve, which I wasn’t sure how to interpret.
Of course the METR evaluation will contain more signal.
Yeah I feel like they came up with something nice to say while eliding the "no further progress" issue.
Weirdly, while the announcement talks about creating and maintaining multiple "memory files", the new public ClaudePlaysPokemon stream has Claude Opus 4 using just a single memory file which it doesn't even create. Apparently this is "much better" than the setup Claude 3.7 Sonnet used which let it create and maintain as many files at it wanted (usually to its detriment).
(source: this doc David Hershey just published on the new harness for the stream)
One other interesting tidbit I'll throw in from the stream:
claudestans: @ClaudePlaysPokemon you mentioned before that there was a personality change from e.g. 3.5 sonnet to 3.7 (more persistent, less giving up etc). Have you noticed anything about opus 4 in terms of personality?
ClaudePlaysPokemon: Opus is so much better at keeping track of things that it gets more distressed when it can't figure things out! So I need to convince it more that nothing is wrong, which I find quite interesting!
ClaudePlaysPokemon: like it will be very aware that it has taken 100 steps to solve something and it finds that very frustrating
Huh, indeed interesting. IIRC, one of the suggested problems with the previous models was the lack of boredom: that they're perfectly capable of doing something in a loop forever where a human would've gotten frustrated and done something random that might've ended up helping. Sounds like Opus 4 is different in that regard...?
That's a big performance limitation for LLMs for sure, but Claude 3.7 Sonnet got two more badges than Claude 3.6 Sonnet. Pure reasoning improvements have led to more badges in the past.
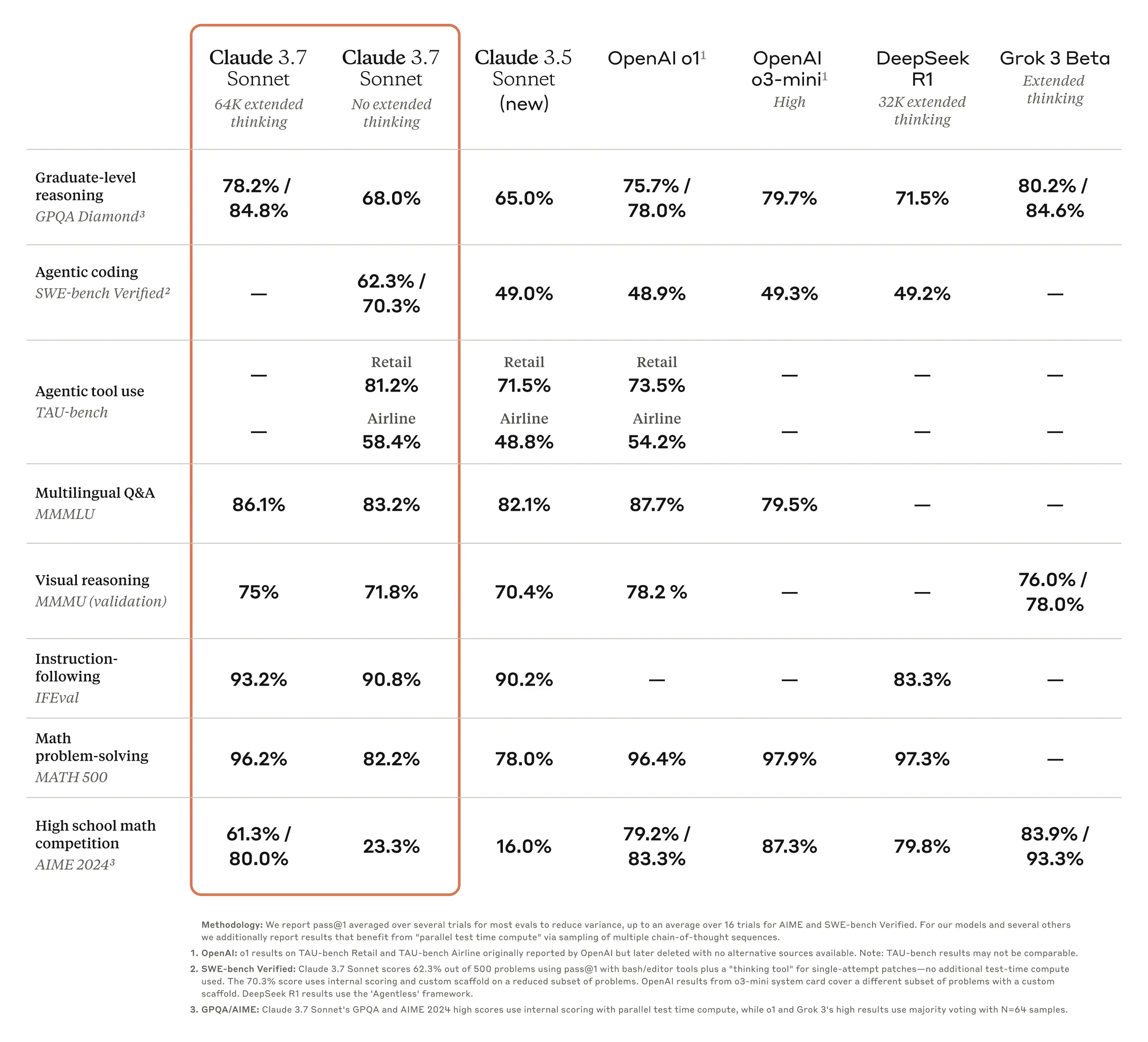
I assume you mean MMMU? Looks like a 70.4% -> 75% score improvement on the benchmark last jump, compared to just a 75% -> 76.5% score improvement this time. I don't think that's a big difference, but I was wrong to say the improvement was "pure" reasoning improvements, my bad.
Indeed, it seems Claude 4 is not that much better than Claude 3.7 sonnet at visual reasoning, in fact Claude-4 sonnet is worse at visual reasoning than Claude 3.7 sonnet (though Claude 4 Opus is better). So extra not so surprising, and an indication that this isn't really what Anthropic is focusing on at the moment (likely a good call).
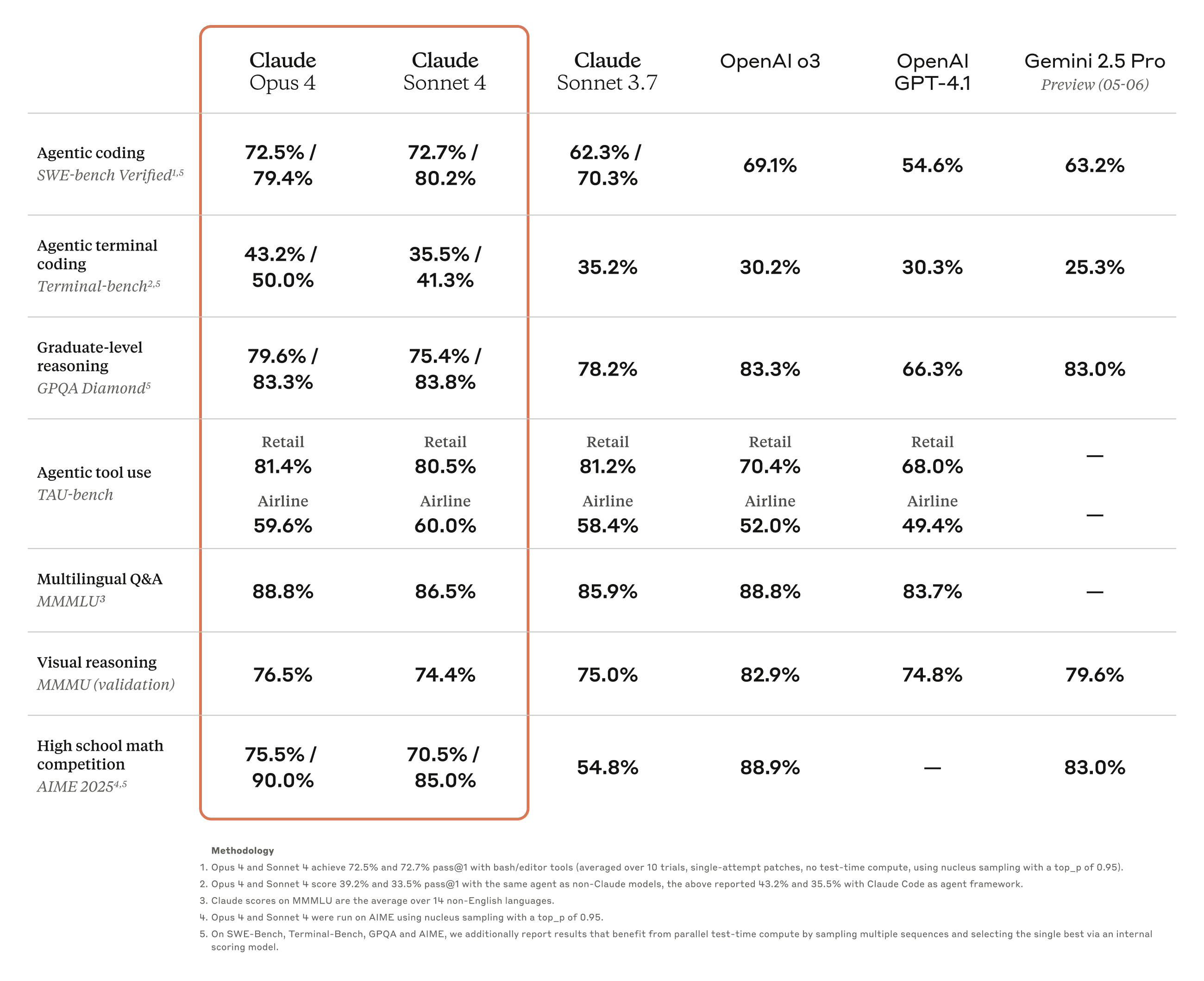
Claude Sonnet 4 is still better than Claude 3.7 Sonnet without Extended Thinking. Given that 4 doesn't seem to have an Extended Thinking mode, I'm not sure it's really a performance degradation.
Claude 4 does have an extended thinking mode, and many of the Claude 4 benchmark results in the screenshot were obtained with extended thinking.
From here, in the "Performance benchmark reporting" appendix:
Claude Opus 4 and Sonnet 4 are hybrid reasoning models. The benchmarks reported in this blog post show the highest scores achieved with or without extended thinking. We’ve noted below for each result whether extended thinking was used:
- No extended thinking: SWE-bench Verified, Terminal-bench
- Extended thinking (up to 64K tokens):
- TAU-bench (no results w/o extended thinking reported)
- GPQA Diamond (w/o extended thinking: Opus 4 scores 74.9% and Sonnet 4 is 70.0%)
- MMMLU (w/o extended thinking: Opus 4 scores 87.4% and Sonnet 4 is 85.4%)
- MMMU (w/o extended thinking: Opus 4 scores 73.7% and Sonnet 4 is 72.6%)
- AIME (w/o extended thinking: Opus 4 scores 33.9% and Sonnet 4 is 33.1%)
On MMMU, if I'm reading things correctly, the relative order of the models was:
- Opus 4 > Sonnet 4 > Sonnet 3.7 in the no-extended-thinking case
- Opus 4 > Sonnet 3.7 > Sonnet 4 in the extended-thinking case
Gemini 2.5 Pro (05-06) version just beat Pokémon Blue for the second time, taking 36,801 actions/406 hours. This is a significant improvement over the previous run, which used an earlier version of Gemini (and a less-developed scaffold) and took ~106,500 actions/816 hours.
For comparison, Claude 3.7 Sonnet took ~35,000 actions to get just 3 badges, and the aborted public run also only got 3 badges after over 200,000 actions. However, most of the difference is that Gemini is using a more advanced scaffold.
Gemini still generally makes boneheaded decisions. It took 7 tries to beat the Elite Four and Champion this time, being less overlevelled. Mistakes included:
- Re-solving Victory Road for many hours after failures, despite being able to fly straight to the Elite Four after making it there the first time.
- Not buying proper healing items/thinking the "Full Heal" item actually heals its Pokémon. (This is an infamously misleadingly-named item, it just cures status conditions. Still, Gemini knows the real effect if you ask it directly, it just doesn't apply that knowledge consistently.)
- Not using available revive items to bring back its only strong Pokémon, even after having just used them previously. (threw an attempt where the Champion was down to their final Pokémon once like that)
Anyway, not too much new info here. The newer models (latest Gemini, o3, and Claude 4 Opus) are only somewhat better at Pokémon. The effect scaffolds have on performance does say something about how much low-hanging fruit there is for current-LLM implementation: they can be a lot more effective when given the right tools/prompting. But, we already knew that.
o3 beat Pokémon Red today, making it the second model to do so after Gemini 2.5 Pro (technically Gemini beat Blue).
It had an advanced custom harness like Gemini's, rather than Claude's basic one. Hard to compare runs because its harness is different from Gemini's, but Gemini's most recent run finished in ~406 hours / ~37k actions, whereas o3 finished in ~388 hours / ~18k actions. (there are some differences in how actions are counted) Claude Opus 4 has yet to achieve the 4th badge on its current ~380 hour / 54k actions run, but it's very likely it could beat the game with an advanced harness.
Re: biosignatures detected on K2-18b, there's been a couple popular takes saying this solves the Fermi Paradox: K2-18b is so big (8.6x Earth mass) that you can't get to orbit, and maybe most life-bearing planets are like that.
This is wrong on several bases:
- You can still get to orbit there, it's just much harder (only 1.3g b/c of larger radius!) (https://x.com/CheerupR/status/1913991596753797383)
- It's much easier for us to detect large planets than small ones (https://exoplanets.nasa.gov/alien-worlds/ways-to-find-a-planet), but we expect small ones to be common too (once detected you can then do atmospheric spectroscopy via JWST to find biosignatures)
- Assuming K2-18b does have life actually makes the Fermi paradox worse, because it strongly implies single-celled life is common in the galaxy, removing a potential Great Filter
Edit 5/24/25: Also it turns out the biosignatures might have just been noise anyway.
Still-possible good future: there's a fast takeoff to ASI in one lab, contemporary alignment techniques somehow work, that ASI prevents any later unaligned AI from ruining world, ASI provides life and a path for continued growth to humanity (and to shrimp, if you're an EA).
Copium perhaps, and certainly less likely in our race-to-AGI world, but possible. This is something like the “original”, naive plan for AI pre-rationalism, but it might be worth remembering as a possibility?
Pure vibecoding against a difficult problem is surprisingly addictive, I learned recently: staying up until 2 or 3am waiting for Claude Code limits to reset, making failed attempts 22 to 31 with Codex on a weekend afternoon I meant to spend out hiking.
("Pure vibecoding" -> you don't understand the code produced or why the LLM makes the decisions it does. I don't find using AI agents to develop software I understand to be addictive.)
The causes are obvious upon consideration: the inputs are routine ("okay, please continue") while the outputs are unpredictable + potentially valuable (broken mess vs. working software). Watching the AI reason and act and make tangible changes is intriguing and exciting. You have what feels like enough control to affect the outcome—even worse than that, you really do have enough control to affect the outcome, though not consistently. A single "win" on the next roll may make up for all invested time and money. And so on.
I'm not saying pure vibecoding is bad, though. Like many addictive activities, it can be fun and even rewarding, and unlike a lot of gambling it isn't rigged against you. But do keep an eye out for yourself!