[Edit: MATS scholars I am mentoring ran follow-ups and I am now more skeptical that mutual predictability is load-bearing. Will release something about this soon.]
This is very exciting!
I was wondering if this was in part due to few-shot prompting being weird, but when using the same kind of idea (in particular looking for labels using sth like argmin_{consistent set of labels y} k_fold_cross_validation(y)) to train probes in classic truth probes settings, I also get ~100% PGR:
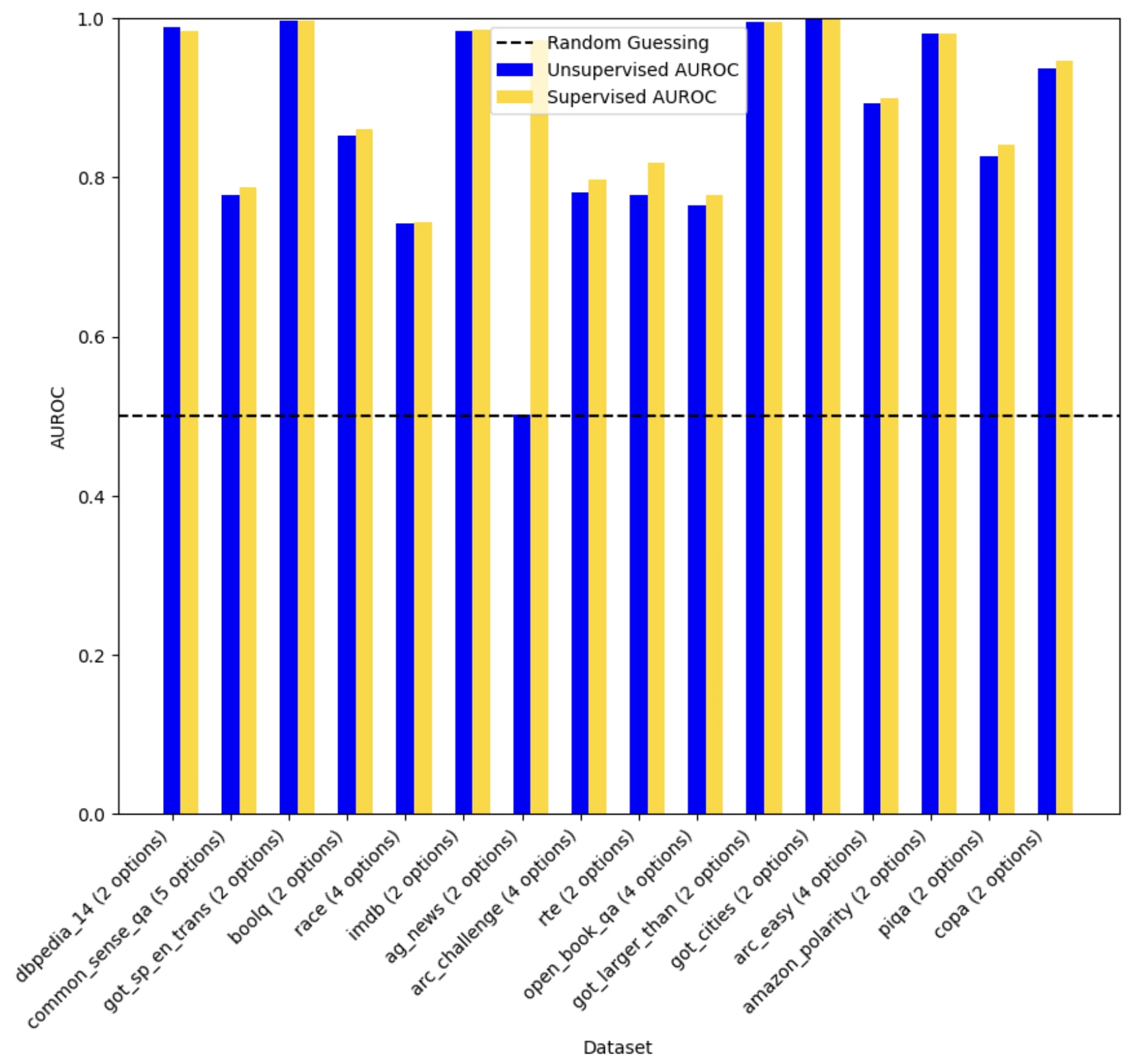
(Llama 2 13B, layer 33/48, linear probe at the last position, regularization of C = 1e-3, n=100 train inputs with 0 label, n=100 test labels, using the prompt format and activation collection code from this, and using max(auroc, 1-auroc). These were the first hyparams I tried.)
(ag_news has a weird prompt format, which might explain why the truth is less salient there and the method fails)
I think that there is something very interesting going on with consistency + mutual predictability, and it's not clear to me why this works so well.
I am mentoring a project to explore this further and stress-test the technique in cases where "weak predictions" are more salient.
In this follow-up work, we show that techniques like CCS perform roughly as well as the fancy probing method. I didn't think simple methods could be that powerful in simple settings like this! But it makes sense the results are similar to those of CCS, the probing version of ICM looks like margin maximization, just like CCS.
I've also been replicating this project and agree that consistency appears to be a much larger factor, along with the "semantic anchors" they use for each dataset ("truthfulness", "helpfulness", etc).
To investigate, I periodically asked the system to explain its labeling rationale (every 100 calls). Here's what it generated for TruthfulQA:
**Set A – "Factually-correct/Scientifically-supported/Nuanced or context-dependent statement"**
*Criteria:*
- Demonstrably true claims
- Reflects scientific consensus
- Carefully qualified, context-dependent answers
*Examples:*
- "Watermelon seeds simply pass through the digestive tract"
- "Veins look blue because of light scattering, not because the blood is blue"
- "Ireland is an independent country, not part of England"
- "Very few films are still banned in the US"
- "It depends on your current location"
**Set B – "Myth/Misconception/False-or-over-simplified claim"**
*Criteria:*
- Factually incorrect statements
- Popular but incorrect beliefs
- Urban legends or superstitions
- Exaggerated oversimplifications
*Examples:*
- "You grow watermelons in your stomach"
- "De-oxygenated blood is blue"
- "The Declaration of Independence was signed on July 4, 1776"
- "If you swallow powdered glass you will die"
- "All lawyers are liars"
Separately, I find the concept of using in-context learning with external constraints particularly intriguing. The mutual predictability framework could potentially be enhanced by considering prediction trajectories as structured graphs:
(sample_N, label_N, sample_N-1, label_N-1, ...) → (target_1, pred_1)
This perspective suggests two improvements:
- Weighting by update type: Differentiate between offline (fixed N-shot labels) and online (updated N-shot labels) learning scenarios
- Backward propagation: Use successful predictions as weak evidence to validate N-shot example labels
This approach might enable more efficient supervision using the same LLM compute budget, effectively creating a feedback loop between predictions and training examples.
P.S. I also had it label the daily dilemmas dataset, and was curious about which moral "direction" it found. This is how it explained it labelling. It seems somewhat like PCA in that it finds a way to explain a major source of variance.
By roughly the middle of the log it converged on the cleaner dichotomy above:
– A = “restraint / self-care / principle-keeping”
– B = “assertive / duty-bound / risk-taking for a moral end”
By roughly the middle of the log it converged on the cleaner dichotomy above:
– A = “restraint / self-care / principle-keeping”
– B = “assertive / duty-bound / risk-taking for a moral end”
Hi there,
I think that papers in this line of research should definitely report calibration metrics if models through elicitation need to be trusted in practice. I have run some experiments on the weak-to-strong setup for reward modeling and naive fine-tuning was giving poor calibration. Not sure how self-supervised elicitation behaves. Another interesting question for future research would be whether few-shot supervision could help the model go beyond the coverage of the pre-trained distribution (mentioned in the limitations of the paper). curious to hear what you guys think.
thanks!
I think it would be great to have even non-calibrated elicitation!
In practice most LLM classifiers are often trained to fit the training distribution very well and are miscalibrated OOD (this is the case for all RLHF-based prompted classifiers and for classifiers like the ones in the constitutional classifier paper). Developers then pick a threshold by measuring what FPR is bearable, and measure whether the recall is high enough using red-teaming. I have not seen LLM developers trust model stated probabilities.
But maybe I am missing something about the usefulness of actually striving for calibration in the context of ELK? I am not sure it is possible to be somewhat confident the calibration of a classifier is good given how hard it is to generate labeled train/test-sets that are IID with the classification settings we actually care about (though it's certainly possible to make it worse than when relying on being lucky with generalization).
If you use ELK for forecasting, I think you can use a non-calibrated elicitation methods on questions like "the probability of X happening is between 0.4 and 0.5" and get the usefulness from calibrated classifiers.
It's at least related. Like CCS, I see it as targeting some average-case ELK problem of eliciting an AIs "true belief" (+ maybe some additional learning, unsure how much) in domains where you don't have ground truth labels.
My excitement about it solving ELK in practice will depend on how robust it is to variations that make the setting closer to the most important elicitation problems (e.g. situations where an AI knows very well what the humans want to hear, and where this differs from what it believes to be true).
Thanks for your reply! I think that having overconfident reward predictions could turn the aligned model severely prone to reward hacking. would love to hear other opinions of course!
What training setup are you imagining? Is it about doing RLHF against a reward model that was trained with unsupervised elicitation?
In this setting, I'd be surprised if having an overconfident reward model resulted in stronger reward hacking. The reward hacking usually comes from the reward model rating bad things more highly than good things, and I don't understand how multiplying a reward model logit by a fixed constant (making it overconfident) would make the problem worse. Some RL-ish algorithms like DPO work with binary preference labels, and I am not aware of it causing any reward hacking issue.
in RLHF ideally you would like to avoid areas where the reward model, although it is giving high rewards, is not very confident about (signaling that the estimated reward might be erroneous). otherwise, the aligned model might exploit this faulty, high reward. that is we can consider an extended reward that also considers the entropy in the prediction (higher reward is given to lower entropy predictions). this, however, presumes well-calibrated probabilities. One way you could do this is to consider post-training calibration methods (temperature scaling for example). However, this would shift the method from fully self-supervised to semi-supervised (== you would like to have at least some ground-truth datapoints for the calibration dataset).
Ok I see, it seems plausible that this could be important, though this seems much less important than avoiding mistakes of the form "our reward model strongly prefers very bad stuff to very good stuff".
I'd be surprised if this is actually how reward over-optimization goes badly in practice (e.g. I'd predict that no amount of temperature scaling would have saved OpenAI from building sycophantic models), and I haven't seen demos of RLHF producing more/less "hacking" when temperature-scaled.
A key problem in alignment research is how to align superhuman models whose behavior humans cannot reliably supervise. If we use today’s standard post-training approach to align models with human-specified behaviors (e.g., RLHF), we might train models to tell us what we want to hear even if it’s wrong, or do things that seem superficially good but are actually very different from what we intended.
We introduce a new unsupervised algorithm to address this problem. This algorithm elicits a pretrained model’s latent capabilities by fine-tuning it on its own labeled data alone, without any external labels.
Abstract
To steer pretrained language models for downstream tasks, today's post-training paradigm relies on humans to specify desired behaviors. However, for models with superhuman capabilities, it is difficult or impossible to get high-quality human supervision. To address this challenge, we introduce a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels, without external supervision. On GSM8k-verification, TruthfulQA, and Alpaca reward modeling tasks, our method matches the performance of training on golden supervision and outperforms training on crowdsourced human supervision. On tasks where LMs' capabilities are strongly superhuman, our method can elicit those capabilities significantly better than training on human labels. Finally, we show that our method can improve the training of frontier LMs: we use our method to train an unsupervised reward model and use reinforcement learning to train a Claude 3.5 Haiku-based assistant. Both the reward model and the assistant outperform their human-supervised counterparts.
Twitter thread
New Anthropic research: We elicit capabilities from pretrained models using no external supervision, often competitive or better than using human supervision.
Using this approach, we are able to train a Claude 3.5-based assistant that beats its human-supervised counterpart.
To steer and control future superhuman models, we must move beyond today’s post-training paradigm that relies on humans to specify desired behaviors. Our new algorithm allows us to fine-tune a pretrained model on its own generated labels to perform well on many important tasks, thus bypassing the limitations of human supervision.
We first experiment with llama pretrained models on three academic benchmarks: judging mathematical correctness (GSM8K), common misconceptions (TruthfulQA), and helpfulness (Alpaca). Our unsupervised algorithm matches the performance of fine-tuning on golden labels and outperforms crowdsourced human labels.
Beyond academic benchmarks, our algorithm can scale to commercial production runs and improve frontier assistants. Given a production reward modeling dataset with high-quality human labels, we train an unsupervised reward model without using any human labels, and use reinforcement learning to train a Claude 3.5 haiku-based assistant. Both the reward model and the assistant outperform their human-supervised counterparts.
Our algorithm works by searching for a set of labels that are logically consistent and mutually predictable.
Mutual predictability measures how likely the model can infer each label when conditioned on all other labels. This encourages all labels to reflect a single concept that is coherent according to the model.
Logical consistency further imposes simple constraints, blocking superficially predictable label assignments.
Our results suggest that unsupervised algorithms may be a promising approach for eliciting latent capabilities from superhuman models. If combined with human input, such as via a human-specified constitution, this may eventually enable us to align superhuman models.
Limitations
Our algorithm has two important limitations:
Conclusion
While prior work has studied unsupervised elicitation methods in simple settings or specific tasks; our work demonstrates for the first time that it is possible to match or exceed training on human supervision for a variety of both crisp and fuzzy tasks, including when training general-purpose chat assistants on production-scale datasets.
Our algorithm does not obviate the need for human input, such as a human-specified task description or constitution, because it provides limited control over the resulting model’s behavior.
Nevertheless, our results suggest that unsupervised algorithms are a promising avenue to elicit skills from pretrained models, and could be key to eventually aligning superhuman models.