Nicky Case, of "The Evolution of Trust" and "We Become What We Behold" fame (two quite popular online explainers/mini-games) has written an intro explainer to AI Safety! It looks pretty good to me, though just the first part is out, which isn't super in-depth. I particularly appreciate Nicky clearly thinking about the topic themselves, and I kind of like some of their "logic vs. intuition" frame, even though I think that aspect is less core to my model of how things will go. It's clear that a lot of love has gone into this, and I think having more intro-level explainers for AI-risk stuff is quite valuable.
===
The AI debate is actually 100 debates in a trenchcoat.
Will artificial intelligence (AI) help us cure all disease, and build a post-scarcity world full of flourishing lives? Or will AI help tyrants surveil and manipulate us further? Are the main risks of AI from accidents, abuse by bad actors, or a rogue AI itself becoming a bad actor? Is this all just hype? Why can AI imitate any artist's style in a minute, yet gets confused drawing more than 3 objects? Why is it hard to make AI robustly serve humane values, or robustly serve any goal? What if an AI learns to be more humane than us? What if an AI learns humanity's inhumanity, our prejudices and cruelty? Are we headed for utopia, dystopia, extinction, a fate worse than extinction, or — the most shocking outcome of all — nothing changes? Also: will an AI take my job?
...and many more questions.
Alas, to understand AI with nuance, we must understand lots of technical detail... but that detail is scattered across hundreds of articles, buried six-feet-deep in jargon.
So, I present to you:

This 3-part series is your one-stop-shop to understand the core ideas of AI & AI Safety* — explained in a friendly, accessible, and slightly opinionated way!
(* Related phrases: AI Risk, AI X-Risk, AI Alignment, AI Ethics, AI Not-Kill-Everyone-ism. There is no consensus on what these phrases do & don't mean, so I'm just using "AI Safety" as a catch-all.)
This series will also have comics starring a Robot Catboy Maid. Like so:

[...]
💡 The Core Ideas of AI & AI Safety
In my opinion, the main problems in AI and AI Safety come down to two core conflicts:
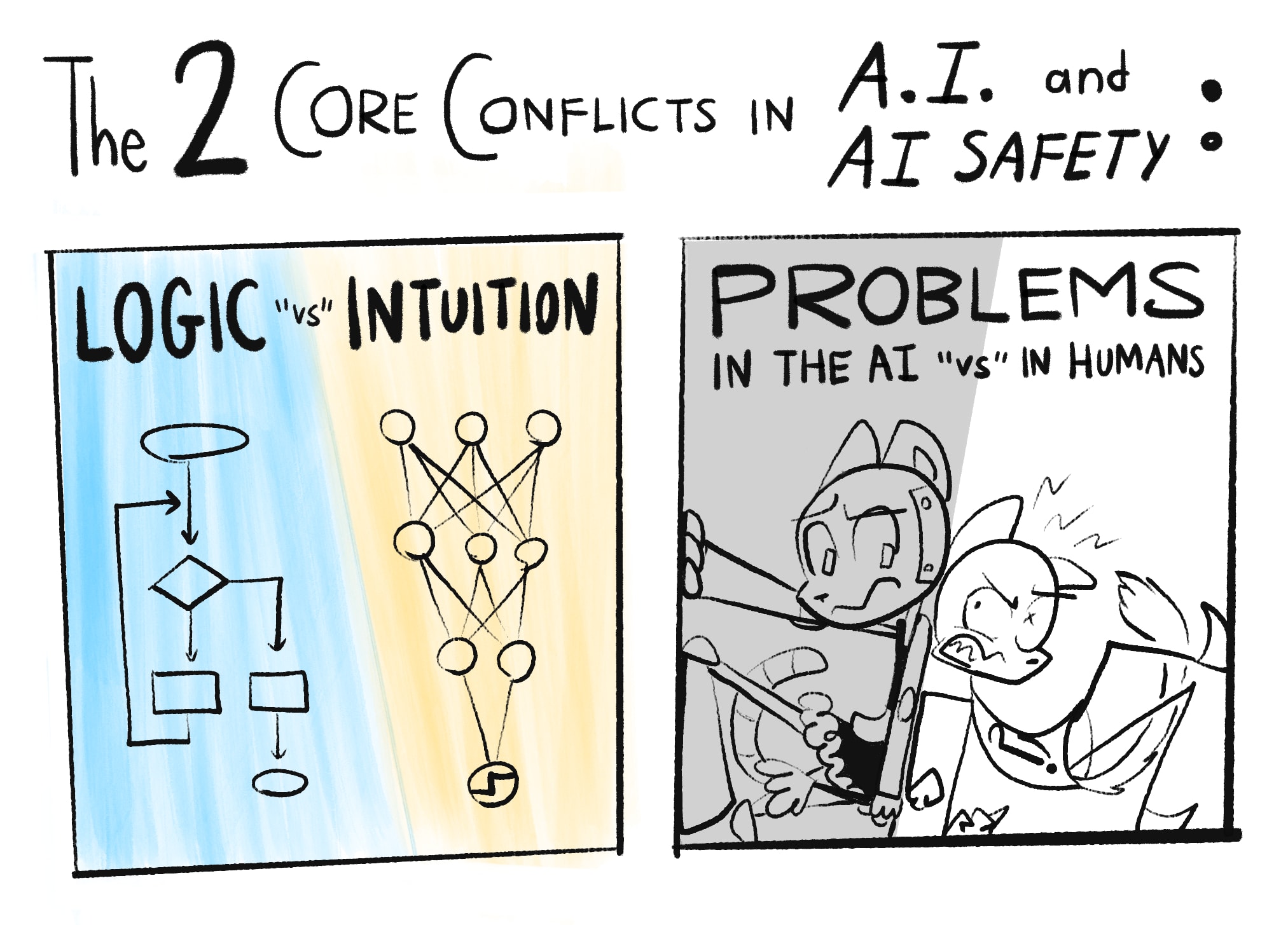
Note: What "Logic" and "Intuition" are will be explained more rigorously in Part One. For now: Logic is step-by-step cognition, like solving math problems. Intuition is all-at-once recognition, like seeing if a picture is of a cat. "Intuition and Logic" roughly map onto "System 1 and 2" from cognitive science.[1]1[2]2 (👈 hover over these footnotes! they expand!)
As you can tell by the "scare" "quotes" on "versus", these divisions ain't really so divided after all...
Here's how these conflicts repeat over this 3-part series:
Part 1: The past, present, and possible futures
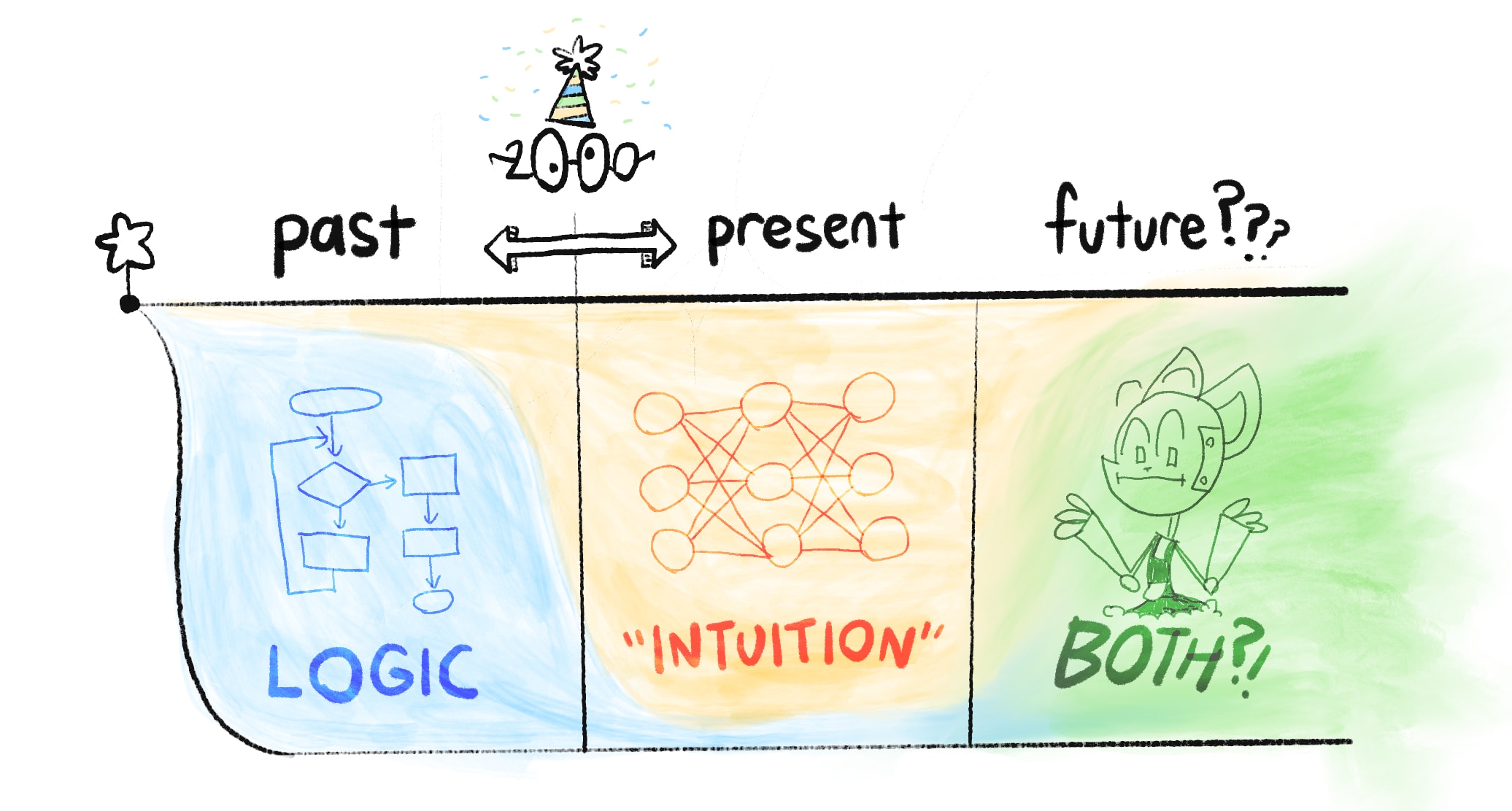
Skipping over a lot of detail, the history of AI is a tale of Logic vs Intuition:
Before 2000: AI was all logic, no intuition.
This was why, in 1997, AI could beat the world champion at chess... yet no AIs could reliably recognize cats in pictures.[3]3
(Safety concern: Without intuition, AI can't understand common sense or humane values. Thus, AI might achieve goals in logically-correct but undesirable ways.)
After 2000: AI could do "intuition", but had very poor logic.
This is why generative AIs (as of current writing, May 2024) can dream up whole landscapes in any artist's style... yet gets confused drawing more than 3 objects. (👈 click this text! it also expands!)
(Safety concern: Without logic, we can't verify what's happening in an AI's "intuition". That intuition could be biased, subtly-but-dangerously wrong, or fail bizarrely in new scenarios.)
Current Day: We still don't know how to unify logic & intuition in AI.
But if/when we do, that would give us the biggest risks & rewards of AI: something that can logically out-plan us, and learn general intuition. That'd be an "AI Einstein"... or an "AI Oppenheimer".
Summed in a picture:
So that's "Logic vs Intuition". As for the other core conflict, "Problems in the AI vs The Humans", that's one of the big controversies in the field of AI Safety: are our main risks from advanced AI itself, or from humans misusing advanced AI?
(Why not both?)
Part 2: The problems
The problem of AI Safety is this:[4]4
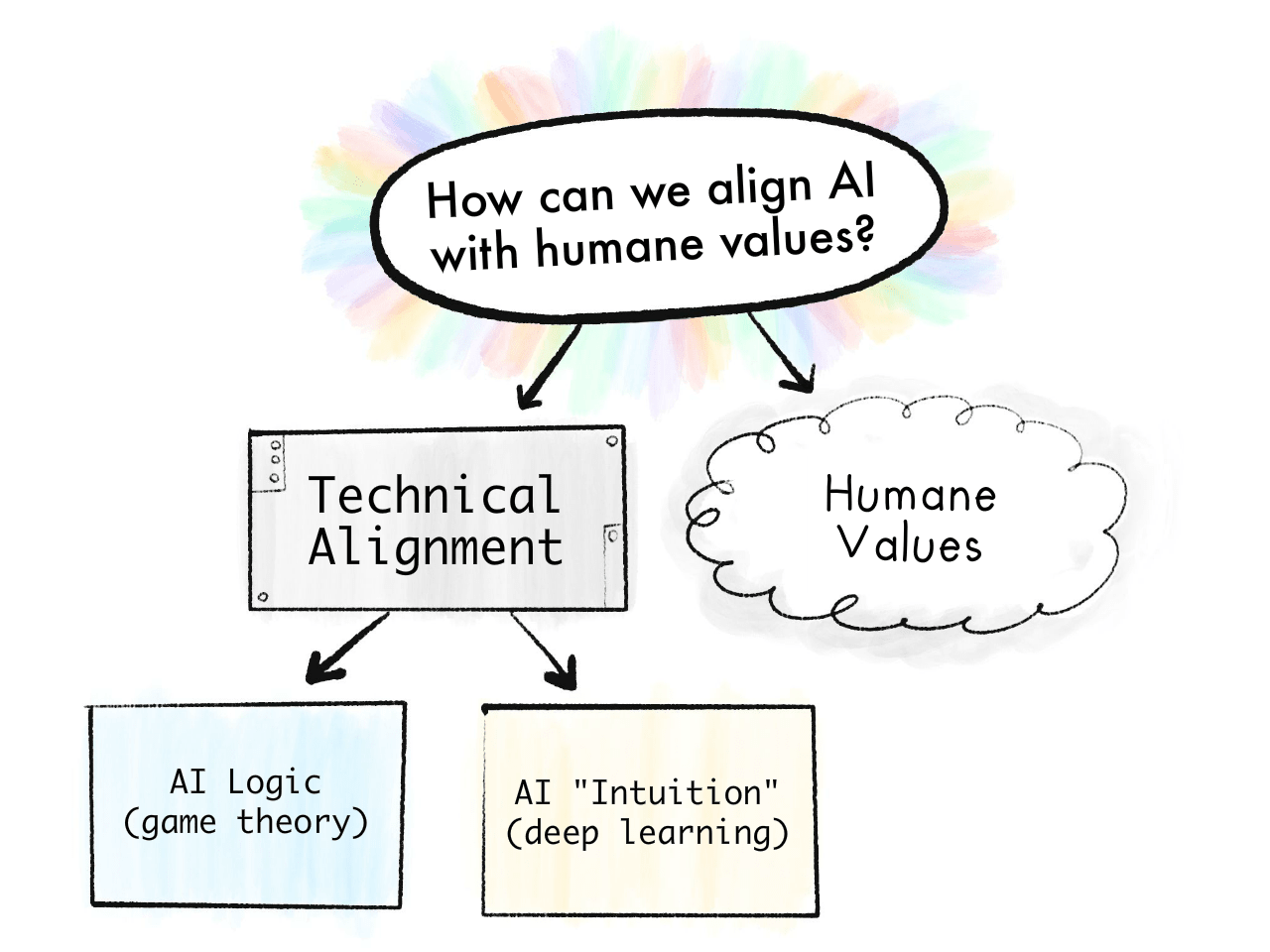
The Value Alignment Problem:
“How can we make AI robustly serve humane values?”
NOTE: I wrote humane, with an "e", not just "human". A human may or may not be humane. I'm going to harp on this because both advocates & critics of AI Safety keep mixing up the two.[5]5[6]6
We can break this problem down by "Problems in Humans vs AI":
Humane Values:
“What are humane values, anyway?”
(a problem for philosophy & ethics)
The Technical Alignment Problem:
“How can we make AI robustly serve any intended goal at all?”
(a problem for computer scientists - surprisingly, still unsolved!)
The technical alignment problem, in turn, can be broken down by "Logic vs Intuition":
Problems with AI Logic:[7]7 ("game theory" problems)
- AIs may accomplish goals in logical but undesirable ways.
- Most goals logically lead to the same unsafe sub-goals: "don't let anyone stop me from accomplishing my goal", "maximize my ability & resources to optimize for that goal", etc.
Problems with AI Intuition:[8]8 ("deep learning" problems)
- An AI trained on human data could learn our prejudices.
- AI "intuition" isn't understandable or verifiable.
- AI "intuition" is fragile, and fails in new scenarios.
- AI "intuition" could partly fail, which may be worse: an AI with intact skills, but broken goals, would be an AI that skillfully acts towards corrupted goals.
(Again, what "logic" and "intuition" are will be more precisely explained later!)
Summed in a picture:

Also, another nitpick:
Humane vs human values
I think there's a harder version of the value alignment problem, where the question looks like, "what's the right goals/task spec to put inside a sovereign ai that will take over the universe". You probably don't want this sovereign AI to adopt the value of any particular human, or even modern humanity as a whole, so you need to do some Ambitious Value Learning/moral philosophy and not just intent alignment. In this scenario, the distinction between humane and human values does matter. (In fact, you can find people like Stuart Russell emphasizing this point a bunch.) Unfortunately, it seems that ambitious value learning is really hard, and the AIs are coming really fast, and also it doesn't seem necessary to prevent x-risk, so...
Most people in AIS are trying to solve a significantly less ambitious version of this problem: just try to get an AI that will reliably try to do what a human wants it to do (i.e. intent alignment). In this case, we're explicitly punting the ambitious value learning problem down the line. Here, we're basically not talking about the problem of having an AI learn humane values, but instead the problem of having it "do what its user wants" (i.e. "human values" or "the technical alignment problem" in Nicky's dichotomy). So it's actually pretty accurate to say that a lot of alignment is trying to align AIs wrt "human values", even if a lot of the motivation is trying to eventually make AIs that have "humane values".[1] (And it's worth noting that making an AI that's robustly intent aligned sure seems require tackling a lot of the 'intuition'-derived problems you bring up already!)
uh, that being said, I'm not sure your framing isn't just ... better anyways? Like, Stuart seems to have lots of success talking to people about assistance games, even if it doesn't faithfully represent what a majority field thinks is the highest priority thing to work on. So I'm not sure if me pointing this out actually helps anyone here?
Of course, you need an argument that "making AIs aligned with user intent" eventually leads to "AIs with humane values", but I think the straightforward argument goes through -- i.e. it seems that a lot of the immediate risk comes from AIs that aren't doing what their users intended, and having AIs that are aligned with user intent seems really helpful for tackling the tricky ambitious value learning problem.