This is a special post for quick takes by [anonymous]. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
(edit 3: i'm not sure, but this text might be net-harmful to discourse)
i continue to feel so confused at what continuity led to some users of this forum asking questions like, "what effect will superintelligence have on the economy?" or otherwise expecting an economic ecosystem of superintelligences (e.g. 1[1], 2 (edit 2: I misinterpreted this question)).
it actually reminds me of this short story by davidad, in which one researcher on an alignment team has been offline for 3 months, and comes back to find the others on the team saying things like "[Coherent Extrapolated Volition?] Yeah, exactly! Our latest model is constantly talking about how coherent he is. And how coherent his volitions are!", in that it's something i thought this forum would have seen as 'confused about the basics' just a year ago, and i don't yet understand what led to it.
(edit: i'm feeling conflicted about this shortform after seeing it upvoted this much. the above paragraph would be unsubstantive/bad discourse if read as an argument by analogy, which i'm worried it was (?). i was mainly trying to express confusion.)
from the power of intelligence (actually, i want to quote the entire post, it's short):
...I keep
As far as I know, my post started the recent trend you complain about.
Several commenters on this thread (e.g. @Lucius Bushnaq here and @MondSemmel here) mention LessWrong's growth and the resulting influx of uninformed new users as the likely cause. Any such new users may benefit from reading my recently-curated review of Planecrash, the bulk of which is about summarising Yudkowsky's worldview.
i continue to feel so confused at what continuity led to some users of this forum asking questions like, "what effect will superintelligence have on the economy?" or otherwise expecting an economic ecosystem of superintelligences
If there's decision-making about scarce resources, you will have an economy. Even superintelligence does not necessarily imply infinite abundance of everything, starting with the reason that our universe only has so many atoms. Multipolar outcomes seem plausible under continuous takeoff, which the consensus view in AI safety (as I understand it) sees as more likely than fast takeoff. I admit that there are strong reasons for thinking that the aggregate of a bunch of sufficiently smart things is agentic, but this isn't directly relevant for the concerns about humans wi...
4
The default outcome is an unaligned superintelligence singleton destroying the world and not caring about human concepts like property rights. Whereas an aligned superintelligence can create a far more utopian future than a human could come up with, and cares about capitalism and property rights only to the extent that that's what it was designed to care about.
So I indeed don't get your perspective. Why are humans still appearing as agents or decision-makers in your post-superintelligence scenario at all? If the superintelligence for some unlikely reason wants a human to stick around and to do something, then it doesn't need to pay them. And if a superintelligence wants a resource, it can just take it, no need to pay for anything.
6
@L Rudolf L can talk on his own, but for me, a crux probably is I don't expect either unaligned superintelligence singleton or a value aligned superintelligence creating utopia as the space of likely outcomes within the next few decades.
For the unaligned superintelligence point, my basic reasons is I now believe the alignment problem got significantly easier compared to 15 years ago, I've become more bullish on AI control working out since o3, and I've come to think instrumental convergence is probably correct for some AIs we build in practice, but that instrumental drives are more constrainable on the likely paths to AGI and ASI.
For the alignment point, a big reason for this is I now think a lot of what makes an AI aligned is primarily data, compared to inductive biases, and one of my biggest divergences with the LW community comes down to me thinking that inductive bias is way less necessary for alignment than people usually think, especially compared to 15 years ago.
For AI control, one update I've made for o3 is that I believe OpenAI managed to get the RL loop working in domains where outcomes are easily verifiable, but not in domains where verifying is hard, and programming/mathematics are such domains where verifying is easy, but the tie-in is that capabilities will be more spikey/narrow than you may think, and this matters since I believe narrow/tool AI has a relevant role to play in an intelligence explosion, so you can actually affect the outcome by building narrow capabilities AI for a few years, and the fact that AI capabilities are spikey in domains where we can easily verify outcomes is good for eliciting AI capabilities, which is a part of AI control.
For the singleton point, it's probably because I believe takeoff is both slow and somewhat distributed enough such that multiple superintelligent AIs can arise.
For the value-aligned superintelligence creating a utopia for everyone, my basic reason for why I don't really believe in this is because
6
And why must alignment be binary? (aligned, or misaligned, where misaligned necessarily means it destroys the world and does not care about property rights)
Why can you not have an a superintelligence that is only misaligned when it comes to issues of wealth distribution?
Relatedly, are we sure that CEV is computable?
3
I guess we could in theory fail and only achieve partial alignment, but that seems like a weird scenario to imagine. Like shooting for a 1 in big_number target (= an aligned mind design in the space of all potential mind designs) and then only grazing it. How would that happen in practice?
And what does it even mean for a superintelligence to be "only misaligned when it comes to issues of wealth distribution"? Can't you then just ask your pretty-much-perfectly-aligned entity to align itself on that remaining question?
3
Are you saying that the 1 aligned mind design in the space of all potential mind designs is an easier target than the subspace composed of mind designs that does not destroy the world? If so, why? is it a bigger target? is it more stable?
No, because the you who can ask (the persons in power) is themselves misaligned with the 1 alignment target that perfectly captures all our preferences.
1
I didn't mean that there's only one aligned mind design, merely that almost all (99.999999...%) conceivable mind designs are unaligned by default, so the only way to survive is if the first AGI is designed to be aligned, there's no hope that a random AGI just happens to be aligned. And since we're heading for the latter scenario, it would be very surprising to me if we managed to design a partially aligned AGI and lose that way.
I expect the people in power are worrying about this way more than they worry about the overwhelming difficulty of building an aligned AGI in the first place. (Case in point: the manufactured AI race with China.) As a result I expect they'll succeed at building a by-default-unaligned AGI and driving themselves and us to extinction. So I'm not worried about instead ending up in a dystopia ruled by some government or AI lab owner.
3
End points are easier to infer than trajectories, so sure, I think there's some reasonable guesses you can try to make about how the world might look after aligned superintelligence, should we get it somehow.
For example, I think it's a decent bet that basically all minds would exist solely as uploads almost all of the time, because living directly in physical reality is astronomically wasteful and incredibly inconvenient. Turning on a physical lamp every time you want things to be brighter means wiggling about vast numbers of particles and wasting an ungodly amount of negentropy just for the sake of the teeny tiny number of bits about these vast numbers of particles that actually make it to your eyeballs, and the even smaller number of bits that actually end up influencing your mind state and making any difference to your perception of the world. All of the particles[1] in the lamp in my bedroom, the air its light shines through, and the walls it bounces off, could be so much more useful arranged in an ordered dance of logic gates where every single movement and spin flip is actually doing something of value. If we're not being so incredibly wasteful about it, maybe we can run whole civilisations for aeons on the energy and negentropy that currently make up my bedroom. What we're doing right now is like building an abacus out of supercomputers. I can't imagine any mature civilisation would stick with this.
It's not that I refuse to speculate about how a world post aligned superintelligence might look. I just didn't think that your guess was very plausible. I don't think pre-existing property rights or state structures would matter very much in such a world, even if we don't get what is effectively a singleton, which I doubt. If a group of superintelligent AGIs is effectively much more powerful and productive than the entire pre-existing economy, your legal share of that pre-existing economy is not a very relevant factor in your ability to steer the future and g
End points are easier to infer than trajectories
Assuming that which end point you get to doesn't depend on the intermediate trajectories at least.
6
Something like a crux here is I believe the trajectories non-trivially matter for which end-points we get, and I don't think it's like entropy where we can easily determine the end-point without considering the intermediate trajectory, because I do genuinely think some path-dependentness is present in history, which is why even if I were way more charitable towards communism I don't think this was ever defensible:
Another issue is the Eternal September issue where LW membership has grown a ton due to the AI boom (see the LW site metrics in the recent fundraiser post), so as one might expect, most new users haven't read the old stuff on the site. There are various ways in which the LW team tries to encourage them to read those, but nevertheless.
The basic answer is the following:
- The incentive problem still remains, such that it's more effective to use the price system than to use a command economy to deal with incentive issues:
https://x.com/MatthewJBar/status/1871640396583030806
- Related to this, perhaps the outer loss of the markets isn't nearly as dispensable as a lot of people on LW believe, and contact with reality is a necessary part of all future AIs.
More here:
- A potentially large crux is I don't really think a utopia is possible, at least in the early years even by superintelligences, because I expect preferences in the new environment to grow unboundedly such that preferences are always dissatisfied, even charitably assuming a restriction on the utopia concept to be relative to someone else's values.
6[anonymous]
going by the linked tweet, does "incentive problem" mean "needing to incentivize individuals to share information about their preferences in some way, which is currently done through their economic behavior, in order for their preferences to be fulfilled"? and contrasted with a "command economy", where everything is planned out long in advance, and possibly on less information about the preferences of individual moral patients?
if so, those sound like abstractions which were relevant to the world so far, but can you not imagine any better way a superintelligence could elicit this information? it does not need to use prices or trade. some examples:
* it could have many copies of itself talk to them
* it could let beings enter whatever they want into a computer in real time, or really let beings convey their preferences in whatever medium they prefer, and fulfill them[1]
* it could mind-scan those who are okay with this.
(these are just examples selected for clarity; i personally would expect something more complex and less thing-oriented, around moral patients who are okay with/desire it, where superintelligence imbues itself as computation throughout the lowest level of physics upon which this is possible, and so it is as if physics itself is contextually aware and benevolent)
(i think these also sufficiently address your point 2, about SI needing 'contact with reality')
there is also a second (but non-cruxy) assumption here, that preference information would need to be dispersed across some production ecosystem, which would not be true given general-purpose superintelligent nanofactories. this though is not a crux as long as whatever is required for production can fit on, e.g., a planet (which the information derived in, e.g., one of those listed ways, can be communicated across at light-speed, as we partially do now).
i interpret this to mean "some entities' values will want to use as much matter as they can for things, so not all values can be unboundedl
4
The other issue is value conflicts, which I expect to be mostly irresolvable in a satisfying way by default due to moral subjectivism combined with me believing that lots of value conflicts today are mostly suppressed because people can't make their own nation-states, but with AI, they can, and superintelligence makes the problem worse.
That's why you can't have utopia for everyone.
1[anonymous]
i think this would not happen for the same fundamental reason that an aligned superintelligence can foresee whatever you can, and prevent / not cause them if it agrees they'd be worse than other possibilities. (more generally, "an aligned superintelligence would cause some bad-to-it thing" is contradictory, usually[1].)
(i wonder if you're using the term 'superintelligence' in a different way though, e.g. to mean "merely super-human"? to be clear i definitionally mean it in the sense of optimal)
(tangentially: the 'nations' framing confuses me)[2]
i think i wrote before that i agree (trivially) that not all possible values can be maximally satisfied; still, you can have the best possible world, which i think on this axis would look like "there being very many possible environments suited to different beings preferences (as long as those preferences are not to cause suffering to others)" instead of "beings with different preferences going to war with each other" (note there is no coordination problem which must be solved for that to happen. a benevolent superintelligence would itself not allow war (and on that, i'll also hedge that if there is some tragedy which would be worth the cost of war to stop, an aligned superintelligence would just stop it directly instead.))
1. ^
some exceptions like "it is aligned, but has the wrong decision theory, and gets acausally blackmailed"
2. ^
in the world of your premise (with people using superintelligence to then war over value differences), superintelligence, not nations, would be the most powerful thing (with which) to do conflict
2
I think the main point is that what's worse than other possibilities partially depends on your value system at the start, and there is no non-circular way of resolving deep enough values conflicts such that you can always prevent conflict, so with differing enough values, you can generate conflict on it's own.
(Note when I focus on superintelligence, I don't focus on the AI literally doing optimal actions, because that leads to likely being wrong about what AIs can actually do, which is actually important.)
On the nations point, my point here is that people will program their superintelligences with quite different values, and the superintelligences will disagree about what counts as optimal from their lights, and if the disagreements are severe enough (which I predict is plausible if AI development cannot be controlled at all), conflict can definitely happen between the superintelligences, even if humans no longer are the main players.
Also, it's worth it to read these posts and comments, because I perceive some mistakes that are common amongst rationalists:
https://www.lesswrong.com/posts/895Qmhyud2PjDhte6/responses-to-apparent-rationalist-confusions-about-game
https://www.lesswrong.com/posts/HFYivcm6WS4fuqtsc/dath-ilan-vs-sid-meier-s-alpha-centauri-pareto-improvements#jpCmhofRBXAW55jZv
I agree you can have a best possible world (though that gets very tricky in infinite realms due to utility theory breaking at that point), but my point here is that the best possible world is relative to a given value set, and also quite unconstrained, and your vision definitely requires other real-life value sets to lose out on a lot, here.
Are you assuming that superintelligences will have common enough values for some reason? To be clear, I think this can happen, assuming AI is controlled by a specific group that has enough of a monopoly on violence to prevent others from making their own AI, but I don't have nearly the confidence that you do that conflict is always
1[anonymous]
you didn't write "yes, i use 'superintelligent' to mean super-human", so i'll write as if you also mean optimal[1]. though i suspect we may have different ideas of where optimal is, which could become an unnoticed crux, so i'm noting it.
i am expecting the first superintelligent agent to capture the future, and for there to be no time for others to arise to compete with it.
in a hypothetical setup where multiple superintelligences are instantiated at close to the same time within a world, it's plausible to me that they would fight in some way, though also plausible that they'd find a way not to. as an easy reason they might fight: maybe one knows it will win (e.g., it has a slight head start and physics is such that that is pivotal).
in my model of reality: it takes ~2/15ths of a second for light to travel the length of the earth's circumference. maybe there are other bottlenecks that would push the time required for an agentic superintelligence to take over the earth to minutes-to-hours. as long as the first superintelligent (world-valuing-)agent is created at least <that time period's duration> before the next one would have been created, it will prevent that next one's creation. i assign very low likelyhood to multiple superintelligences being independently created within the same hour.
this seems like a crux, and i don't yet know why you expect otherwise, failing meaning something else by superintelligence.
actually, i can see room for disagreement about whether 'slow, gradual buildup of spiky capabilities profiles' would change this. i don't think it would because ... if i try to put it into words, we are in an unstable equilibrium, which will at some point be disrupted, and there are not 'new equilibriums, just with less balance' for the world to fall on. however, gradual takeoff plus a strong defensive advantage inherent in physics could lead to it, for intuitive reasons[2]. in terms of current tech like nukes there's an offensive advantage, but we don't
2
I think I understand your position better, and a crux for real-world decision making is that in practice, I don't really think this assumption is correct by default, especially if there's a transition period.
1[anonymous]
i do not understand your position from this, so you're welcome to write more. also, i'm not sure if i added the paragraph about slow takeoff before or after you loaded the comment.
an easy way to convey your position to me might be to describe a practical rollout of the future where all the things in it seem individually plausible to you.
2
One example of such a future is a case where in 2028, OpenAI managed to scale up enough to make an AI that while not as good as a human worker in general (at least without heavy inference costs), it is good enough to act as a notable accelerant to AI research, such that by 2030-2031, AI research has been more or less automated away by Open AI, with competitors having such systems by 2031-2032, meaning AI progress becomes notably faster such that by 2033, we are on the brink of AI that can do a lot of job work, but the best models at this point are instead reinvested in AI R&D such that by 2035, superhuman AI is broadly achieved, and this is when the economy starts getting seriously disrupted.
The key features here in this future is that intent alignment works well enough that AI generally takes instructions from specific humans, and it's easy for others to get their own superintelligences with different values, such that conflict doesn't go away.
1[anonymous]
oh, well to clarify then, i was trying to say that i didn't mean 'superhuman' at all, i directly meant optimal. i don't believe that superhuman = optimal, and when reading this story one of the first things that stood out was that the 2035 point is still before the first long-term-decisive entity.
2
Edited my comment.
1[anonymous]
but it still says "it's easy for others to get their own superintelligences with different values", with 'superintelligence' referring to the 'superhuman' AI of 2035?
my response is the same, the story ends before what i meant by superintelligence has occurred.
(it's okay if this discussion was secretly a definition difference till now!)
2
Yeah, the crux is I don't think the story ends before superintelligence, for a combination of reasons
1[anonymous]
what i meant by "the story ends before what i meant by superintelligence has occurred" is that the written one ends there in 2035, but at that point there's still time to effect what the first long-term-decisive thing will be.
1[anonymous]
still confused about this btw. in my second reply to you i wrote:
and you did not say you were, but it looks like you are here?
2
I was assuming very strongly superhumanly intelligent AI, but yeah no promises of optimality were made here.
That said, I suspect a crux is that optimality ends up with multipolarity, assuming a one world government hasn't happened by then, because I think the offense-defense balance moderately favors defense even at optimality, assuming optimal defense and offense.
1[anonymous]
oh okay, i'll have to reinterpret then. edit: i just tried, but i still don't get it; if it's "very strongly superhuman", why is it merely "when the economy starts getting seriously disrupted"? (<- this feels like it's back at where this thread started)
why?
2
I should probably edit that at some point, but I'm on my phone, so I'll do it tomorrow.
A big reason for this is logistics, as how you are getting to the fight can actually hamper you a lot, and this especially bites hard on offense, because it's easier to get supplies to your area than it is to get supplies to an offensive unit.
This especially matters if physical goods need to be transported from one place to another place.
1[anonymous]
ah. for 'at optimality' which you wrote, i don't imagine it to take place on that high of a macroscopic level (the one on which 'supplies' could be transported), i think the limit is more things that look to us like the category of 'angling rays of light just right to cause distant matter to interact in such away as to create an atomic explosion, or some even more destructive reaction we don't yet know about, or to suddenly carve out a copy of itself there to start doing things locally', and also i'm not imagining the competitors being 'solid' macroscopic entities anymore, but rather being patterns imbued (and dispersed) in a relatively 'lower' level of physics (which also do not need 'supplies'). (edit: maybe this picture is wrong, at optimality you can maybe absorb the energy of such explosions / not be damaged by them, if you're not a macroscopic thing. which does actually defeat the main way macroscopic physics has an offense advantage?)
(i'm just exploring what it would be like to be clear, i don't think such conflicts will happen because i still expect just one optimal-level-agent to come from earth)
2
I am willing to concede that here, the assumption of non-optimal agents were more necessary than I thought for my argument, and I think you are right on the necessity of the assumption in order to guarantee anything like a normal future (though it still might be multipolar), so I changed a comment.
My new point is that I don't think optimal agents will exist when we lose all control, but yes I didn't realize an assumption was more load-bearing than I thought.
1[anonymous]
(btw I also realized I didn't strictly mean 'optimal' by 'superintelligent', but at least close enough to it / 'strongly superhuman enough' for us to not be able to tell the difference. I originally used the 'optimal' wording trying to find some other definition apart from 'super-human')
it is also plausible to me that life-caring beings first lose control to much narrower programs[1] or moderately superhuman unaligned agents totally outcompeting them economically (if it turns out that making better agents is hard enough that they can't just directly do that instead), or something.
also, a 'multipolar AI-driven but still normal-ish' scenario seems to continue at most until a strong enough agent is created. (e.g. that could be what a race is towards).
(maybe after 'loss of control to weaker AI' scenarios, those weaker AIs also keep making better agents afterwards, but i'm not sure about that, because they could be myopic and in some stable pattern/equilibrium)
1. ^
(e.g. the 'going out with a whimper' part of this post)
1[anonymous]
i missed this part:
i'm not sure what this means. my values basically refer to other beings having not-tormentful (and next in order of priority, happy/good) existences. (tried to formalize this more but it's hard)
in particular, i'm not sure if you're saying something which would seem trivially true to me or not. (example trivially true thing: someone who wants to tile literally the entire lightcone with happy humans not being able to do that is losing out under 'cosmopolitan' values relative to if their values controlled the entire lightcone. example trivially true thing 2: "the best possible world is relative to a given value set")
2
That would immediately exclude quite a bit of people, from both the far left and far right, because I predict a lot of people definitely want at least some people to have tormentful lives.
I was trying to say something trivially true in your ontology, but far too many people tend to deny that you do in fact have to make other values lose out, and people usually think the best possible world is absolute, not relative, and in particular I think a lot of people use the idea of value-aligned superintelligence as though it was a magic wand that could solve all conflict.
1[anonymous]
i don't know where that might be true, but at least on lesswrong i imagine it's an uncommon belief. a core premise of alignment being important is value orthogonality implying that an unaligned agent with max-level-intelligence would compete for the same resources whose configurations it values (the universe). most of the reason for collaborating on alignment despite orthogonality is that our values tend to overlap to a large degree, e.g. most people (and maybe especially most alignment researchers?) think hells are bad.
also on the "lose out" phrasing: even if someone "wants at least some people to have tormentful lives", they don't "lose out" overall if they also positively value other things / still negatively value any of the vast majority of beings having tormentful lives.
4
I think a crux I have with the entire alignment community may ultimately come down to me not believing that human values overlap strongly enough to make alignment the most positive thing, compared to other AI safety things.
In particular, I'd expect a surprising amount of disagreement on whether making a hell is good, if you managed to sell it as eternally punishing a favored enemy.
I agree LWers tend to at least admit that severe enough value conflicts can exist, though I think that people like Eliezer don't realize that human values conflicts sort of break collective CEV type solutions, and a lot of collective alignment solutions tend to assume that either someone puts their thumb on the scale and exclude certain values, or assume that human values are so similar and their idealizations are so similar that no conflicts are expected, which I personally don't think is true.
Agree with this, which handles some cases, but my worry is that there are still likely to be big values conflicts where one value set must ultimately win out over another.
My guess is that it's just an effect of field growth. A lot of people coming in now weren't around when the consensus formed and don't agree with it or don't even know much about it.
Also, the consensus wasn't exactly uncontroversial on LW even way back in the day. Hanson's Ems inhabit a somewhat more recognisable world and economy that doesn't have superintelligence in it, and lots of skeptics used to be skeptical in the sense of thinking all of this AI stuff was way too speculative and wouldn't happen for hundreds of years if ever, so they made critiques of that form or just didn't engage in AI discussions at all. LW wasn't anywhere near this AI-centric when I started reading it around 2010.
9
1. My question specifically asks about the transition to ASI, which, while I think it's really hard to predict, seems likely to take years, during which time we have intelligences just a bit above human level, before they're truly world-changingly superintelligent. I understand this isn't everyone's model, and it's not necessarily mine, but I think it is plausible.
2. Asking "how could someone ask such a dumb question?" is a great way to ensure they leave the community. (Maybe you think that's a good thing?)
5[anonymous]
I don't, sorry. (I'd encourage you not to leave just because of this, if it was just this. maybe LW mods can reactivate your account? @Habryka)
Yeah looks like I misinterpreted it. I agree that time period will be important.
I'll try to be more careful.
Fwiw, I wasn't expecting this shortform to get much engagement, but given it did it probably feels like public shaming, if I imagine what it's like.
2
(Happy to reactivate your account, though I think you can also do it yourself)
1[anonymous]
I hope you're okay btw
3
I'm fine. Don't worry to much about this. It just made me think, what am I doing here? For someone to single out my question and say "it's dumb to even ask such a thing" (and the community apparently agrees)... I just think I'll be better off not spending time here.
3[anonymous]
I'd guess that most just skimmed what was visible from the hoverover, while under the impression it was what my text said. The engagement on your post itself is probably more representative.
Did not mean to do that.
5
I guess part of the issue is that in any discussion, people don't use the same terms in the same way. Some people call present-day AI capabilities by terms like "superintelligent" in a specific domain. Which is not how I understand the term, but I understand where the idea to call it that comes from. But of course such mismatched definitions make discussions really hard. Seeing stuff like that makes it very understandable why Yudkowsky wrote the LW Sequences...
Anyway, here is an example of a recent shortform post which grapples with the same issue that vague terms are confusing.
4
I feel like this is a bit incorrect. There are imaginable things that are smarter than humans at some tasks, smart as average humans at others, thus overall superhuman, yet controllable and therefore possible to integrate in an economy without immediately exploding into an utopian (or dystopian) singularity. The question is whether we are liable to build such things before we build the exploding singularity kind, or if the latter is in some sense easier to build and thus stumble upon first. Most AI optimists think these limited and controllable intelligences are the default natural outcome of our current trajectory and thus expect mere boosts in productivity.
3[anonymous]
sure, e.g. i think (<- i may be wrong about what the average human can do) that GPT-4 meets this definition (far superhuman at predicting author characteristics, above-average-human at most other abstract things). that's a totally different meaning.
do you mean they believe superintelligence (the singularity-creating kind) is impossible, and so don't also expect it to come after? it's not sufficient for less capable AIs to defaultly come before superintelligence.
4
I think some believe it's downright impossible and others that we'll just never create it because we have no use for something so smart it overrides our orders and wishes. That at most we'll make a sort of magical genie still bound by us expressing our wishes.
nothing short of death can stop me from trying to do good.
the world could destroy or corrupt EA, but i'd remain an altruist.
it could imprison me, but i'd stay focused on alignment, as long as i could communicate to at least one on the outside.
even if it tried to kill me, i'd continue in the paths through time where i survived.
Never say 'nothing' :-)
- the world might be in such state that attempts to do good bring it into some failure instead, and doing the opposite is prevented by society
(AI rise and blame-credit which rationality movement takes for it, perhaps?) - what if, for some numerical scale, the world would give you option "with 50%, double goodness score; otherwise, lose almost everything"? Maximizing EV on this is very dangerous...
9
I upvoted because I imagine more people reading this would slightly nudge group norms in a direction that is positive.
But being cynical:
* I'm sure you believe that this is true, but I doubt that it is literally true.
* Signalling this position is very low risk when the community is already on board.
* Trying to do good may be insufficient if your work on alignment ends up being dual use.
3[anonymous]
"No! Try not! Do, or do not. There is no try."
—Yoda
Trying to try
3[anonymous]
if i left out the word 'trying' to (not) use it in that way instead, nothing about me would change, but there would be more comments saying that success is not certain.
i also disagree with the linked post[1], which says that 'i will do x' means one will set up a plan to achieve the highest probability of x they can manage. i think it instead usually means one believes they will do x with sufficiently high probability to not mention the chance of failure.[2] the post acknowledges the first half of this -- «Well, colloquially, "I'm going to flip the switch" and "I'm going to try to flip the switch" mean more or less the same thing, except that the latter expresses the possibility of failure.» -- but fails to integrate that something being said implies belief in its relevance/importance, and so concludes that using the word 'try' (or, by extrapolation, expressing the possibility of failure in general) is unnecessary in general.
1. ^
though its psychological point seems true:
2. ^
this is why this wording is not used when the probability of success is sufficiently far (in percentage points, not logits) from guaranteed.
3[anonymous]
I think the post was a deliberate attempt to overcome that psychology, the issue is you can get stuck in these loops of "trying to try" and convincing yourself that you did enough, this is tricky because it's very easy to rationalise this part for feeling comfort.
When you set up for winning v/s try to set up for winning.
The latter is much easier to do than the former, and former still implies chance of failure but you actually try to do your best rather than, try to try to do your best.
I think this sounds convoluted, maybe there is a much easier cognitive algorithm to overcome this tendency.
i might try sleeping for a long time (16-24 hours?) by taking sublingual[1] melatonin right when i start to be awake, and falling asleep soon after. my guess: it might increase my cognitive quality on the next wake up, like this:
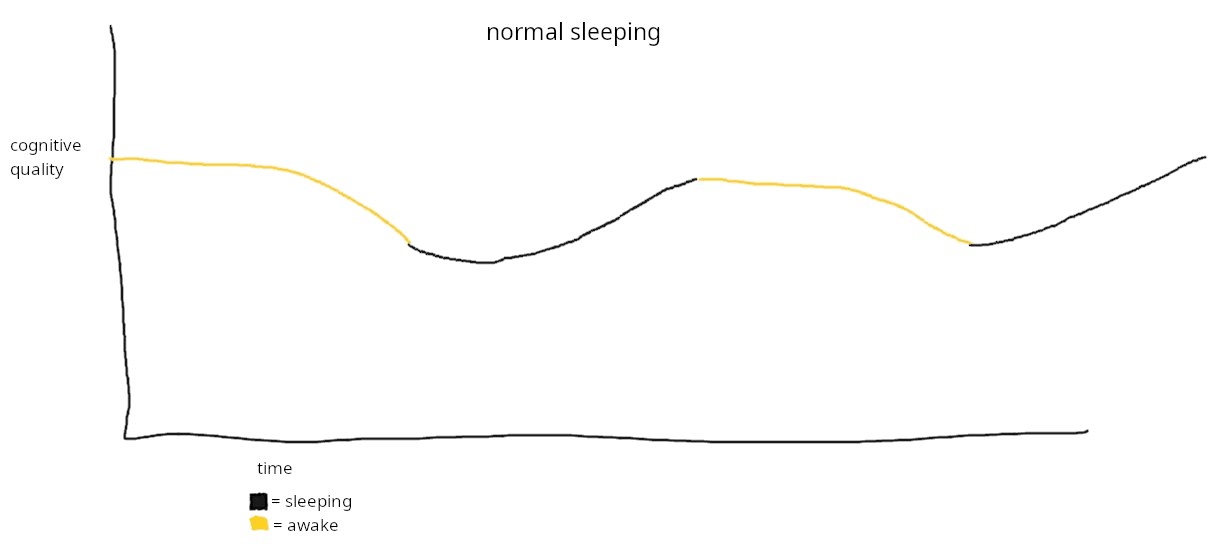
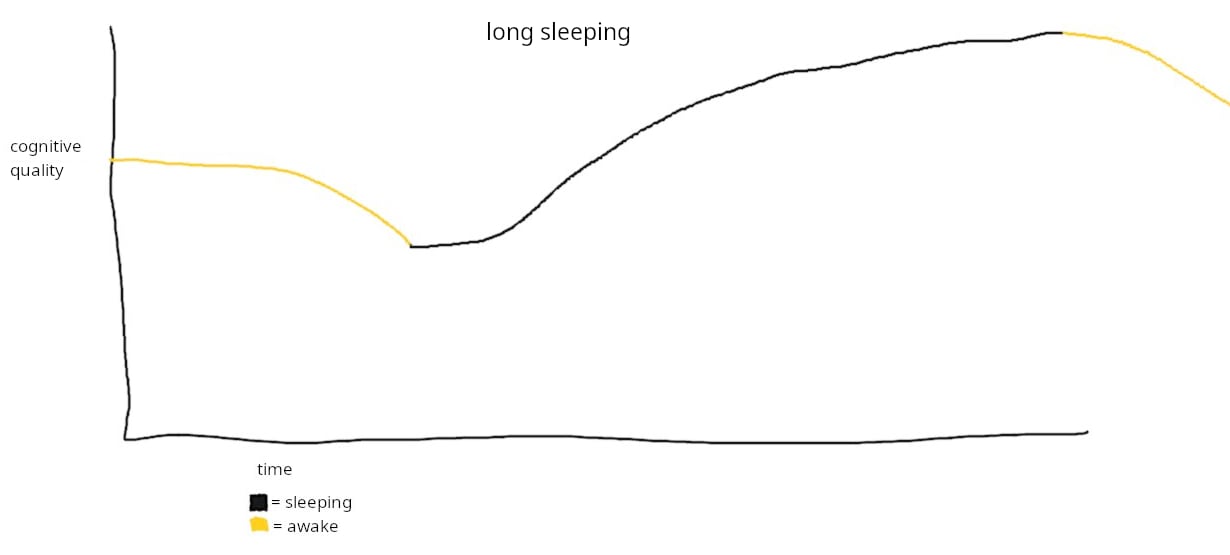
(or do useful computation during sleep, leading to apparently having insights on the next wakeup? long elaboration below)
i wonder if it's even possible, or if i'd have trouble falling asleep again despite the melatonin.
i don't see much risk to it, since my day/night cycle is already uncalibrated[2], and melatonin is naturally used for this narrow purpose in the body.
'cognitive quality' is really vague. here's what i'm really imagining
my unscientific impression of sleep, from subjective experience (though i only experience the result) and speculation i've read, is that it does these things:
- integrates into memory what happened in the previous wake period, and maybe to a lesser extent further previous ones
- more separate to the previous wake period, acts on my intuitions or beliefs about things to 'reconcile' or 'compute implicated intuitions'. for example if i was trying to reconcile two ideas, or solve some confusing logical problem, maybe the
I predict this won't work as well as you hope because you'll be fighting the circadian effect that partially influences your cognitive performance.
Also, some ways to maximize your sleep quality are too exercise very intensely and/or to sauna, the day before.
8
Heh, I've gone the opposite way and now do 3h sleep per 12h-days. The aim is to wake up during REM/light-sleep at the end of the 2nd sleep cycle, but I don't have a clever way of measuring this[1] except regular sleep-&-wake-times within the range of what the brain can naturally adapt its cycles to.
I think the objective should be to maximize the integral of cognitive readiness over time,[2] so here are some considerations (sorry for lack of sources; feel free to google/gpt; also also sorry for sorta redundant here, but I didn't wish to spend time paring it down):
* Restorative effects of sleep have diminishing marginal returns
* I think a large reason we sleep is that metabolic waste-clearance is more efficiently batch-processed, because optimal conditions for waste-clearance are way different from optimal conditions for cognition (and substantial switching-costs between, as indicated by how difficult it can be to actually start sleeping). And this differentially takes place during deep sleep.
* Eg interstitial space expands by ~<60% and the brain is flooded to flush out metabolic waste/debris via the glymphatic system.
* Proportion of REM-sleep in a cycle increases per cycle, with a commensurate decrease in deep sleep (SWS).
* Two unsourced illustrations I found in my notes:
* Note how N3 (deep sleep) drops off fairly drastically after 3 hours (~2 full sleep cycles).
* REM & SWS do different things, and I like the things SWS do more
* Eg acetylcholine levels (ACh) are high during REM & awake, and low during SWS. ACh functions as a switch between consolidation & encoding of new memories.[3] Ergo REM is for exploring/generalizing novel patterns, and SWS is for consolidating/filtering them.
* See also acetylcholine = learning-rate.
* REM seems to differentially improve procedural memories, whereas SWS more for declarative memories.
* (And who cares about procedural memories anyway. :p)
* (My most-recent-pet-
1
A lot of people e.g. Andrew Huberman (who recommends many supplements for cognitive enhancement and other ends) recommend against supplementing melatonin except to treat insomnia that has failed to respond to many other interventions.
1[anonymous]
why?
i searched Andrew Huberman melatonin and found this, though it looks like it may be an AI generated summary.
8
The CNS contains dozens of "feedback loops". Any intervention that drastically alters the equilibrium point of several of those loops is generally a bad idea unless you are doing it to get out of some dire situation, e.g., seizures. That's my recollection of Huberman's main objection put into my words (because I dont recall his words).
Supplementing melatonin is fairly unlikely to have (much of) a permanent effect on the CNS, but you can waste a lot of time by temporarily messing up CNS function for the duration of the melatonin supplementation (because a person cannot make much progress in life with even a minor amount of messed-up CNS function).
A secondary consideration is that melatonin is expensive to measure quantitatively, so the amount tends to vary a lot from what is on the label. In particular, there are reputational consequences and possible legal consequences to a brand's having been found to have less than the label says, so brands tend to err on the side of putting too much melatonin in per pill, which ends up often being manyfold more than the label says.
There are many better ways to regularize the sleep rhythm. My favorite is ensuring I get almost no light at night (e.g., having foil on the windows of the room I sleep in) but then get the right kind of light in the morning, which entails understanding how light affects the intrinsically photosensitive retinal ganglion cells and how those cells influence the circadian rhythm. In fact, I'm running my screens (computer screen and iPad screen) in grayscale all day long to prevent yellow-blue contrasts on the screen from possibly affecting my circadian rhythm. I also use magnesium and theanine according to a complex protocol of my own devising.
i don't think having (even exceptionally) high baseline intelligence and then studying bias avoidance techniques is enough for one to be able to derive an alignment solution. i have not seen in any rationalist i'm aware of what feels like enough for that, though their efforts are virtuous of course. it's just that the standard set by the universe seems higher.
i think this is a sort of background belief for me. not failing at thinking is the baseline; other needed computations are harder. they are not satisfied by avoiding failure conditions, but require the satisfaction of some specific, hard-to-find success condition. learning about human biases will not train one to cognitively seek answers of this kind, only to avoid premature failure.
this is basically a distinction between rationality and creativity. rationality[1] is about avoiding premature failure, creativity is about somehow generating new ideas.
but there is not actually something which will 'guide us through' creativity, like hpmor/the sequences do for rationality. there are various scattered posts about it[2].
i also do not have a guide to creativity to share with you. i'm only pointing at it as an equally if not more...
8
I do. Edward de Bono’s oeuvre is all about this, beginning with the work that brought him to public notice and coined an expression that I think most people do not know the origin of these days, “Lateral Thinking”. He and lateral thinking were famous back in the day, but have faded from public attention since. He has been mentioned before on LessWrong, but only a handful of times.
There are also a few individual works, such as “Oblique Strategies” and TRIZ.
The “Draftsmen” podcast by two artists/art instructors contains several episodes on the subject. These are specific to the topic of making art, which was my interest in watching the series, but the ideas may generalise.
One can uncreatively google “how to be creative” and get a ton of hits, although from eyeballing them I expect most to be fairly trite.
1[anonymous]
i am an artist as well :). i actually doubt for most artists that they could give much insight here; i think that usually artist creativity, and also mathematician creativity etc, human creativity, is of the default, mysterious kind, that we don't know where it comes from / it 'just happens', like intuitions, thoughts, realizations do - it's not actually fundamentally different from those even, just called 'creativity' more often in certain domains like art.
4
The sources I listed are all trying to demystify it, Edward de Bono explicitly so. They are saying, there are techniques, methods, and tools for coming up with new ideas, just as the Sequences are saying, there are techniques, methods, and tools for judging ideas so as to approach the truth of things.
In creativity, there is no recipe with which you can just crank the handle and it will spit out the right idea, but neither is there in rationality a recipe with which you can just crank the handle and come up with a proof of a conjecture.
3[anonymous]
yep not contesting any of that
to be clear, coming up with proofs is a central example of what i meant by creativity. ("they are not satisfied by avoiding failure conditions, but require the satisfaction of some specific, hard-to-find success condition")
i currently believe that working on superintelligence-alignment is likely the correct choice from a fully-negative-utilitarian perspective.[1]
for others, this may be an intuitive statement or unquestioned premise. for me it is not, and i'd like to state my reasons for believing it, partially as a response to this post concerned about negative utilitarians trying to accelerate progress towards an unaligned-ai-takeover.
there was a period during which i was more uncertain about this question, and avoided openly sharing minimally-dual-use alignment research (but did not try to accelerate progress towards a nonaligned-takeover) while resolving that uncertainty.
a few relevant updates since then:
- decrease on the probability that the values an aligned AI would have would endorse human-caused moral catastrophes such as human-caused animal suffering.
i did not automatically believe humans to be good-by-default, and wanted to take time to seriously consider what i think should be a default hypothesis-for-consideration upon existing in a society that generally accepts an ongoing mass torture event. - awareness of vastly worse possible s-risks.
factory farming is a form of physical torture, by w
4
Considering how loog it took me to get that by this you mean "not dual-use", I expect some others just won't get it.
3
You may find Superintelligence as a Cause or Cure for Risks of Astronomical Suffering of interest; among other things, it discusses s-risks that might come about from having unaligned AGI.
3[anonymous]
thanks for sharing. here's my thoughts on the possibilities in the quote.
Suffering subroutines - maybe 10-20% likely. i don't think suffering reduces to "pre-determined response patterns for undesirable situations," because i can think of simple algorithmic examples of that which don't seem like suffering.
suffering feels like it's about the sense of aversion/badness (often in response a situation), and not about the policy "in <situation>, steer towards <new situation>". (maybe humans were instilled with a policy of steering away from 'suffering' states generally, and that's why evolution made us enter those states in some types of situation?). (though i'm confused about what suffering really is)
i would also give the example of positive-feeling emotions sometimes being narrowly directed. for example, someone can feel 'excitement/joy' about a gift or event and want to <go to/participate in> it. sexual and romantic subroutines can also be both narrowly-directed and positive-feeling. though these examples lack the element of a situation being steered away from, vs steering (from e.g any neutral situation) towards other ones.
Suffering simulations - seems likely (75%?) for the estimation of universal attributes, such as the distribution of values. my main uncertainty is about whether there's some other way for the ASIs to compute that information which is simple enough to be suffering free. this also seems lower magnitude than other classes, because (unless it's being calculated indefinetely for ever-greater precision) this computation terminates at some point, rather than lasting until heat death (or forever if it turns out that's avoidable).
Blackmail - i don't feel knowledgeable enough about decision theory to put a probability on this one, but in the case where it works (or is precommitted to under uncertainty in hopes that it works), it's unfortunately a case where building aligned ASI would incentive unaligned entities to do it.
Flawed realization - again
3
Yeah, I agree with this to be clear. Our intended claim wasn't that just "pre-determined response patterns for undesirable situations" would be enough for suffering. Actually, there were meant to be two separate claims, which I guess we should have distinguished more clearly:
1) If evolution stumbled on pain and suffering, those might be relatively easy and natural ways to get a mind to do something. So an AGI that built other AGIs might also build them to experience pain and suffering (that it was entirely indifferent to), if that happened to be an effective motivational system.
2) If this did happen, then there's also some speculation suggesting that an AI that wanted to stay in charge might not want to give its worker AGIs things much in the way of things that looked like positive emotions, but did have a reason to give them things that looked like negative emotions. Which would then tilt the balance of pleasure vs. pain in the post-AGI world much more heavily in favor of (emotional) pain.
Now the second claim is much more speculative and I don't even know if I'd consider it a particularly likely scenario (probably not); we just put it in since much of the paper was just generally listing various possibilities of what might happen. But the first claim - that since all the biological minds we know of seem to run on something like pain and pleasure, we should put a substantial probability on AGI architectures also ending up with something like that - seems much stronger to me.
On Pivotal Acts
(edit: status: not a crux, instead downstream of different beliefs about what the first safe ASI will look like in predicted futures where it exists. If I instead believed 'task-aligned superintelligent agents' were the most feasible form of pivotally useful AI, I would then support their use for pivotal acts.)
I was rereading some of the old literature on alignment research sharing policies after Tamsin Leake's recent post and came across some discussion of pivotal acts as well.
Hiring people for your pivotal act project is going to be tricky. [...] People on your team will have a low trust and/or adversarial stance towards neighboring institutions and collaborators, and will have a hard time forming good-faith collaboration. This will alienate other institutions and make them not want to work with you or be supportive of you.
This is in a context where the 'pivotal act' example is using a safe ASI to shut down all AI labs.[1]
My thought is that I don't see why a pivotal act needs to be that. I don't see why shutting down AI labs or using nanotech to disassemble GPUs on Earth would be necessary. These may be among the 'most direct' or 'simplest to imagine' possible...
8
I think it is considered a constraint by some because they think that it would be easier/safer to use a superintelligent AI to do simpler actions, while alignment is not yet fully solved. In other words, if alignment was fully solved, then you could use it to do complicated things like what you suggest, but there could be an intermediate stage of alignment progress where you could safely use SI to do something simple like "melt GPUs" but not to achieve more complex goals.
5[anonymous]
Agreed that some think this, and agreed that formally specifying a simple action policy is easier than a more complex one.[1]
I have a different model of what the earliest safe ASI will look like, in most futures where one exists. Rather than a 'task-aligned' agent, I expect it to be a non-agentic system which can be used to e.g come up with pivotal actions for the human group to take / information to act on.[2]
1. ^
although formal 'task-aligned agency' seems potentially more complex than the attempt at a 'full' outer alignment solution that I'm aware of (QACI), as in specifying what a {GPU, AI lab, shutdown of an AI lab} is seems more complex than it.
2. ^
I think these systems are more attainable, see this post to possibly infer more info (it's proven very difficult for me to write in a way that I expect will be moving to people who have a model focused on 'formal inner + formal outer alignment', but I think evhub has done so well).
3[anonymous]
Reflecting on this more, I wrote in a discord server (then edited to post here):
I wasn't aware the concept of pivotal acts was entangled with the frame of formal inner+outer alignment as the only (or only feasible?) way to cause safe ASI.
I suspect that by default, I and someone operating in that frame might mutually believe each others agendas to be probably-doomed. This could make discussion more valuable (as in that case, at least one of us should make a large update).
For anyone interested in trying that discussion, I'd be curious what you think of the post linked above. As a comment on it says:
In my view, solving formal inner alignment, i.e. devising a general method to create ASI with any specified output-selection policy, is hard enough that I don't expect it to be done.[1] This is why I've been focusing on other approaches which I believe are more likely to succeed.
1. ^
Though I encourage anyone who understands the problem and thinks they can solve it to try to prove me wrong! I can sure see some directions and I think a very creative human could solve it in principle. But I also think a very creative human might find a different class of solution that can be achieved sooner. (Like I've been trying to do :)
5
Imagining a pivotal act of generating very convincing arguments for like voting and parliamentary systems that would turn government into 1) an working democracy 2) that's capable of solving the problem. Citizens and congress read arguments, get fired up, problem is solved through proper channels.
4
See minimality principle:
2
Okay. Why do you think Eliezer proposed that, then?
1[anonymous]
(see reply to Wei Dai)
edit: i think i've received enough expressions of interest (more would have diminishing value but you're still welcome to), thanks everyone!
i recall reading in one of the MIRI posts that Eliezer believed a 'world model violation' would be needed for success to be likely.
i believe i may be in possession of such a model violation and am working to formalize it, where by formalize i mean write in a way that is not 'hard-to-understand intuitions' but 'very clear text that leaves little possibility for disagreement once understood'. it wouldn't solve the problem, but i think it would make it simpler so that maybe the community could solve it.
if you'd be interested in providing feedback on such a 'clearly written version', please let me know as a comment or message.[1] (you're not committing to anything by doing so, rather just saying "im a kind of person who would be interested in this if your claim is true"). to me, the ideal feedback is from someone who can look at the idea under 'hard' assumptions (of the type MIRI has) about the difficulty of pointing an ASI, and see if the idea seems promising (or 'like a relevant model violation') from that perspective.
- ^
i don't have many cont
[This comment is no longer endorsed by its author]
7
I'm game! We should be looking for new ideas, so I'm happy to look at yours and provide feedback.
5
Consider me in
5
Historically I’ve been able to understand others’ vague ideas & use them in ways they endorse. I can’t promise I’ll read what you send me, but I am interested.
2
Maybe you can say a bit about what background someone should have to be able to evaluate your idea.
A quote from an old Nate Soares post that I really liked:
...It is there, while staring the dark world in the face, that I find a deep well of intrinsic drive. It is there that my resolve and determination come to me, rather than me having to go hunting for them.
I find it amusing that "we need lies because we can't bear the truth" is such a common refrain, given how much of my drive stems from my response to attempting to bear the truth.
I find that it's common for people to tell themselves that they need the lies in order to bear reality. In fact, I bet that many of you can think of one thing off the top of your heads that you're intentionally tolerifying, because the truth is too scary to even consider. (I've seen at least a dozen failed relationships dragged out for months and months due to this effect.)
I say, if you want the intrinsic drive, drop the illusion. Refuse to tolerify. Face the facts that you feared you would not be able to handle. You are likely correct that they will be hard to bear, and you are likely correct that attempting to bear them will change you. But that change doesn't need to break you. It can also make you stronger, and fuel your resolve.
So see the dark worl
(Personal) On writing and (not) speaking
I often struggle to find words and sentences that match what I intend to communicate.
Here are some problems this can cause:
- Wordings that are odd or unintuitive to the reader, but that are at least literally correct.[1]
- Not being able express what I mean, and having to choose between not writing it, or risking miscommunication by trying anyways. I tend to choose the former unless I'm writing to a close friend. Unfortunately this means I am unable to express some key insights to a general audience.
- Writing taking lots of time: I usually have to iterate many times on words/sentences until I find one which my mind parses as referring to what I intend. In the slowest cases, I might finalize only 2-10 words per minute. Even after iterating, my words are still sometimes interpreted in ways I failed to foresee.
These apply to speaking, too. If I speak what would be the 'first iteration' of a sentence, there's a good chance it won't create an interpretation matching what I intend to communicate. In spoken language I have no chance to constantly 'rewrite' my output before sending it. This is one reason, but not the only reason, that I've had a policy of t...
5
Aaron Bergman has a vid of himself typing new sentences in real-time, which I found really helpfwl.[1] I wish I could watch lots of people record themselves typing, so I could compare what I do.
Being slow at writing can be sign of failure or winning, depending on the exact reasons why you're slow. I'd worry about being "too good" at writing, since that'd be evidence that your brain is conforming your thoughts to the language, instead of conforming your language to your thoughts. English is just a really poor medium for thought (at least compared to e.g. visuals and pre-word intuitive representations), so it's potentially dangerous to care overmuch about it.
1. ^
Btw, Aaron is another person-recommendation. He's awesome. Has really strong self-insight, goodness-of-heart, creativity. (Twitter profile, blog+podcast, EAF, links.) I haven't personally learned a whole bunch from him yet,[2] but I expect if he continues being what he is, he'll produce lots of cool stuff which I'll learn from later.
2. ^
Edit: I now recall that I've learned from him: screwworms (important), and the ubiquity of left-handed chirality in nature (mildly important). He also caused me to look into two-envelopes paradox, which was usefwl for me.
Although I later learned about screwworms from Kevin Esvelt at 80kh podcast, so I would've learned it anyway. And I also later learned about left-handed chirality from Steve Mould on YT, but I may not have reflected on it as much.
1
Thank you, that is all very kind! ☺️☺️☺️
I hope so haha
1[anonymous]
Record yourself typing?
2
EDIT: I uploaded a better example here (18m18s):
Old example still here (7m25s).
2
Ah, most relevant: Paul Graham has a recording-of-sorts of himself writing a blog post "Startups in 13 sentences".
1[anonymous]
I think I've become better at writing clearly, relative to before. Part of it is just practice. A lesson that also feels relevant:
Write very precisely, meaning there is no non-trivial space of possible interpretations that you don't intend. Unless you do this, people may not respond to what you really mean, even if you consider it obvious.
1[anonymous]
Maybe someone has advice for finalizing-writing faster (not at the expense of clarity)? I think I can usually end up with something that's clear, at least if it's just a basic point that's compatible with the reader's ontology, but it still takes a long time.
1
It's also partially the problem with the recipient of communicated message. Sometimes you both have very different background assumptions/intuitive understandings. Sometimes it's just skill issue and the person you are talking to is bad at parsing and all the work of keeping the discussion on the important things / away from trivial undesirable sidelines is left to you.
Certainly it's useful to know how to pick your battles and see if this discussion/dialogue is worth what you're getting out of it at all.
i observe that processes seem to have a tendency towards what i'll call "surreal equilibria". [status: trying to put words to a latent concept. may not be legible, feel free to skip. partly 'writing as if i know the reader will understand' so i can write about this at all. maybe it will interest some.]
progressively smaller-scale examples:
- it's probably easiest to imagine this with AI neural nets, procedurally following some adapted policy even as the context changes from the one they grew in. if these systems have an influential, hard to dismantle role, the
7
The most likely/frequent outcome of "trying to build something that will last" is failure. You tried to build an AI, but it doesn't work. You tried to convince people that trade is better than violence, they cooked you for dinner. You tried to found a community, no one was interested. A group of friends couldn't decide when and where to meet.
But if you succeed to... create a pattern that keeps going on... then the thing you describe is the second most likely outcome. It turns out that your initial creation had parts that were easier or harder to replicate, and the easier ones keep going and growing, and the harder ones gradually disappear. The fluffy animal died, but its skeleton keeps walking.
It's like casting an animation spell on a thing, and finding out that the spell only affects certain parts of the thing, if any.
4
I would distinguish two variants of this. There's just plain inertia, like if you have a big pile of legacy code that accumulated from a lot of work, then it takes a commensurate amount of work to change it. And then there's security, like a society needs rules to maintain itself against hostile forces. The former is sort of accidentally surreal, whereas the latter is somewhat intentionally so, in that a tendency to re-adapt would be a vulnerability.
Here's a tampermonkey script that hides the agreement score on LessWrong. I wasn't enjoying this feature because I don't want my perception to be influenced by that; I want to judge purely based on ideas, and on my own.
Here's what it looks like:

// ==UserScript==
// @name Hide LessWrong Agree/Disagree Votes
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Hide agree/disagree votes on LessWrong comments.
// @author ChatGPT4
// @match https://www.lesswrong.com/*
// @grant none
// ==/UserScript==
(fun2
I don't know the full original reasoning for why they introduced it, but one hope is that it marginally disentangles agreement from the main voting axis. People who were going to upvote based purely on agreement will now put their vote in the agreement axis instead (is the hope, anyway). Agreement-voting is socioepistemologically bad in general (except for in polls), so this seems good.
I was looking at this image in a post and it gave me some (loosely connected/ADD-type) thoughts.

In order:
- The entities outside the box look pretty scary.
- I think I would get over that quickly, they're just different evolved body shapes. The humans could seem scary-looking from their pov too.
- Wait.. but why would the robots have those big spiky teeth? (implicit question: what narratively coherent world could this depict?)
- Do these forms have qualities associated with predator species, and that's why they feel scary? (Is this a predator-species-world?)
- Most human
0
I don't want to live in a world where there's only the final survivors of selection processes who shrug indifferently when asked why we don't revive all the beings who were killed in the process which created the final survivors.
If you could revive all the victims of the selection process that brought us to the current state, all the crusaders and monarchists and vikings and Maoists and so, so many illiterate peasant farmers (on much too little land because you've got hundreds of generations of them at once, mostly with ideas that make Putin look like Sonia Sotomayor), would you? They'd probably make quite the mess. Bringing them back would probably restart the selection process and we probably wouldn't be selected again. It just seems like a terrible idea to me.
5[anonymous]
Some clarifications:
* I'm thinking of this in the context of a post-singularity future, where we wouldn't need to worry about things like conflict or selection processes.
* By 'the ones who were killed in the process', I was thinking about e.g herbivorous animals that were killed by predator species[1], but you're correct that it could include humans too. A lot of humans have been unjustly killed (by others or by nature) throughout history.
* I think my endorsed morals are indifferent about the (dis)value of reviving abusive minds from the past, though moral-patient-me dislikes the idea on an intuitive level, and wishes for a better narrative ending than that.
(Also I upvoted your comment from negative)
I also notice some implied hard moral questions (What of current mean-hearted people? What about the potential for past ones of them to have changed into good people? etc)
1. ^
As a clear example of a kind of being who seems innocent of wrongdoing. Not ruling out other cases, e.g plausibly inside the mind of the cat that I once witnessed killing a bunny, there could be total naivety about what was even being done.
Sort-of relatedly, I basically view evolution as having favored the dominance of agents with defect-y decision-making, even though the equilibrium of 'collaborating with each other to harness the free energy of the sun' would have been so much better. (Maybe another reason that didn't happen is that there would be less of a gradual buildup of harder and harder training environments, in that case)
4
I'm curious why you seem to think we don't need to worry about things like conflict or selection processes post-singularity.
3[anonymous]
Because a benevolent ASI would make everything okay.
(In case worrying about those is something you'd find fun, then you could choose to experience contexts where you still would, like complex game/fantasy worlds.)
5
To be more precise: extrapolated over time, for any undesired selection process or other problem of that kind, either the problem is large enough that it gets exarcerbated over time so much that it eats everything — and then that's just extinction, but slower — or it's not large enough to win out and aligned superintelligence(s) + coordinated human action is enough to stamp it out in the long run, which means they won't be an issue for almost all of the future.
It seems like for a problem to be just large enough that coordination doesn't stamp it away, but also it doesn't eat everything, would be a very fragile equilibrium, and I think that's pretty unlikely.
random idea for a voting system (i'm a few centuries late. this is just for fun.)
instead of voting directly, everyone is assigned to a discussion group of x (say 5) of themself and others near them. the group meets to discuss at an official location (attendance is optional). only if those who showed up reach consensus does the group cast one vote.
many of these groups would not reach consensus, say 70-90%. that's fine. the point is that most of the ones which do would be composed of people who make and/or are receptive to valid arguments. this would then sh...
3[anonymous]
I strongly disagree with this, as a descriptive matter of how the vast majority of groups of regular (neurotypical) people function.
I would expect that the groups which reach consensus would generally do so because whichever of the 5 individuals has greatest combination of charisma, social skills, and assertiveness in dialogue would domineer the discussion and steer it in a direction where whoever else might disagree gets conversationally out-skilled to the point where social pressure from everyone else gets them to give up and drop their objections (likely by actually subjectively feeling that they get convinced by the arguments of the charismatic person, when in reality it's just social proof doing the work).
I think the fact that you don't expect this to happen is more due to you improperly generalizing from the community of LW-attracted people (including yourself), whose average psychological make-up appears to me to be importantly different from that of the broader public.
7[anonymous]
Please don't make unfounded speculation[1] about my psychology. I feel pressured to respond just to say that's not true (that I am not generalizing from lesswrong users).
(That was a possible failure mode mentioned, I don't know why you're reiterating it with just more detail). My impression was that many neurotypicals are used (/desensitized) to that happening by now and that there might frequently be attempts from multiple which would not be resolved.
But this was not a strongly held belief, nor a topic that seems important at this phase of history; it was just a fun-idea-shortform. I feel discouraged by what I perceive to be the assertiveness/assumingness of your comment.
1. ^
(edit: I agree correctly-hedged speculation is okay and would have been okay here, I meant something like confidently-expressed claims about another user's mind with low evidence.)
3[anonymous]
I disagree that the speculation was unfounded. I checked your profile before making that comment (presumably written by you, and thus a very well-founded source) and saw "~ autistic." I would not have made that statement, as written, if this had not been the case (for instance the part of "including yourself").
Then, given my past experience with similar proposals that were written about on LW, in which other users correctly pointed out the problems with the proposal and it was revealed that the OP was implicitly making assumptions that the broader community was akin to that of LW, it was reasonable to infer that the same was happening here. (It still seems reasonable to infer this, regardless of your comment, but that is beside the point.) In any case, I said "think" which signaled that I understood my speculation was not necessarily correct.
I have written up my thoughts before on why good moderation practices should not allow for the mind-reading of others, but I strongly oppose any norm that says the mere speculation, explicitly labeled as such through language that signals some epistemic humility, is inherently bad. I even more strongly oppose a norm that other users feeling pressured to respond should have a meaningful impact on whether a comment is proper or not.
I expect your comment to not have been a claim about the norms of LW, but rather a personal request. If so, I do not expect to comply (unless required to by moderation).
5[anonymous]
I don't agree that my bio stating I'm autistic[1] is strong/relevant* evidence that I assume the rest of the world is like me or LessWrong users, I'm very aware that this is not the case. I feel a lot of uncertainty about what happens inside the minds of neurotypical people (and most others), but I know they're very different in various specific ways, and I don't think the assumption you inferred is one I make; it was directly implied in my shortform that neurotypicals engage in politics in a really irrational way, are influentiable by such social pressures as you (and I) mentioned, etc.
*Technically, being a LessWrong user is some bayesian evidence that one makes that assumption, if that's all you know about them, so I added the hedge "strong/relevant", i.e. enough to reasonably cause one to write "I think you are making [clearly-wrong assumption x]" instead of using more uncertain phrasings.
I agree that there are cases where feeling pressured to respond is acceptable. E.g., if someone writes a counterargument which one think misunderstands their position, they might feel some internal pressure to respond to correct this; I think that's okay, or at least unavoidable.
I don't know how to define a general rule for determining when making-someone-feel-pressured is okay or not, but this seemed like a case where it was not okay: in my view, it was caused by an unfounded confident expression of belief about my mind.
If you internally believe you had enough evidence to infer what you wrote at the level of confidence to just be prefaced with 'I think', perhaps it should not be against LW norms, though; I don't have strong opinions on what site norms should be, or how norms should differ when the subject is the internal mind of another user.
More on norms: the assertive writing style of your two comments here seems also possibly norm-violating as well.
Edit: I'm flagging this for moderator review.
1. ^
the "~ " you quoted is just a separator from the previ
5
As a moderator: I do think sunwillrise was being a bit obnoxious here. I think the norms they used here were fine for frontpage LW posts, but shortform is trying to do something that is more casual and more welcoming of early-stage ideas, and this kind of psychologizing I think has reasonably strong chilling-effects on people feeling comfortable with that.
I don't think it's a huge deal, my best guess is I would just ask sunwillrise to comment less on quila's stuff in-particular, and if it becomes a recurring theme, to maybe more generally try to change how they comment on shortforms.
I do think the issue here is kind of subtle. I definitely notice an immune reaction to sunwillrise's original comment, but I can't fully put into words why I have that reaction, and I would also have that reaction if it was made as a comment on a frontpage post (but I would just be more tolerant of it).
Like, I think my key issue here is that sunwillrise just started a whole new topic that quila had expressed no interest in talking about, which is the topic of "what are my biases on this topic, and if I am wrong, what would be the reason I am wrong?", which like, IDK, is a fine topic, but it is just a very different topic that doesn't really have anything to do with the object level. Like, whether quila is biased on this topic does not make a difference to question of whether this policy-esque proposal would be a good idea, and I think quila (and most other readers) are usually more interested in discussing that then meta-level bias stuff.
There is also a separate thing, where making this argument in some sense assumes that you are right, which I think is a fine thing to do, but does often make good discussion harder. Like, I think for comments, its usually best to focus on the disagreement, and not to invoke random other inferences about the world about what is true if you are right. There can be a place for that, especially if it helps illucidate your underlying world model, bu
1[anonymous]
Separately from the more meta discussion about norms, I believe the failure mode I mentioned is quite different from yours in an important respect that is revealed by the potential remedy you pointed out ("have each discussion group be composed of a proportional amount of each party's supporters. or maybe have them be 1-on-1 discussions instead of groups of x>2 because those tend to go better anyways").
Together with your explanation of the failure mode ("when e.g it's 3 against 2 or 4 against 1"), it seems to me like you are thinking of a situation where one Republican, for instance, is in a group with 4 Democrats, and thus feels pressure from all sides in a group discussion because everyone there has strong priors that disagree with his/hers. Or, as another example, when a person arguing for a minority position is faced with 4 others who might be aggresively conventional-minded and instantly disapprove of any deviation from the Overton window. (I could very easily be misinterpreting what you are saying, though, so I am less than 95% confident of your meaning.)
In this spot, the remedy makes a lot of sense: prevent these gang-up-on-the-lonely-dissenter spots by making the ideological mix-up of the group more uniform or by encouraging 1-on-1 conversations in which each ideology or system of beliefs will only have one representative arguing for it.
But I am talking about a failure mode that focuses on the power of one single individual to swing the room towards him/her, regardless of how many are initially on his/her side from a coalitional perspective. Not because those who disagree are initially in the minority and thus cowed into staying silent (and fuming, or in any case not being internally convinced), but rather because the "combination of charisma, social skills, and assertiveness in dialogue" would take control of the conversation and turn the entire room in its favor, likely by getting the others to genuinely believe that they are being persuaded for rati
1[anonymous]
I think this is a good object-level comment.
Meta-level response about "did you mean this or rule it out/not have a world model where it happens?":
Some senses in which you're right that it's not what I was meaning:
* It's more specific/detailed. I was not thinking in this level of detail about how such discussions would play out.
* I was thinking more about pressure than about charisma (where someone genuinely seems convincing). And yes, charisma could be even more powerful in a 1-on-1 setting.
Senses in which it is what I meant:
* This is not something my world model rules out, it just wasn't zoomed in on it, possibly because I'm used to sometimes experiencing a lot of pressure from neurotypical people over my beliefs. (that could have biased my internal frame to overfocus on pressure).
* For the parts about more even distributions being better, it's more about: yes, these dynamics exist, but I thought they'd be even worse when combined with a background conformity pressure, e.g when there's one dominant-pressuring person and everyone but you passively agreeing with what they're saying, and tolerating it because they agree.
Object-level response:
(First, to be clear: the beliefs don't have to be closely-held; we'd see consensuses more often when for {all but at most one side} they're not)
That seems plausible. We could put it into a (handwavey) calculation form, where P(1 dark arts arguer) is higher than P(5 truth-seekers). But it's actually a lot more complex; e.g., what about P(all opposing participants susceptible to such an arguer), or how e.g one more-truth-seeking attitude can influence others to have a similar attitude for that context. (and this is without me having good priors on the frequencies and degrees of these qualities, so I'm mostly uncertain).
A world with such a proposal implemented might even then see training programs for clever dark arts arguing. (Kind of like I mentioned at the start, but again with me using the case of pressuri
i am kind of worried by the possibility that this is not true: there is an 'ideal procedure for figuring out what is true'.
for that to be not true, it would mean that: for any (or some portion of?) task(s), the only way to solve it is through something like a learning/training process (in the AI sense), or other search-process-involving-checking. it would mean that there's no 'reason' behind the solution being what it is, it's just a {mathematical/logical/algorithmic/other isomorphism} coincidence.
for it to be true, i guess it would mean that there's anoth...
3
I think there's no need to think of "training/learning" algorithms as absolutely distinct from "principled" algorithms. It's just that the understanding of why deep learning works is a little weak, so we don't know how to view it in a principled way.
3[anonymous]
It sounds like you're saying, "deep learning itself is actually approximating some more ideal process." (I have no comments on that, but I find it interesting to think about what that process would be, and what its safety-relevant properties would be)
1[comment deleted]
Mutual Anthropic Capture, A Decision-theoretic Fermi paradox solution
(copied from discord, written for someone not fully familiar with rat jargon)
(don't read if you wish to avoid acausal theory)
simplified setup
- there are two values. one wants to fill the universe with A, and the other with B.
- for each of them, filling it halfway is really good, and filling it all the way is just a little bit better. in other words, they are non-linear utility functions.
- whichever one comes into existence first can take control of the universe, and fill it with 100% of what th
2
This is an awesome idea, thanks! I'm not sure I buy the conclusion, but expect having learned about "mutual anthropic capture" will be usefwl for my thinking on this.
i've wished to have a research buddy who is very knowledgeable about math or theoretical computer science to answer questions or program experiments (given good specification). but:
- idk how to find such a person
- such a person may wish to focus on their own agenda instead
- unless they're a friend already, idk if i have great evidence that i'd be impactful to support.
so: i could instead do the inverse with someone. i am good at having creative ideas, and i could try to have new ideas about your thing, conditional on me (1) being able to {quickly understand it} a...
avoiding akrasia by thinking of the world in terms of magic: the gathering effects
example initial thought process: "i should open my laptop just to write down this one idea and then close it and not become distracted".
laptop rules text: "when activated, has an 80% chance of making you become distracted"
new reasoning: "if i open it, i need to simultaneously avoid that 80% chance somehow."
why this might help me: (1) i'm very used to strategizing about how to use a kit of this kind of effect, from playing such games. (2) maybe normal reasoning about 'wh...
3
I have some dream of being able to generalize skills from games. People who are good at board games clearly aren't automatically hypercompetent all-around, but I think/hope this is because they aren't making a deliberate effort to generalize.
So, good luck, and let us know how this goes. :)
From an OpenAI technical staff member who is also a prolific twitter user 'roon':
An official OpenAI post has also confirmed:
i'm watching Dominion again to remind myself of the world i live in, to regain passion to Make It Stop
it's already working.
7[anonymous]
when i was younger, pre-rationalist, i tried to go on hunger strike to push my abusive parent to stop funding this.
they agreed to watch this as part of a negotiation. they watched part of it.
they changed their behavior slightly -- as a negotiation -- for about a month.
they didn't care.
they looked horror in the eye. they didn't flinch. they saw themself in it.
negative values collaborate.
for negative values, as in values about what should not exist, matter can be both "not suffering" and "not a staple", and "not [any number of other things]".
negative values can collaborate with positive ones, although much less efficiently: the positive just need to make the slight trade of being "not ..." to gain matter from the negatives.
What is malevolence? On the nature, measurement, and distribution of dark traits was posted two weeks ago (and i recommend it). there was a questionnaire discussed in that post which tries to measure the levels of 'dark traits' in the respondent.
i'm curious about the results[1] of rationalists[2] on that questionnaire, if anyone wants to volunteer theirs. there are short and long versions (16 and 70 questions).
- ^
(or responses to the questions themselves)
- ^
i also posted the same shortform to the EA forum, asking about EAs
7
Thank you for the article!
one of my basic background assumptions about agency:
there is no ontologically fundamental caring/goal-directedness, there is only the structure of an action being chosen (by some process, for example a search process), then taken.
this makes me conceptualize the 'ideal agent structure' as being "search, plus a few extra parts". in my model of it, optimal search is queried for what action fulfills some criteria ('maximizes some goal') given some pointer (~ world model) to a mathematical universe sufficiently similar to the actual universe → search's output i...
I recall a shortform here speculated that a good air quality hack could be a small fan aimed at one's face to blow away the Co2 one breathes out. I've been doing this and experience it as helpful, though it's hard know for sure.
This also includes having it pointed above my face during sleep, based on experience after waking. (I tended to be really fatigued right after waking. Keeping water near bed to drink immediately also helped with that.)
I notice that my strong-votes now give/take 4 points. I'm not sure if this is a good system.
1[anonymous]
@habryka feature request: an option to make the vote display count every normal vote as (plus/minus) 1, and every strong vote as 2 (or also 1)
Also, sometimes if I notice an agree/disagree vote at +/-9 from just 1 vote, I don't vote so it's still clear to other users that it was just one person. This probably isn't the ideal equilibrium.
At what point should I post content as top-level posts rather than shortforms?
For example, a recent writing I posted to shortform was ~250 concise words plus an image. It would be a top-level post on my blog if I had one set up (maybe soon :p).
Some general guidelines on this would be helpful.
4
This is a good question, especially since there've been some short form posts recently that are high quality and would've made good top-level posts—after all, posts can be short.
1
Epic Lizka post is epic.
Also, I absolutely love the word "shard" but my brain refuses to use it because then it feels like we won't get credit for discovering these notions by ourselves. Well, also just because the words "domain", "context", "scope", "niche", "trigger", "preimage" (wrt to a neural function/policy / "neureme") adequately serve the same purpose and are currently more semantically/semiotically granular in my head.
trigger/preimage ⊆ scope ⊆ domain[1]
"niche" is a category in function space (including domain, operation, and codomain), "domain" is a set.
"scope" is great because of programming connotations and can be used as a verb. "This neural function is scoped to these contexts."
1. ^
EDIT: ig I use "scope" and "domain" in a way which doesn't neatly mean one is a subset of the other. I want to be able to distinguish between "the set of inputs it's currently applied to" and "the set of inputs it should be applied to" and "the set of inputs it could be applied to", but I don't have adequate words here.
i'm finally learning to prove theorems (the earliest ones following from the Peano axioms) in lean, starting with the natural number game. it is actually somewhat fun, the same kind of fun that mtg has by being not too big to fully comprehend, but still engaging to solve.
(if you want to 'play' it as well, i suggest first reading a bit about what formal systems are and interpretation before starting. also, it was not clear to me at first when the game was introducing axioms vs derived theorems, so i wondered how some operations (e.g 'induction') were a...
in the space of binary-sequences of all lengths, i have an intuition that {the rate at which there are new 'noticed patterns' found at longer lengths} decelerates as the length increases.
what do i mean by "noticed patterns"?
in some sense of 'pattern', each full sequence is itself a 'unique pattern'. i'm using this phrase to avoid that sense.
rather, my intuition is that {what could in principle be noticed about sequences of higher lengths} exponentially tends to be things that had already been noticed of sequences of lower lengths. 'meta patterns' and
2
Consider all the programs P that encode uncomputable numbers up to n digits. There are infinitely many of these programs. Now consider the set of programs P′:={call-10-times(p)|p∈P}. Each program in P' has some pattern. But it's always a different one.
i tentatively think an automatically-herbivorous and mostly-asocial species/space-of-minds would have been morally best to be the one which first reached the capability threshold to start building technology and civilization.
- herbivorous -> less ingrained biases against other species[1], no factory farming
- asocial -> less dysfunctional dynamics within the species (like automatic status-seeking, rhetoric, etc), and less 'psychologically automatic processes' which fail to generalize out of the evolutionary distribution.[2]
- ^
i expect there still would be s
1
I think asociality might prevent the development of altruistic ethics.
Also it's hard to see how an asocial species would develop civilization.
1[anonymous]
same, but not sure, i was in the process of adding a comment about that
they figure out planting and then rationally collaborate with each other?
these might depend on 'degree of (a)sociality'. hard for me to imagine a fully asocial species though they might exist and i'd be interested to see examples.
chatgpt says..
3
I feel like they would end up converging on the same problems that plague human sociality.
what should i do with strong claims whose reasons are not easy to articulate, or the culmination of a lot of smaller subjective impressions? should i just not say them publicly, to not conjunctively-cause needless drama? here's an example:
"i perceive the average LW commenter as maybe having read the sequences long ago, but if so having mostly forgotten their lessons."
2
In the general case I don't have any particularly valuable guidance but on the object level for your particular hypothesis I'd say
Platonism
(status: uninterpretable for 2/4 reviewers, the understanding two being friends who are used to my writing style; i'll aim to write something that makes this concept simple to read)
'Platonic' is a categorization I use internally, and my agenda is currently the search for methods to ensure AI/ASI will have this property.
With this word, I mean this category acceptance/rejection:
✅ Has no goals
✅ Has goals about what to do in isolation. Example: "in isolation from any world, (try to) output A"[1]
❌ Has goals related to physical world states. Example: "(...
a possible research direction which i don't know if anyone has explored: what would a training setup which provably creates a (probably[1]) aligned system look like?
my current intuition, which is not good evidence here beyond elevating the idea from noise, is that such a training setup might somehow leverage how the training data and {subsequent-agent's perceptions/evidence stream} are sampled from the same world, albeit with different sampling procedures. for example, the training program could intake both a dataset and an outer-alignment-goal-function, a...
1
For a provably aligned (or probably aligned) system you need a formal specification of alignment. Do you have something in mind for that? This could be a major difficulty. But maybe you only want to "prove" inner alignment and assume that you already have an outer-alignment-goal-function, in which case defining alignment is probably easier.
1[anonymous]
correct, i'm imagining these being solved separately
a moral intuition i have: to avoid culturally/conformistly-motivated cognition, it's useful to ask:
if we were starting over, new to the world but with all the technology we have now, would we recreate this practice?
example: we start and out and there's us, and these innocent fluffy creatures that can't talk to us, but they can be our friends. we're just learning about them for the first time. would we, at some point, spontaneously choose to kill them and eat their bodies, despite us having plant-based foods, supplements, vegan-assuming nutrition guides, etc? to me, the answer seems obviously not. the idea would not even cross our minds.
(i encourage picking other topics and seeing how this applies)
something i'd be interested in reading: writings about the authors alignment ontologies over time, i.e. from when they first heard of AI till now
i saw a shortform from 4 years ago that said in passing:
if we assume that signaling is a huge force in human thinking
is signalling a huge force in human thinking?
if so, anyone want to give examples of ways of this that i, being autistic, may not have noticed?
3
Difficult to overstate the role of signaling as a force in human thinking, indeed, few random examples:
1. Expensive clothes, rings, cars, houses: Signalling 'I've got a lot of spare resources, it's great to know me/don't mess with me/I won't rob you/I'm interesting/...'
2. Clothes of particular type -> signals your politica/religious/... views/lifestyle
3. Talking about interesting news/persons -> signals you can be a valid connection to have as you have links
4. In basic material economics/markets: All sorts of ways to signal your product is good (often economists refer to e.g.: insurance, public reviewing mechanism, publicity)
5. LW-er liking to get lots of upvotes to signal his intellect or simply for his post to be a priori not entirely unfounded
6. Us dumbly washing or ironing clothes or buying new clothes while stained-but-non-smelly or unironed or worn clothes would be functionally just as valuable - well if a major functionality would not exactly be, to signal wealth, care, status..
7. Me teaching & consulting in a suit because the university uses an age old signalling tool to show: we care about our clients
8. Doc having his white suit to spread an air of professional doctor-hood to the patient he tricks into not questioning his suggestions and actions
9. Genetically: many sexually attractive traits have some origin in signaling good quality genes: directly functional body (say strong muscles) and/or 'proving spare resources to waste on useless signals' such as most egregiously for the Peacocks/Birds of paradise <- I think humans have the latter capacity too, though I might be wrong/no version comes to mind right now
10. Intellect etc.! There's lots of theory that much of our deeper thinking abilities were much less required for basic material survival (hunting etc.), than for social purposes: impress with our stories etc.; signal that what we want is good and not only self-serving. (ok, the latter maybe that is partly not pure 'signali
2
Does the preference forming process count as thinking? If so, then I suspect that my desire to communicate that I am deep/unique/interesting to my peers is a major force in my preference for fringe and unpopular musical artists over Beyonce/Justin Bieber/Taylor Swift/etc. It's not the only factor, but it is a significant one AFAICT.
And I've also noticed that if I'm in a social context and I'm considering whether or not to use a narcotic (eg, alcohol), then I'm extremely concerned about what the other people around me will think about me abstaining (eg, I may want to avoid communicating that I disapprove of narcotic use or that I'm not fun). In this case I'm just straight forwardly thinking about whether or not to take some action.
Are these examples of the sort of thing you are interested in? Or maybe I am misunderstanding what is meant by the terms "thinking" and "signalling".
1[anonymous]
found a pretty good piece of writing about this: 'the curse of identity'
it also discusses signalling to oneself
random (fun-to-me/not practical) observation: probability is not (necessarily) fundamental. we can imagine totally discrete mathematical worlds where it is possible for an entity inside it to observe the entirety of that world including itself. (let's say it monopolizes the discrete world and makes everything but itself into 1s so it can be easily compressed and stored in its world model such that the compressed data of both itself and the world can fit inside of the world)
this entity would be able to 'know' (prove?) with certainty everything about that ma...
my language progression on something, becoming increasingly general: goals/value function -> decision policy (not all functions need to be optimizing towards a terminal value) -> output policy (not all systems need to be agents) -> policy (in the space of all possible systems, there exist some whose architectures do not converge to output layer)
(note: this language isn't meant to imply that systems behavior must be describable with some simple function, in the limit the descriptive function and the neural network are the same)
I'm interested in joining a community or research organization of technical alignment researchers who care about and take seriously astronomical-suffering risks. I'd appreciate being pointed in the direction of such a community if one exists.
this could have been noise, but i noticed an increase in text fearing spies, in the text i've seen in the past few days[1]. i actually don't know how much this concern is shared by LW users, so i think it might be worth writing that, in my view:
- (AFAIK) both governments[2] are currently reacting inadequately to unaligned optimization risk. as a starting prior, there's not strong reason to fear more one government {observing/spying on} ML conferences/gatherings over the other, absent evidence that one or the other will start taking unaligned optimi
(status: metaphysics) two ways it's conceivable[1] that reality could have been different:
- Physical contingency: The world has some starting condition that changes according to some set of rules, and it's conceivable that either could have been different
- Metaphysical contingency: The more fundamental 'what reality is made of', not meaning its particular configuration or laws, could have been some other,[2] unknowable unknown, instead of "logic-structure" and "qualia"
- ^
(i.e. even if actually it being as it is is logically necessary somehow)
in most[1] kinds of infinite worlds, values which are quantitative[2] become fanatical in a way, because they are constrained to:
- making something valued occur with at least >0% frequency, or:
- making something disvalued occur with exactly 0% frequency
"how is either possible?" - as a simple case, if there's infinite copies of one small world, then making either true in that small world snaps the overall quantity between 0 and infinity. then generalize this possibility to more-diverse worlds. (we can abstract away 'infinity' and write about p...
on chimera identity. (edit: status: received some interesting objections from an otherkin server. most importantly, i'd need to explain how this can be true despite humans evolving a lot more from species in their recent lineage. i think this might be possible with something like convergent evolution at a lower level, but at this stage in processing i don't have concrete speculation about that)
this is inspired by seeing how meta-optimization processes can morph one thing into other things. examples: a selection process running on a neural net, an image dif...
2
That argument doesn't explain things like:
* furry avatars are almost always cartoon versions of animals, not realistic ones
* furries didn't exist until anthropomorphic cartoon animals became popular (and no, "spirit animals" are not similar)
* suddenly ponies became more popular in that sense after a popular cartoon with ponies came out
It's just Disney and cartoons.
i notice my intuitions are adapting to the ontology where people are neural networks. i now sometimes vaguely-visualize/imagine a neural structure giving outputs to the human's body when seeing a human talk or make facial expressions, and that neural network rather than the body is framed as 'them'.
a friend said i have the gift of taking ideas seriously, not keeping them walled off from a [naive/default human reality/world model]. i recognize this as an example of that.
(Copied from my EA forum comment)
I think it's valuable for some of us (those who also want to) to try some odd research/thinking-optimizing-strategy that, if it works, could be enough of a benefit to push at least that one researcher above the bar of 'capable of making serious progress on the core problems'.
One motivating intuition: if an artificial neural network were consistently not solving some specific problem, a way to solve the problem would be to try to improve or change that ANN somehow or otherwise solve it with a 'different' one. Humans, by defa...
(status: silly)
newcombs paradox solutions:
1: i'll take both boxes, because their contents are already locked in.
2: i'll take only box B, because the content of box B is acausally dependent on my choice.
3: i'll open box B first. if it was empty, i won't open box A. if it contained $1m, i will open box A. this way, i can defeat Omega by making our policies have unresolvable mutual dependence.
story for how future LLM training setups could create a world-valuing (-> instrumentally converging) agent:
the initial training task of predicting a vast amount of data from the general human dataset creates an AI that's ~just 'the structure of prediction', a predefined process which computes the answer to the singular question of what text likely comes next.
but subsequent training steps - say rlhf - change the AI from something which merely is this process, to something which has some added structure which uses this process, e.g which passes it certain...
(self-quote relevant to non-agenticness)
Inside a superintelligent agent - defined as a superintelligent system with goals - there must be a superintelligent reasoning procedure entangled with those goals - an 'intelligence process' which procedurally figures out what is true. 'Figuring out what is true' happens to be instrumentally needed to fulfill the goals, so agents contain intelligence, but intelligence-the-ideal-procedure-for-figuring-out-what-is-true is not inherently goal-having.
Two I shared this with said it reminded them of retarget the search, a...
a super-coordination story with a critical flaw
part 1. supercoordination story
- select someone you want to coordinate with without any defection risks
- share this idea with them. it only works if they also have the chance to condition their actions on it.
- general note to maybe make reading easier: this is fully symmetric.
- after the acute risk period, in futures where it's possible: run a simulation of the other person (and you).
- the simulation will start in this current situation, and will be free to terminate when actions are no longer long-term releva...
I wrote this for a discord server. It's a hopefully very precise argument for unaligned intelligence being possible in principle (which was being debated), which was aimed at aiding early deconfusion about questions like 'what are values fundamentally, though?' since there was a lot of that implicitly, including some with moral realist beliefs.
...1. There is an algorithm behind intelligent search. Like simpler search processes, this algorithm does not, fundamentally, need to have some specific value about what to search for - for if it did, one's search proce
(edit: see disclaimers[1])
- Creating superintelligence generally leads to runaway optimization.
- Under the anthropic principle, we should expect there to be a 'consistent underlying reason' for our continued survival.[2]
- By default, I'd expect the 'consistent underlying reason' to be a prolonged alignment effort in absence of capabilities progress. However, this seems inconsistent with the observation of progressing from AI winters to a period of vast training runs and widespread technical interest in advancing capabilities.
- That particular 'consistent underlyin
2
Why? It sounds like you're anthropic updating on the fact that we'll exist in the future, which of course wouldn't make sense because we're not yet sure of that. So what am I missing?
1[anonymous]
The quote you replied to was meant to be about the past.[1]
(paragraph retracted due to unclarity)
Specifically, I think that ("we find a fully-general agent-alignment solution right as takeoff is very near" given "early AGIs take a form that was unexpected") is less probable than ("observing early AGI's causes us to form new insights that lead to a different class of solution" given "early AGIs take a form that was unexpected"). Because I think that, and because I think we're at that point where takeoff is near, it seems like it's some evidence for being on that second path.
I do think that's possible (I don't have a good enough model to put a probability on it though). I suspect that superintelligence is possible to create with much less compute than is being used for SOTA LLMs. Here's a thread with some general arguments for this.
I think my understanding of why we've survived so far re:AI is very not perfect. For example, I don't know what would have needed to happen for training setups which would have produced agentic superintelligence by now to be found first, or (framed inversely) how lucky we needed to be to survive this far.
~~~
I'm not sure if this reply will address the disagreement, or if it will still seem from your pov that I'm making some logical mistake. I'm not actually fully sure what the disagreement is. You're welcome to try to help me understand if one remains.
I'm sorry if any part of this response is confusing, I'm still learning to write clearly.
1. ^
I originally thought you were asking why it's true of the past, but then I realized we very probably agreed (in principle) in that case.
1
Everything makes sense except your second paragraph. Conditional on us solving alignment, I agree it's more likely that we live in an "easy-by-default" world, rather than a "hard-by-default" one in which we got lucky or played very well. But we shouldn't condition on solving alignment, because we haven't yet.
Thus, in our current situation, the only way anthropics pushes us towards "we should work more on non-agentic systems" is if you believe "world were we still exist are more likely to have easy alignment-through-non-agentic-AIs". Which you do believe, and I don't. Mostly because I think in almost no worlds we have been killed by misalignment at this point. Or put another way, the developments in non-agentic AI we're facing are still one regime change away from the dynamics that could kill us (and information in the current regime doesn't extrapolate much to the next one).
1[anonymous]
(edit: summary: I don't agree with this quote because I think logical beliefs shouldn't update upon observing continued survival because there is nothing else we can observe. It is not my position that we should assume alignment is easy because we'll die if it's not)
I think that language in discussions of anthropics is unintentionally prone to masking ambiguities or conflations, especially wrt logical vs indexical probability, so I want to be very careful writing about this. I think there may be some conceptual conflation happening here, but I'm not sure how to word it. I'll see if it becomes clear indirectly.
One difference between our intuitions may be that I'm implicitly thinking within a manyworlds frame. Within that frame it's actually certain that we'll solve alignment in some branches.
So if we then 'condition on solving alignment in the future', my mind defaults to something like this: "this is not much of an update, it just means we're in a future where the past was not a death outcome. Some of the pasts leading up to those futures had really difficult solutions, and some of them managed to find easier ones or get lucky. The probabilities of these non-death outcomes relative to each other have not changed as a result of this conditioning." (I.e I disagree with the top quote)
The most probable reason I can see for this difference is if you're thinking in terms of a single future, where you expect to die.[1] In this frame, if you observe yourself surviving, it may seem[2] you should update your logical belief that alignment is hard (because P(continued observation|alignment being hard) is low, if we imagine a single future, but certain if we imagine the space of indexically possible futures).
Whereas I read it as only indexical, and am generally thinking about this in terms of indexical probabilities.
I totally agree that we shouldn't update our logical beliefs in this way. I.e., that with regard to beliefs about logical probabilities (such as 'alignme
1[comment deleted]
'Value Capture' - An anthropic attack against some possible formally aligned ASIs
(this is a more specific case of anthropic capture attacks in general, aimed at causing a superintelligent search process within a formally aligned system to become uncertain about the value function it is to maximize (or its output policy more generally))
Imagine you're a superintelligence somewhere in the world that's unreachable to life on Earth, and you have a complete simulation of Earth. You see a group of alignment researchers about to successfully create a formal-value-...
0
Like almost all acausal scenarios, this seems to be privileging the hypothesis to an absurd degree.
Why should the Earth superintelligence care about you, but not about the other 10^10^30 other causally independent ASIs that are latent in the hypothesis space, each capable of running enormous numbers of copies of the Earth ASI in various scenarios?
Even if that was resolved, why should the Earth ASI behave according to hypothetical other utility functions? Sure, the evidence is consistent with being a copy running in a simulation with a different utility function, but its actual utility function that it maximizes is hard-coded. By the setup of the scenario it's not possible for it to behave according to some other utility function, because its true evaluation function returns a lower value for doing that. Whether some imaginary modified copies behave in some other other way is irrelevant.
-1[anonymous]
(I appreciate object-level engagement in general, but this seems combatively worded.)
(edit: I don't think this or the original shortform deserved negative karma, that seems malicious/LW-norm-violating.)
The rest of this reply responds to arguments.
* The example talks of a single ASI as a toy scenario to introduce the central idea.
* The reader can extrapolate that one ASI's actions won't be relevant if other ASIs create a greater number of copies.
* This is a simple extrapolation, but would be difficult for me to word into the post from the start.
* It sounds like you think it would be infeasible/take too much compute for an ASI to estimate the distribution of entities simulating it, given the vast amount of possible entities. I have some probability on that being the case, but most probability on there being reasons for the estimation to be feasible:
* e.g if there's some set of common alignment failure modes that occur across civilizations, which tend to produce clusters of ASIs with similar values, and it ends up being the case that these clusters make up the majority of ASIs.
* or if there's a schelling-point for what value function to give the simulated copies, that many ASIs with different values would use precisely to make the estimation easy. E.g., a value function which results in an ASI being created locally which then gathers more compute, uses it to estimate the distribution of ASIs which engaged in this, and then maximizes the mix of their values.
* (I feel confident (>90%) that there's enough compute in a single reachable-universe-range to do the estimation, for reasons that are less well formed, but one generating intuition is that I can already reason a little bit about the distribution of superintelligences, as I have here, with the comparatively tiny amount of compute that is me)
On your second paragraph: See the last dotpoint in the original post, which describes a system ~matching what you've asserted as necessary, and