"Mastering Atari Games with Limited Data", Ye et al 2021:
Reinforcement learning has achieved great success in many applications. However, sample efficiency remains a key challenge, with prominent methods requiring millions (or even billions) of environment steps to train. Recently, there has been significant progress in sample efficient image-based RL algorithms; however, consistent human-level performance on the Atari game benchmark remains an elusive goal.
We propose a sample efficient model-based visual RL algorithm built on MuZero, which we name EfficientZero. Our method achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperforms the state SAC in some tasks on the DMControl 100k benchmark. This is the first time an algorithm achieves super-human performance on Atari games with such little data. EfficientZero's performance is also close to DQN's performance at 200 million frames while we consume 500 times less data.
EfficientZero's low sample complexity and high performance can bring RL closer to real-world applicability. We implement our algorithm in an easy-to-understand manner and it is available at this https URL. We hope it will accelerate the research of MCTS-based RL algorithms in the wider community.
This work is supported by the Ministry of Science and Technology of the People’s Republic of China, the 2030 Innovation Megaprojects “Program on New Generation Artificial Intelligence” (Grant No. 2021AAA0150000).
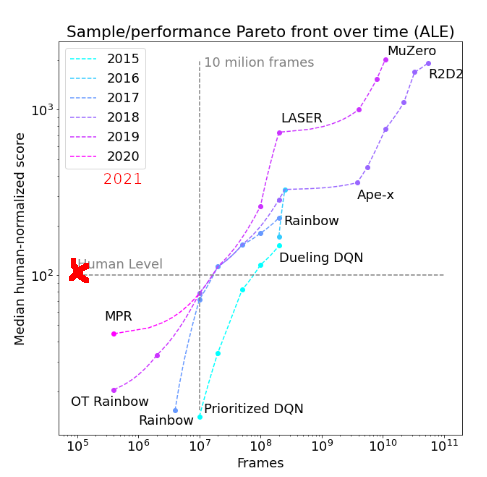
Some have said that poor sample-efficiency on ALE has been a reason to downplay DRL progress or implications. The primary boost in EfficientZero (table 3), pushing it past the human benchmark, is some simple self-supervised learning (SimSiam on predicted vs actual observations).
Personal opinion:
Progress in model-based RL is far more relevant to getting us closer to AGI than other fields like NLP or image recognition or neuroscience or ML hardware. I worry that once the research community shifts its focus towards RL, the AGI timeline will collapse - not necessarily because there are no more critical insights left to be discovered, but because it's fundamentally the right path to work on and whatever obstacles remain will buckle quickly once we throw enough warm bodies at them. I think - and this is highly controversial - that the focus on NLP and Vision Transformer has served as a distraction for a couple of years and actually delayed progress towards AGI.
If curiosity-driven exploration gets thrown into the mix and Starcraft/Dota gets solved (for real this time) with comparable data efficiency as humans, that would be a shrieking fire alarm to me (but not to many other people I imagine, as "this has all been done before").