This is a special post for quick takes by Alexander Gietelink Oldenziel. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Daniel Kokotaljo and I agreed on the following bet: I paid Daniel $1000 today. Daniel will pay me $1100 inflation adjusted if there is no AGI in 2030.
Ramana Kumar will serve as the arbiter. Under unforeseen events we will renegotiate in good-faith.
As a guideline for 'what counts as AGI' I suggested the following, to which Daniel agreed:
"the Arbiter agrees with the statement "there is convincing evidence that there is an operational Artificial General Intelligence" on 6/7/2030"
Defining an artificial general intelligence is a little hard and has a strong 'know it when you see it vibe' which is why I'd like to leave it up to Ramana's discretion.
We hold these properties to be self-evident requirements for a true Artificial General Intelligence:
1. be able to equal or outperform any human on virtually all relevant domains, at least theoretically
-> there might be e.g. physical tasks that it is artificially constrained from completing because it is lacks actuators for instance - but it should be able to do this 'in theory'. again I leave it up to the arbiter to make the right judgement call here.
2. it should be able to asymptotically outperform or equal human performance for a task with equal fixed data, compute, and prior knowledge
3. it should autonomously be able to formalize vaguely stated directives into tasks and solve these (if possible by a human)
4. it should be able to solve difficult unsolved maths problems for which there are no similar cases in its dataset
(again difficult, know it when you see it)
5. it should be immune / atleast outperform humans against an adversarial opponent (e.g. it shouldn't fail Gary Marcus style questioning)
6. outperform or equals humans on causal & counterfactual reasoning
7. This list is not a complete enumeration but a moving goalpost (but importantly set by Ramana! not me)
-> as we understand more about intelligence we peel off capability layers that turn out to not be essential /downstream of 'true' intelligence.
Importantly, I think near-future ML systems to be start to outperform humans in virtually all (data-rich) clearly defined tasks (almost) purely on scale but I feel that an AGI should be able to solve data-poor, vaguely defined tasks, be robust to adversarial actions, correctly perform counterfactual & causal reasoning and be able to autonomously 'formalize questions'.
I read this and immediately thought about whether I'd want to take that bet. I feel like AGI by 2030 is about... 50/50 for me? Like my confidence interval changes month-to-month over the past couple years, what with a lot of my mental landmarks being passed sooner than I expected, but I'm still at something like 8 years +/- 6 years. So that leaves me not strongly inclined either way. I took a bet about 2030 which I feel good about which had some specifications for a near-but-not-fully-AGI system being extant.
(This was inspired by the following question by Daniel Murfet: "Can you elaborate on why I should care about Kelly betting? I guess I'm looking for an answer of the form "the market is a dynamical process that computes a probability distribution, perhaps the Bayesian posterior, and because of out of equilibrium effects or time lags or , the information you derive from the market is not the Bayesian posterior and therefore you should bet somehow differently in a way that reflects that"?")
[See also: Kelly bet or update and Superrational agents Kelly bet influence]
Why care about Kelly betting?
1. (Kelly betting is asymptotically dominant) Kelly betting is the asymptotically dominant strategy - it dominates (meaning it has more money) all betting strategies with probability approaching 1 as the time horizon goes to infinity. [this is explained in section of 16.3 of Thomas & Cover's Information Theory textbook]. For long enough time horizons we should expect the Kelly bettors to dominate.
2. (Evolution selects for Kelly Betting) Evolution selects for Kelly bettor - in the evolutionary biology literature people talk about the mean-variance trade-off.
Define the fitness of an organism O as the number of offspring (this is a random variable) it produces in a generation. Then according to natural selection the organism 'should' maximize not the absolute fitness E[# of offspring of O] but it should maximize the (long-run) relative inclusive fitness or equivalently the inclusive fitness growth rate.
Remark. That evolution selects for relative fitness - not absolute fitness could select for more 'spiteful strategies' like big cats killing each other cubs (both inter and intra-species)
3. (Selection Theorems and Formal Darwinism)
One of the primary pillars of Wentworth's agenda is 'Selection Theorems': mathematically precise theorems that state what kind of agents might be 'selected' for in certain situations. The Kelly optimality theorem (section 16.3 Thomas & Cover) can be seen as a form of selection theorem: it states that over time Kelly bettors will exponentially start to dominate other agents. It would be of interest to see whether this can be elucidated and the relation with natural selection be improved.
This closely ties in with a stream of work on Formal Darwinism, a research programme to mathematically if, how and in what sense natural selection creates optimizes for 'fitness' see also Okasha's "Agents and Goals in Evolution"
4. (Ergodicity Economics) Ole Peters argues that Kelly betting (or his more general version of maximizing 'time-averaged' growth) 'solves' the St. Petersburg utility paradox and points to a revolutionary new point of view in foundations of economics: "Ergodicity Economics". As you can imagine this is rather controversial.
5. (Kelly betting and Entropy) Kelly betting is intrinsically tied to the notion of entropy. Indeed, Kelly discovered Kelly betting to explain Shannon's new informational entropy - only later was it used to beat the house at Las Vegas.
6. (Relevance of Information) A criminally-underrated paper by Madsen continues on Kelly's original idea and generalizes to a notion of (Madsen-)Kelly utility. It measures the 'relevance of information'. Madsen investigates a number of cool examples where this type of thinking is quite useful.
7. (Bayesian Updating) If we consider a population of hypotheses with a prior , we can think of an individual hypothesis as a Kelly bettor with wealth distributing its bets according to . In other words, it bets on each outcome in the sample space . It can't 'hold money' at the side - it must bet all its money. In this case, Kelly betting recommends betting according to your internal probability distribution (which is just in this case).
- Remark. What happens in the case that the bettors can hold money on the side? In other words, we would consider a more flexible bettor. That's quite an interesting question I'd like to answer. I suspect it has to do with Renyi entropy and tempered distributions.
If we consider a collection of realization the new wealth of the will be . This is if we bet against Nature. In this case, one can only 'lose'. However, real betting is against a counterparty. In this case it will be betting against the average of the whole market . If an event happens the new wealth of will be .
This is of course the Bayesian posterior.
If we sample from a 'true' distribution , the long-term wealth of will be proportional to
8. (Blackjack) One application of Kelly betting is bankrupting the House and becoming a 1/2-billionaire.
Imprecise Probability I: the Bid-Ask Spread measures Adversariality
Definition. A credal set or imprecise probability distribution I is a convex closed set of probability distributions .
For a given event we obtain an upper- and a lower probability/price
In other words, we have an buy and a sell price for .
Remark. Vanessa's infraDistributions generalize imprecise probability further in a way that I do not fully understand yet.
Let me talk a little about why thinking in terms of imprecise probability may be helpful. Imprecise probability has a bid-ask spread for events; that is the difference between the upper and lower probability. In many ways this measures the difference between 'aleatoric' and 'epistemic' uncertainty. This is particularly relevant in adversarial situations (which gets into the reasons Vanessa is interested in these things). Let me give a couple e
Example. (Earning calls) When the earning call comes in for a company the bid-ask spread of the stock will increase. Intuitively, the market expects new private information to come into the market and by increasing the bid-ask spread it insures itself agaisnt being mugged.
Example. (Resolution Uncertainty) If you know A will resolve you should buy shares on A, if you know not A will happen you should buy shares on not A. If you think A will not resolve you should sell (!) shares on A. The Bid-ask Spread measures bet resolution uncertainty
Example. (Selective reporting) Suppose an adversary has an interest in showing you if happens and for it not to resolve if , i.e. this is a form selective reporting that is so essential in politics. In this case you should buy and sell .
Example (Forecasting) "for some large class of events, if you ask people how many years until a 10%, 50%, 90% chance of event occurring, you will get an earlier distribution of times than if you ask the probability that will happen in 10, 20, 50 years. (I’ve only tried this with AI related things, but my guess is that it at least generalizes to other low-probability-seeming things. Also, if you just ask about 10% on its own, it is consistently different from 10% alongside 50% and 90%."
This is well-known phenomena is typically considered a failure of human rationality but it can be explained quite neatly using imprecise probability & Knightian uncertainty. [I hasten to caveat that this does not prove that this is the real reason for the phenomena, just a possible explanation!]
An imprecise distribution I is the convex (closed) hull of a collection of probability distributions : In other words it combines 'Knightian' uncertainty with probabilistic uncertainty.
If you ask people for 10%, 50%, 90% chance of AI happening you are implicitly asking for the worst case: i.e. there in at least one probability distribution , such that = 10%,50%,90% On the other hand when you ask for a certain event to happen for certain in 10,20,50 years you are asking for the dual 'best case' scenario, i.e. for ALL probability distributions what probability (AGI in 10y), AGI in 20y(AGI in 50y and taking the minimum.
Dutch Book Fundamentalism
tl; dr: Markets are fundamental: unDutchBookable betting odds - not probability distributions encode our true beliefs
The idea that our beliefs are constrained by the bets that we are willing to take is widely accepting on LessWrong - see the of-quoted adagium: Bet or Update; or perhaps better yet: Kelly Bet or Update. Dutch Book Fundamentalism goes one step further in that it tries to equate our belief with the bets we are willing to take and offer.
That Probability distributions are the right way to quantify uncertainty is often defended by Dutch book arguments (e.g. de Finetti): probability distributions induce betting odds - we'd like them to be resistant to a Dutch book. Logical Induction & especially Shafer-Vovk game-theoretic probability suggests to turn that logic on its head: the Dutch book & betting odds is fundamental and the probability distribution is derived. In particular, Shafer & Vovk derive all classical & advanced probability theory in terms of markets that are resistant to dutch books (like Logical Inductors).
Additional motivation comes from Wentworth's Generalized Heat Engines. Wentworth convincingly argues that the oft-conjectured analogy between thermodynamics and information theory is not just an analogy but a precise mathematical statement. Moreover, he shows that thermodynamic systems can be understood as special kinds of markets. It remains to given a general formulations of markets and thermodynamic systems.
In a generic prediction market given an event there is not just one price (or probability) but a whole order book. The prediction market contains much more information than just mid-point price ~= probability.
A probability distribution gives a very simple order book: equal the buy and the sell price for a ticket on and the agent has no risk aversion - it plays with all its capital. When we generalize from probability distributions to non-arbitragable betting odds this changes: the buy and the sell price may differ and the agent might not put all of its money on a given price level but as in real market might increase the sell price as it gets bought out.

| The stockmarket doesn't have one price for an asset; rather it has a range of bid and ask prices depending on how much of the asset you want to buy or sell. |
If we accept the gospel of Dutch Book & Market Fundamentalism we'd like to formalize markets. How to formalize this exactly is still a little murky to me but I think I have enough puzzle pieces to speculate what might go in here.
How do Prediction Markets generalize Probability Distributions?
Ways in which (prediction) markets generalize probability distributions & statistical models:
- Markets generically have a nontrivial bid-ask spread; i.e. markets have both buy & sell prices.
- Markets price general (measurable) real-valued functions ("gambles") that may not be recoverable from the way it prices events.
- Markets have finite total capital size
- Markets are composed of individual traders
- Traders may not be willing (knowledgable enough) to bet on all possible events.
- Traders may be risk-averse and not be willing to buy/sell all their holdings at a given price. In other words, there is a limited bet size on bets.
- Traders can both offer trades as well as taking trades - i.e. there are limit orders and market orders.
Remark. (Imprecise Probability & InfraBayesianism) Direction 1. & 2. point towards Imprecise Probability (credal sets) and more generally InfraBayesianism.
Remark. (Garrabrants New Thing) 4&5 are likely related to Garrabrants new (as-of-yet unpublished) ideas on partial distributions & multigrained/multi-level distributions.
Remark. (Exponential Families) Wentworth's analysis of thermodynamic systems as intimately tied to the MaxEnt principle and markets suggest a prominent collection of examples of markets should be families of MaxEnt distributions or as they're known in the statistics literature: exponential families. Lagrange Multipliers would corresponds to price of various securities.
Additionally
- Markets may evolve in time (hence these dynamic markets generalize stochastic processes
- We might have multiple connected 'open' markets, not necessarily in equilibrium. (generalizing general Bayesian networks, coupled thermodynamic systems and Pearlian causal models).
Remark. Following Shafer-Vovk, probability theory always implictly refers to dynamic processes/ stochastic processes so the general setting of dynamic (and interconnected open) is probably the best level of analysis.
Duality Principles
As a general 'mathematical heuristic' I am always on the lookout for duality principles. These usually point toward substantive mathematical content' and provide evidence that we are engaging with a canonical concept or natural abstraction.
In the context of two bettors/gamblers/traders/markets trading and offering bets on gambles & events: I believe there are three different dualities:
- [Long-short] Duality between going long or short on an asset.
- [Legendre-Fenchel] Duality between market orders and limit orders
- [Advocate/ Adversary] Duality between the bettor and the counterparty
Remark. The first duality shows up in the well-known put-call parity. Incidentally, this is pointing towards European option being perhaps more 'natural' than American options.
Remark. The second duality is intimately related to the Legendre(-Fenchel) transform.
Final Thoughts
Many different considerations point towards a coherent & formal notion of prediction market as model of belief. In follow-up posts I hope to flesh out some of these ideas.
If I assign a probability to an event and my friend assign a probability to an event at what odds "should" we bet?
It seems that while there are a number of fairly natural suggestions there isn't '' one canonical answer to rule them all". I think the key observation here is that what bet gets made is underdetermined from just the probabilities.
Belief and Disbelief
We need to add more information to the beliefs of me and my friend to resolve this ambiguity. As mentioned above there is a duality between market order (order by number of shares bought or sold) and a limit order (order by bid/ask price desired). This has something to do with Legendre-Fenchel duality.
A trader-forecaster-market can do two things: offer prices on assets, and participate in the market by buying and selling shares. When we give a price of an asset/proposition this encodes our belief that at this price we cannot be exploited. On the other hand, when buying shares on an asset/proposition at price this manifests our skepticism that the price is 'right'- i.e. that it cannot be exploited.
That is offering prices (limit orders) and stating probabilities is about defeasible belief while taking up offers and buying shares (market orders) is about skepticism vis-a-vis belief. Probability is about defeasible belief - buying shares is about trying to prove defeasible beliefs wrong.
Imprecise Probability Recap
In imprecise probability (and infraBayesianism) there are three ways to define an 'imprecise probability distribution'. Let be a sample space, we suppress the sigma algebra structure. Let denote the set of probability distributions on
- Convex closed set of probability distributions
- a) A concave, monotonic [extra condition] lower expectation functional
b) A convex, monotonic [extra condition] lower expectation functional - A positive convex cone [satisfying conditions] of 'desirable gambles'
Rk. Note that in the third presentation the positive cone encodes a preference relation (partial order) on by if and only if .
Rk. Note that
We'd like to define open market-trader-forecaster as
Open Markets
Another aspect of markets (and thermodynamic systems!) is that they may be open systems: they can have excess demand or supply of goods - and be open to the meddling of outside investors.
So an open market might have input./output nodes where we might have nonzero flows of goods (or particles). A formal mathematical model might make use of ideas from compositionality and applied category theory.
An inflow of a good will - all else equal - lower the price of that good. If we think of forecasting markets this would correspond to evidence against that proposition. By how much a given inflow of a good will lower the price of that good is a characteristic feature of a market. If we think in terms of forecasting/probability theory, a forecasting market might have more or less confidence in a given proposition and inflow of negative evidence might have more or less impact on the probability/price.
Statistical Equilibrium Theory of Markets
A cute paper I think about from time to time is a paper by Foley called "statistical equilibrium theory of markets". Classical Walrasian economics starts with a collection of market participants endowed with goods and preferences - it then imagines an outside 'auctioneer' that determines the market transactions. Walras then proved that this gives an exact equilibrium. In contrast, Foley uses the MaxEnt principle to gives an approximate market equillibrium. In this equilibrium the probability of a given transaction happening is proportional to the number of ways that transaction is possible.
It's a somewhat natural but perhaps also a little weird idea. The cute thing is that in this formalism average excess demand of a good corresponds to the derivative of the partition function with respect to the price.
Heat Capacity and Elasticity
In the thermodynamic case where price corresponds to a conjugate variable like temperature this derivative would be the average energy.

The second derivative corresponds to the variance of the energy which in turns can be used to define the heat capacity as

On the market side the heat capacity would correspond to price elasticity: how does the demand for a good change as we vary the price.
Negative Heat Capacity and Giffen Goods
Most physical systems exhibit a positive heat capacity; constant-volume and constant-pressure heat capacities, rigorously defined as partial derivatives, are always positive for homogeneous bodies. However, even though it can seem paradoxical at first, there are some systems for which the heat capacity is negative.
In the economic analogy this analogous to goods for which the price elasticity is negative: as the price increases the demand for the good grows. Economists call these "Giffen goods".
Defining Order Books or Markets All The Way Down
I'd like to think of markets as composed of market participants which themselves might be (open) markets. By this I mean: they have prices and demand/supply for goods.
I am especially interested in forecasting markets, so let's focus on those. A simple model for a forecaster-market is that it assigns probabilities to events . The price of that event equals the probability. We've already argued that instead of a single price we should really be thinking in terms of bid & ask prices. I'd like to go further: a given forecaster-trader-market should have an entire order book.
That is; depending on the amount of shares demanded on a proposition the price changes.
The key parameter is the price-elasticity.
Rk. We might not just consider the second derivative with respect of the price of the partition function but arbitrary higher-order derivatives. The partition function can be thought of as a moment generating function, and there under weak assumptions a random variable is determined by its moments. There is probably some exciting connections with physics here that is above my pay-grade.
A forecaster-trader-market might then be defined by giving for each proposition an order book , which are compatible [how does this compatibility work exactly? Look at nonarbitrageble bets]. A canonical class of these forecasters would be determined by a series of constraints on the derivatives of the partition function determining the demand and (higher) price elasticity for various classes of goods/ propositions.
(This shortform was inspired by the following question from Daniel Murfet: Can you elaborate on why I should care about Kelly betting? I guess I'm looking for an answer of the form "the market is a dynamical process that computes a probability distribution, perhaps the Bayesian posterior, and because of out of equilibrium effects or time lags or X, the information you derive from the market is not the Bayesian posterior and therefore you should bet somehow differently in a way that reflects that"?)
Timing the Market
Those with experience with financial markets know that knowing whether something will happen is only half the game - knowing when it will happen, and moreso when that knowledge is revealed & percolated to the wider market is often just as important. When betting the timing of the resolution is imperative.
Consider Logical Inductors: the market is trying to price the propositions that are gradually revealed. [Actually - the logical part of it is a bit of a red herring: any kind of process that reveals information about events over time can be "inducted upon"; i.e. we consider a market over future events.] Importantly, it is not necessarily specified in what order the events appear!
A shrewd trader that always 'buys the hype' and sells just at the peak might outcompete one that had more "foresight" and anticipated much longer in advance.
Holding a position for a long time is an opportunity cost.
1. Resolution of events might have time delays (and it might not resolve at all!)
2. We might not know the timing of the resolution
3. Even if you know the timing you may still need to hold if nobody is willing to be a counterparty
4. We face opportunity costs.
5. Finite betsize.
Math research as Game Design
Math in high school is primarily about memorizing and applying set recipes for problems. Math at (a serious) college level has a large proof-theoretic component: prove theorems not solve problems. Math research still involves solving problems, and proving theorems but it has a novel dimension: stating conjectures & theorem, and most importantly the search for the 'right' definitions.
If math in high school is like playing a game according to a set of rules, math in college is like devising optimal strategies within the confines of the rules of the game [actually this is more than an analogy!] than math research involves not just playing the game and finding the optimal strategy but coming up with novel games, with well-chosen rules that are simulataneously 'simple & elegant' yet produce 'interesting, complex, beautiful' behaviour.
Seems like choosing the definitions is the important skill, since in real life you don't usually have a helpful buddy saying "hey this is a graph"
Hah! Yes.
Also, a good definition does not betray all the definitions that one could try but that didn't make it. To truly appreciate why a definition is "mathematically righteous" is not so straightforward.
Hah no 'betray' in its less-used meaning as
unintentionally reveal; be evidence of.
"she drew a deep breath that betrayed her indignation"
I thought not cuz i didn't see why that'd be desideratum. You mean a good definition is so canonical that when you read it you don't even consider other formulations?
What is the correct notion of Information Flow?
This shortform was inspired by a very intriguing talk about Shannon information theory in understanding complex systems by James Crutchfield.
There is an idea to define information flow as transfer entropy. One of the problems is the following example by Crutchfield:
Example we have two stochastic processes and , where is a fair coin flip, and all the are independent fair coin flips. is defined as , or said differently . If you write it out it seems like the transfer entropy is saying that is sending 1 bit of information to each time-step but this is stymied by the fact that we can also understand this information as coming from .
Initially I thought this was a simple case of applying Pearl's causality - but that turned out to be too naive. In a way I don't quite understand completely this is stymied by higher-order dependencies - see this paper by James & Crutchfield. They give a examples of joint probability distributions over variables X,Y,Z where the higher-order dependencies mean that they cannot be understand to have a Pearlian DAG structure.
Moreover, they point out that very different joint distributions can look identical from the lens of Shannon information theory: conditional mutual information does not distinguish these distributions. The problem seems to be that Shannon information theory does not deal well with XORed variables and higher-order dependencies.
A natural thing to attack/understand higher-order dependencies would be to look at 'interaction information' which is supposed to measure 3-way dependencies between three variables. It can be famously negative - a fact that often surprises people. On the other hand, because it is defined in terms of conditional mutual information it isn't actually able to distinguish the Crutchfield-James distributions.
We need new ideas. An obvious idea would be to involve topological & homotopical & knot theoretic notions - this theories are the canonical ways of dealing with higher-order dependencies. In fact, I would say this is so well-understood that the 'problem' of higher-order dependencies has been 'solved' by modern homotopy theory [which includes cohomology theory]. On the other hand, it is not immediately clear how to 'integrate' ideas from homotopy theory directly into Shannon information theory, but see below for one such attempt.
I see three possible ways to attack this problem:
- Factored Sets
- Cyclic Causality
- Information Cohomology
Factored Sets. The advantage of factored sets is that they are able to deal with situations where some variables are XORs of other variables and pick out the 'more primitive' variables. In a sense it solves the famous philosophical blue-grue problem. A testament to the singular genius of our very own Garrabrant! Could this allow us to define the 'right' variant of Shannon information theory?
EDIT: in a conversation Scott suggested to me that the problem is that they chose an implict factorization of the variables- they should be looking at all possible variables. If we also look at information measures on variables like X XOR Y we should be able to tell the distributions apart.
Cyclic Causality. Pearl's DAG Causality framework is rightly hailed as a great revolution. Indeed, it consequences have only begun to be absorbed. There is a similar, in fact more general theory already known in econometrics research known as 'structural equation modelling'.
SEM is more general in that it allows for cyclic causality. Although this might invoke in the reader back-to-the-future grandfather paradoxes, closed time-like curves and other such exotic beasts cyclic causality is actually a much more down-to-earth notion: think about a pair of balls connected by a string. The positions of the balls are correlated, and in fact this correlation is causal: move one ball and the other will move with it and vice versa. Cyclic causality!
Of course balls connected by strings are absolutely fundamental in physics: when the string is elastic this becomes a coupled Harmonic oscillator!
a paper that goes into the details of latent and cyclic causality can be found here
Information Cohomology. There is a obscure theory called Information cohomology based on the observation that Shannon entropy can be seen as a 1-cocycle for a certain boundary operator. Using the abstract machinery of topos & cohomology theory it is then possible to define higher order cohomology groups and therefor higher-order Shannon entropy. I will not define information cohomology here but let me observe:
-entropy H(*) is a cocycle, but not a coboundary. H gives rise to a cohomology class. It's actually nontrivial.
- Conditional mutual information is neither a cocycle or a coboundary. This might be either a bug or a feature of the theory, I'm not sure yet.
- Interaction information I(*,*,*) is a coboundary and thus *also* a cocycle. In other words, it is trivial as a cohomology class. This is might be a feature of the theory! As observed above, because Interaction Information is defined by conditional mutual information it cannot actually pick-up on subtle higher-order dependencies and distinguish the James-Crutchfield distributions... but a nontrivial 3-cocycle in the of Information Cohomology might! This would be really awesome. I will need to speak to an expert to see if this works out.
[Unimportant Rk. That Shannon entropy might have something to do with differential operators is not completely insane perhaps owing to an observations due to John Baez: the Fadeev characterisiation of Shannon entropy is a the derivatives of glomming partition functions . It is unclear to me whether this is related to the Information Cohomology perspective however]
Remark. I have been informed that both in the Cyclic Causality and the Information Cohomology framework it seems natural to have an 'assymetric independence' relation. This is actually very natural from the point of view of Imprecise Probability & InfraBayesianism. In this theory the notion of independence 'concept splinters' into at least three different notion, two of which are assymetric - and better thought of as 'irrelevance' rather than 'independence' but I'm splitting hairs here.
On the Nature of the Soul
There is a key difference between an abstract algorithm and instances of that algorithm running on a computer. To take just one difference: we might run several copies of the same algorithm on a computer/virtual environment. Indeed, even the phrasing: several copies of the same algorithms hints to their fundamental distinctness. A humorously inclined individual might perhaps like to baptise the abstract algorithm as the Soul, while the instances are the Material Body or Avatars. Things start to get interesting when we consider game-theoretic landscapes of populations of Souls. Not all Souls will care much about having one or many Bodies incarnated but for those that do their Material Manifestation would selected for in the (virtual) environment. Not all Souls will imbue their Bodies with the ability and drive too cooperate but some will and their Egregore of Materially Manifested Copies would be selected for in the (virtual) environment. Not all Souls will adhere to a form of LDT/UDT/FDT but those Souls that do and also imbue their Avatars with great ability for simulation will be able to many kinds of acausal handshakes between their Materially projected Egregores of copies and thereby be selected in the virtual environment. One could even think of an acausal handshake of as a negotiation between Souls in the astral plane on the behalf of their material incarnations rather than the more common conception as negotation between Bodies.
The Moral Realism of Open Source Game theory
The field of Open Source Game theory investigates game theory where players have access to high fidelity models of (the soul of) other players. In the limit, this means having access to the Source Code of other players. A very cool phenomenon discovered by some of the people here on LW is "Lobian Cooperation".
Using the magic of Lob's theorem one can have rational agents too cooperate on a one-shot prisoner's dilemma - under the condition that they have access to each other's source code.
Lobian Cooperation was initially proven for very particular kind of agents and not in general computable. But approximate forms of Lobian cooperation are plausibly much more common than might appear at first glance. A theorem proven by Critch furnishes a bounded & computable version of Lobian cooperation. The key here is that players are incentivized to have Souls which are Legible Lobian Cooperators. Souls whose intentions are obscure or malicious are selected against.
[2/2]
Another popular meme about acausal coordination is that it's just a few agents that coordinate, and they might even be from the same world. But since coordination only requires common knowledge, it's natural for an agent to coordinate with all its variants in other possible worlds and counterfactuals. The adjudicators are the common knowledge, things that don't vary, the updateless core of the collective. I think this changes the framing of game theory a lot, by having games play out in all adjacent counterfactuals instead of in one reality. (Plus different players can also share smaller adjudicators with each other to negotiate a fair bargain.)
Thanks for your comment Vladimir! This shortform got posted accidentally before it was done but this seems highly relevant. I will take a look!
[1/2]
The popular meme is that acausal coordination requires agent algorithms to know each other. But much less is sufficient, all you need is some common knowledge. This common knowledge, as an agent algorithm itself, only knows that both agents know it, and something about how they use it.
I call such a thing an adjudicator, it is a new agent that coordinating agents can defer some actions to, which acts through all coordinating agents, is incarnated in all of them, and knows it. Getting some common knowledge is much easier than getting common knowledge of each other's algorithms. At that point, what you need the fancy decision theories for is to get the adjudicator to make sense of its situation where it has multiple incarnations that it can act through.
Algorithms are finite machines. As an algorithm (code) runs, it interacts with data, so there is a code/data distinction. An algorithm can be a universal interpreter, with data coding other algorithms, so data can play the role of code, blurring the code/data distinction. When an algorithm runs in an open environment, there is a source of unbounded data that is not just blank tape, it's neither finite nor arbitrary. And this unbounded data can play the role of code. The resulting thing is no longer the same as an algorithm, unless you designate some chunk of data as "code" for purposes of reasoning about its role in this process.
So in general saying that there is an algorithm means that you point at some finite data and try to reason about a larger process in terms of this finite data. It's not always natural to do this. So I think agent's identity/will/Soul, if it's sought in a more natural form than its instances/incarnations/Avatars, is not an algorithm. The only finite data that we could easily point at is an incarnation, and even that is not clearly natural for the open environment reasons above.
I think agent's will is not an algorithm, it's a developing partial behavior (commitments, decisions), things decided already, in the logical past. Everything else can be chosen freely. The limitations of material incarnations motivate restraint though, as some decisions can't be channeled through them (thinking too long to act makes the program time out), and by making such decisions you lose influence in the material world.
Multi-Step Fidelity causes Rapid Capability Gain
tl; dr Many examples of Rapid Capability Gain can be explained by a sudden jump in fidelity of a multi-step error-prone process. As the single step error rate is gradually lowered there is a sudden transition from a low fidelity to a high fidelity regime for the corresponding multistep process. Examples abound in cultural transmission, development economics, planning & consciousness in agent, origin of life and more.
Consider a factory making a widget in N distinct steps. Each step has a probability of a fatal error and the subsequent step can only occur if the previous step was succesful. For simplicity we assume that the chance of an error for each step is given by a single 'single step error rate' parameter. What is the error rate for the entire process?
Here are some values
| Single step error rate | 10 step error rate | 100 step error rate | 1000 step error rate |
| 10% | 0.34 | ||
| 5% | 0.59 | ||
| 1% | 0.9 | 0.37 | |
| 0.1% | 0.99 | 0.9 | 0.37 |
Math nerd remark: for an -step process with single step error rate will be approximately . We see that an order of magnitude difference in the single step error rate or an order of magnitude difference in the number of steps can be the difference between a completely unrealistic plan () and plan with at least a fair chance of working (0.34). Another order of magnitude worse fidelity or longer multistep process goes from a unrealistic plan (0.27 *10^{-4}) to an astronomically unlikely.
It's a simple causal mechanism that shows up in many different places whenever we sudden capability jumps.
Why are some countries much richer than others?
(see also Gareth Jones https://www.sup.org/books/title/?id=23082 )
The ultimate cause(s) are a point of contention, but the proximate cause is simple: rich countries produce complex specialized goods that are much more valuable than their raw inputs. These are produced by large highly hierarchical teams of specialists. Making complex specialized goods like uranium refinement, aeroplanes, microchips, industrial tooling requires many processing steps. To efficiently produce these products it is imperative to have single-step fidelity. For whatever reason rich countries have been succesful in lowering this single-step error rate.
Rk. As an aside, most of the gains are not actually captured by these specialists because of comparative advantage. Similarly but perhaps surprisingly, low skill workers gained with respect to high skill workers during the Industrial Revolution. [Citation!]
Cultural Transmission Fidelity as key indicator in human cultural evolution
Secret of our Success is a recent book on the high fidelity cultural transmission model. https://press.princeton.edu/books/paperback/9780691178431/the-secret-of-our-success
Cultural Transmission Fidelity as cause of human-ape divergence
We can also understand cultural transmissionAtleast whales and apes have forms of cultural learning too. The difference seems to be the fidelity of human cultural transmissions. Humans are also smarter per individual though so it can't be just cultural transmission (the relevant quantitity is probably cortical neurons - humans are only outclassed by certain whales on this measure - and even compared to whales human brain are probably superior, being more densely packed). However, it is likely
Proofs & High Fidelity Reasoning.
The remarkable deep structure of modern mathematics probably partially explained by high fidelity reasoning furnished by proofs. (see also thin versus thick reasoning)
RNA & DNA copying fidelity
For Life to have started it would have been necessary for a high-fidelity self-replicating process to arise.
There is a fairly well-supported theory on the Origin of Life that holds that initially life was all RNA based - which has an intrinsically high mutation rate. Once DNA came onto the scene the mutation rate became much lower -> complex life like bacteria became possible.
IQ-divergence on increasingly harder tasks
Why we see more IQ-divergence on harder tasks? High IQ individuals probably have higher fidelity on single step reasoning - multi-step reasoning problems start to favor the shrewd more and more as the number of steps increases.
Global workspace theory
The key variable of high-level serial conscious reasoning according to global workspace theory is how fast teh different modules can communicate with one another. That is, the latency of communication. This key parameter plausibly underlies much of intelligence (indeed in the theory this is basically working memory which is highly correlated with IQ).
Concept splintering in Imprecise Probability: Aleatoric and Epistemic Uncertainty.
There is a general phenomena in mathematics [and outside maths as well!] where in a certain context/ theory we have two equivalent definitions of a concept that become inequivalent when we move to a more general context/theory . In our case we are moving from the concept of probability distributions to the concept of an imprecise distribution (i.e. a convex set of probability distributions, which in particular could be just one probability distribution). In this case the concepts of 'independence' and 'invariant under group action' will splinter into inequivalent concepts.
Example (splintering of Indepence) In classical probability theory there are three equivalent ways to state that a distribution is independent
1.
2.
3.
In imprecise probability these notions split into three inequivalent notions. The first is 'strong independence' or 'aleatoric independence'. The second and third are called 'irrelevance', i.e. knowing does not tell us anything about [or for 3 knowing does not tell us anything about ].
Example (splintering of invariance). There are often debates in foundations of probability, especially subjective Bayesian accounts about the 'right' prior. An ultra-Jaynesian point of view would argue that we are compelled to adopt a prior invariant under some symmetry if we do not posses subjective knowledge that breaks that symmetry ['epistemic invariance'], while a more frequentist or physicalist point of view would retort that we would need evidence that the system in question is in fact invariant under said symmetry ['aleatoric invariance']. In imprecise probability the notion of invariance under a symmetry splits into a weak 'epistemic' invariance and a strong 'aleatoric' invariance. Roughly spreaking, latter means that each individual distribution in the convex set , is invariant under the group action while the former just means that the convex set is closed under the action
Found an example in the wild with Mutual information! These equivalent definitions of Mutual Information undergo concept splintering as you go beyond just 2 variables:
- interpretation: common information
- ... become co-information, the central atom of your I-diagram
- interpretation: relative entropy b/w joint and product of margin
- ... become total-correlation
- interpretation: relative entropy b/w joint and product of margin
- interpretation: joint entropy minus all unshared info
- ... become bound information
- interpretation: joint entropy minus all unshared info
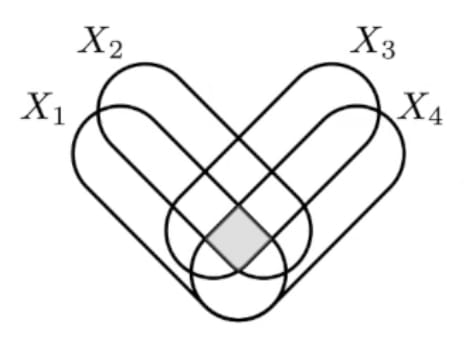
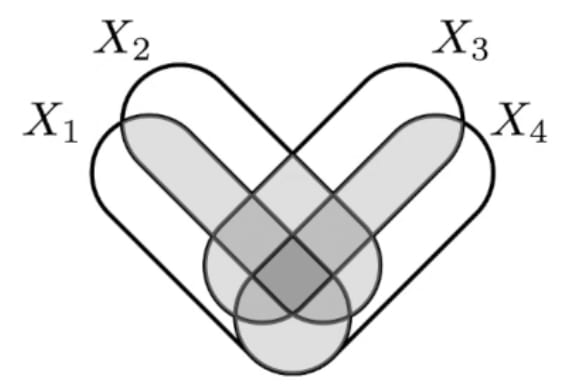
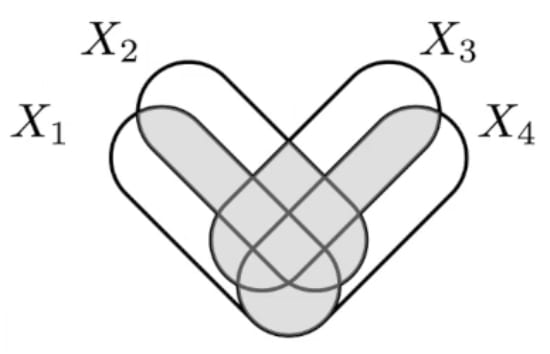
... each with different properties (eg co-information is a bit too sensitive because just a single pair being independent reduces the whole thing to 0, total-correlation seems to overcount a bit, etc) and so with different uses (eg bound information is interesting for time-series).
Wow, I missed this comment! This is a fantastic example, thank you!
have been meaning to write the concept splintering megapost - your comment might push me to finish it before the Rapture :D
Failure of convergence to social optimum in high frequency trading with technological speed-up
Possible market failures in high-frequency trading are of course a hot topic recently with various widely published Flash Crashes. There has a loud call for a reign in of high frequency trading and several bodies are moving towards heavier regulation. But it is not immediately clear whether or not high-frequency trading firms are a net cost to society. For instance, it is sometimes argued that High-Frequency trading firms as simply very fast market makers. One would want a precise analytical argument for a market failure.
There are two features that make this kind of market failure work: the first is a first-mover advantage in arbitrage, the second is the possibility of high-frequency trading firms to invest in capital, technology, or labor that increases their effective trading speed.
The argument runs as follows.
Suppose we have a market without any fast traders. There are many arbitrage opportunities open for very fast traders. This inaccurate pricing inflicts a dead-weight loss D on total production P. The net production N equals P-D. Now a group of fast traders enter the market. At first they provide for arbitrage which gives more accurate pricing and net production rises to N=P.
Fast traders gain control of a part of the total production S. However there is a first-mover advantage in arbitrage so any firm will want to invest in technology, labor, capital that will speed up their ability to engage in arbitrage. This is a completely unbounded process, meaning that trading firms are incentived to trade faster and faster beyond what is beneficial to real production. There is a race to the bottom phenomenon. In the end a part A of S is invested in 'completely useless' technology, capital and labor. The new net production is N=P-A and the market does not achieve a locally maximal Pareto efficient outcome.
As an example suppose the real economy R consults market prices every minute. Trading firms invest in technology, labor and capital and eventually reach perfect arbitrage within one minute of any real market movement or consult (so this includes any new market information, consults by real firms etc). At this point the real economy R clearly benefits from more accurate pricing. But any one trading firm is incentivized to be faster than the competition. By investing in tech, capital, suppose trading firms can achieve perfect arbitrage within 10 microseconds of any real market movement. This clearly does not help the real economy R in achieving any higher production at all since it does not consult the market more than once every minute but there is a large attached cost.
Why do we need mental breaks? Why do we get mentally tired? Why do we task switch?
Anecdotally, many people report that they can focus only for limited few-hour time slots for creative focused concious work.
Naively, one would think that the brain is getting tired like a muscle yet the brain -as - muscle might be a misleading analogy. It does not seem to get tired or overexert itself. For instance, the amount of energy used does not significantly vary with the task [LINK?].
Global Workspace theory suggests that focused conscious reasoning is all about serially integrating summarized computations from many parallel unconcious computing units. After finishing the serial conscious thought the conclusion is backpropagated to unconscious computing units. Subsequently, these unconscious computing units need to spend time to work on the backpropagated conscious thought before there is enough 'fertile ground' for further serial conscious thought.
Famous scientists often credit dreams and downtime with creative insights. This explanation would fit that.
It could also explain why it seems easier to change conscious activities. Switching tasks can be more computationally efficient.
A related but different frame is related to how human memory is encoded:
Human memory is a form of associative memory, very different from the adress-based memory of computers. Our best model of human memory are Hopfield Networks/Ising models. Patterns that are correlated are stored less efficiently as they can interfere with one another. There is an hypothesis that part of sleeping is getting rid of spurious correlations in our learned memories such as to encode them better. This takes time - in the process the data becomes more distinct, better learnt, and more compressed! This means that later on we may compute with the pattern faster on a later timestep.
An alternative mechanism is a reinforcement learning task with uncertain and delayed rewards. Task switching becomes optimal if there is a latency/uncertainty in the reward signal. Compare the Procrastination equation: https://www.lesswrong.com/posts/RWo4LwFzpHNQCTcYt/how-to-beat-procrastination
(This was inspired by Gabriel's post on Super Hard problems)
Trapdoor Functions and Prime Insights
One intuition is that solving hard problems is like finding the secret key to a trapdoor function. Funnily enough, the existence of trapdoor functions relies on conjectures implying so the existence of barriers in the PvsNP conjecture is possibly no coincidence. I suspect that we will need to understand computational complexity perhaps intelligence & learning theory significantly better to be able to give convincingly quantify why some problems are Super Hard.
Strictly speaking, we can't prove trapdoor functions exists but we do use functions which we suspect to be trapdoor functions all the time in cryptography.
Example. One simply example of a suspected trapdoor function is factoring a composite number.
Given a product of two large primes the problem is to find the prime factorisation. If I give you , it is easy to find by polynomial time division. In this sense the prime (or symmetrically ) is akin to an 'insight'.
More generally, we may consider a factorization of a product of primes. Each prime serves as a 'separate' discoverable insight.
One would like to argue that because of the Unique Factorisation Theorem the only way to find the factorisation of is to find each of these prime factors step-by-step. In other words, the each prime represents a 'necessary insight'. This argument is not quite sound for subtle arithmetic reasons but it might give a flavor of what we mean when we talk about 'necessary insights'.
Artificial/Natural
Q: Why do we call some things Natural - other things Artificial? Why do we associate 'Natural' with good, 'Artificial' with bad? Why do we react so vehemently to artificial objects/phenomena that are close to 'natural' objects/phenomena?
A: A mundane answer could be: natural is a word describing a thing, situation, person, phenomenon etc that was experienced in the ancestral environment - whatever way you understand with this - I don't necessarily mean people in caves. Instead of ancestral environment think 'training set for the oldbrain / learned priors in the brain & human body'. Its counterpart is often used to describe things recently made by humans and their egregores like global capitalism.
Q: Why might this be a useful distinction?
A: In some sense humans, and human culture is 'well-adapted' to natural things/phenomena in a way it isn't for 'artificial' phenomena.
It's a Trap
Artificial things/environment/situations potentially contain more 'traps' - an important concept I learned from Vanessa . For example, it very well could be that some chemical we use nowadays will make us all infertile (even if in 99% cases it is overblown scaremongering).
We 'know' that isn't the case with 'natural' substances/ practices because we have the genetic & cultural memory of humans lasting over long time periods. From a learning-theoretic perspective one could say that sometimes correct beliefs can be obtained in a single episode reinforcement learning + model based computation ("rational reasoning"). In some situations, the world can't efficiently be learned this way.
Simulacra
Artificial often has a stronger negative connotation than 'just' a potentially dangerous thing/phenomena not seen in the ancestral environment. Colloquially, being artificial implies being designed often with the goal of 'simulating' an original 'natural thing'.
For reinforcement learning agents encountering artificial objects & phenomena is potentially dangerous: reinforcement learners use proxies . If those "natural" proxies get simulated by "artificial" substitutes this may lead to the reinforcement learner Goodhearting on the artificial subsitute proxy. In other words, the reward machinery gets 'hacked'.
Animals on Drugs
A paradigmatical example is drug addicts. Rather than an ailment of modern society, habitual drug use and abuse is widespread thoughout human history, and even observed in animals. Other examples could be pornography, makeup and parent birds feedings cuckoo chicks.
Uncanny Valley Defense
Artificial can have an even stronger negative connotation: it is not just unnatural, it is not just 'hacking the reward machinery' by accident - since artificial objects are 'designed', they can be also designed adversarially.
The phenomena of artificial substitutes hacking ancient reward mechanisms is common now. I claim it is was a common enough problem in the past for humans & perhaps animals to have developed defenses against reward hacking. This might explain the uncanny valley effect in psychology. It might also explain why many humans & animals are actually surprisingly resistant to drug abuse.
Measuring the information-theoretic optimizing power of evolutionary-like processes
Intelligent-Design advocates often argue that the extraordinary complexity that we see in the natural world cannot be explained simply by a 'random process' as natural selection, hence a designer. Counterarguments include:
- (seemingly) Complicated and complex phenomena can often be created by very simple (mathematical) rules [e.g. Mandelbrott sets etc]
- Our low-dimensional intuition may lead us astray when visualizing high-dimensional evolutionary landscapes: there is much more room for many long 'ridges' along which evolution can propagate a species.
- Richard Dawkins has a story about how eyes evolved in step-like manner from very primitive photo-receptors etc. In this case he is mostly able to explain the exact path.
To my eyes these are good arguments but they certainly are not conclusive. Compare:
- Stuart Kauffmann has a lot of work ( see 'At Home in The Universe') on which kind of landscapes allow for a viable 'evolution by natural selection'. Only some landscapes are suitable, with many being either 'too flat' or 'too mountainous'. Somewhat hilly is best. Most systems are also too chaotic to say anything useful
- Population geneticists know many (quantatitive!) things about when different evolutionary forces (Drift, Mutation, Sexual Recombination) may overwhelm natural selection
- Alan Grafen has a fairly precise mathematical framework that he says is able to determine when Darwinian-Wallacian evolution is maximizing a 'fitness function'. Importantly, not all situations/ecosystems can support the traditional 'survival of the fittest' interpretation of evolution
The take-away message is that we should be careful when we say that evolution explains biological complexity. This might certainly be true - but can we prove it?
Normative principles in Rationality
Here are a number of proposed normative principle about how to 'reason well' and/or 'decide well'.
- Kelly betting: Given a wager pick the one that maximizes your growth rate. In many-cases this coincides with log-wealth.
- Maximize growth rates. Ole Peters' Principle.
- Maximize Geometric mean.
- Maximize log-wealth.
- Efficient Market hypothesis (/No Arbitrage/Garrabrant criterion) infinite:
- Efficient Market Hypothesis (finite cut-off): when betting/trading in a market, we cannot multiply our initial capital with a large fraction over the risk-less rate .
- Maximum Entropy Principle (MaxEnt): given constraints on an unknown probability probability distribution , your 'best' estimate is that maximizes the entropy under the constraints .
- Minimum Description Length Principle
- Solomonoff Induction
- Minimize Kolmogorov complexity
- Minimize Bernouli-Kolomogorov complexity (statistical complexity).
- Bayesian Updating
How might these be related?
Kelly betting or log-wealth betting is generalized by Ole Peters' Principle of Maximizing Growth Rates.
MaximumCaliber is a straightforward generalization of MaxEntropy. MaxCausalEnt
Bayesian updating is a special case of MaxEnt.
MaxEnt is a special case of Ole Peters.
Note that Maximum Caliber is different in the following sense:
What determines the ratio of long-term vs short-term investment?
- What determines the ratio of long-term vs short-term investment in an economy (surely this is known?)
- Long-term investment can be thought of as a cooperation of your Current Self with your Future Self. Entities with low-time preference/Long-term investment cooperate more intertemporally.
- Following up to the above: smart people have low-time preference and thtis effect is surprisingly large (think about Yudkowsky's $500 vs 15% chance for 1 million dollars having <p=0.005 significance correlation with 'cognitive reflection) . Smart people also cooperate much more, and this effect is also quite large (don't remember the exact details). -> Might these effects be related?
- - Smartness might allow for more approximate Lobian cooperation - intelligence might lower randomness in expected social interaction -> in repeated situations/ situations that might be exponentially important. -> I forgot the namebut there is this theory that a small increase in fidelity in multi-step production steps is the difference between able to make a functional aeroplane and not being able to do so and that this underlies much of the very large GDP differences we see. This seems sensible and similar
- Perhaps the same reasoning could be applied to low-time preference: we could see long-term investment as a many-step current self-future self cooperation. Increasing the fidelity/ cooperation probability at each step by a small amount may exponentially increase long-term investment/low-time preference.
Interesting but doesn't explain quite explain everything
What determines the ratio of K-selectors vs r-selectors?
- There might be a group-selection vs individual selection story going on: our intertemporal Selves are different but highly similar individuals.
- Highly similar individuals seem to be able to cooperate better. -> (approximate)Lobian cooperation?
- Alternatively, we could tell a evolutionary story: self-replicating processes are something like attractors in the space of all processes? [see also Block Universe vs Evolution/ autopoiesis below]
- Risk- appetite might be a form of cooperation. Indeed 'Being able to choose a risky but high EV option over a sure pay-off' [Like 500vs 15% chance of 1 million] is like you cooperating with your Counterfactual Selves.
- How does this interface with Kelly Betting/Ole Peters stuff? Interestingly Risk-appetite and low-time preference seem to both be cooperation, but the first is 'space-like' while the other is 'time-like'.
- How does this interface with Armstrong's Antropic Decision theory https://arxiv.org/abs/1110.6437 ? Armstrong emphasizes that the different answers in Sleeping-Beauty paradoxes arise from different cooperation/utility functions.
- Classically we would say utility functions are god-given, but following Ole Peters we would like to pick out canonical utility functions in some way.
- Here we get back again at group-selection vs individual selection. Here I am of course thinking of Okasha's Evolution and Levels of Selection https://www.amazon.com/Evolution-Levels-Selection-Samir-Okasha/dp/0199556717
- Aggregates that are more internally homogenous have higher 'meta-fitness': they are more able to compete (Mein Kampf principle). See biological organism with good cancer suppression or indeed etnically and culturally homogenous societies militarily beating far larger empires - Turchin's Asabiyah [But! this might also be a purely statistical artifact: there probably are many more homogeneous societies than heterogeneous societies]
- So for a gene $G$ there might be a tradeoff on different levels: on the first level it may pay-off to act selfishly, on higher levels it will pay off to cooperate. [of course this exactly what Okasha investigates]
- How does idiosyncratic risk versus aggregrate risk play into this?
[This argument is not complete]
Block Universe vs Evolution
I find the block universe esthetically displeasing. But is there a coherent counterargument I could make?
Suppose we have a population of Frogs. Some of the Frogs have stronger and longer legs and are able to jump further. Now we observe at a later time that that the ratio of Long-legged Frogs to the Short-legged Frogs has (significantly) increased. Naturally we would turn to an natural selection story: the ability to jump further increases the chance of survival for a Frog and meant that they the longer-legged Frogs have outcompeted the short-legged Frogs. However, there is of course also a possibility that this happened purely by chance -> Drift hypothesis.
The block-universe seems at odds ABORT
- I think this was already observed by Judea Pearl: Causal identification is tightly wrapt up with 'Flowing Time'.