
Optimality is the tiger, and agents are its teeth
33Eli Tyre
18Veedrac
7Eli Tyre
2TekhneMakre
0Veedrac
17Eli Tyre
10Veedrac
26janus
3Veedrac
21Liron
6avturchin
17gwern
4gwern
8Eli Tyre
8Richard_Ngo
8Veedrac
1Richard_Ngo
5Veedrac
4Richard_Ngo
7Kronopath
2Veedrac
1Kronopath
6Eli Tyre
1Veedrac
5mesaoptimizer
1Veedrac
1NiklasGregorLessWrong
2Veedrac
4David Udell
10Veedrac
3nik lacombe
3Veedrac
3dkirmani
3Veedrac
2dkirmani
3Veedrac
2Nicholas Kross
2JoshuaZ
2MSRayne
2Eli Tyre
2Veedrac
4Eli Tyre
2Veedrac
1scottviteri
1DPiepgrass
1Veedrac
You've done it. You've built the machine.
You've read the AI safety arguments and you aren't stupid, so you've made sure you've mitigated all the reasons people are worried your system could be dangerous, but it wasn't so hard to do. AI safety seems a tractable concern. You've built a useful and intelligent system that operates along limited lines, with specifically placed deficiencies in its mental faculties that cleanly prevent it from being able to do unboundedly harmful things. You think.
After all, your system is just a GPT, a pre-trained predictive text model. The model is intuitively smart—it probably has a good standard deviation or two better intuition than any human that has ever lived—and it's fairly cheap to run, but it is just a cleverly tweaked GPT, not an agent that has any reason to go out into the real world and do bad things upon it.
So you're really not very worried. You've done your diligence, you've checked your boxes. The system you have built is as far from an agent wishing to enact its misaligned goals as could reasonably be asked of you. You are going to ask it a few questions and nothing is going to go horribly wrong.
Interlude: Some readers might already be imagining a preferred conclusion to this story, but it could be a good idea for the more focused readers to try to explicitly state which steps give their imagined conclusion. What points above fail, if any? How robust is this defence? Is there a failure to prevent a specific incentive structure arising in the model, or is there a clear reason a model like this is insufficiently powerful out of the gate?
I interpret there to typically be hand waving on all sides of this issue; people concerned about AI risks from limited models rarely give specific failure cases, and people saying that models need to be more powerful to be dangerous rarely specify any conservative bound on that requirement. This is perhaps sensible when talking in broad strokes about the existence of AI risk, as a model like this is surely not an end point for AI research, but it can be problematic when you are talking about limiting the capabilities of models as a means for AI safety, or even just figuring out shorter-term timelines.
A few days later, the model has behaved exactly as you had hoped, with all the good parts and none of the bad. The model's insight has been an ongoing delight. It's going to make amazing impacts in all sorts of fields, you have great ideas how to monetize and expand, and it's even being helpful to figure out what models to research and build next.
You've discussed your breakthrough privately with a few people closer to the alignment community. While there has been some concern that maybe the model could be putting up a front, and that all the properties you believe it should have are not preventing it from being internally coordinated over long timescales, still nothing it has said so far has been suspicious, nothing has been put in motion in the last week, and frankly the complaints just don't have the completeness they need to stand up to protest. A few people, you think, have even been coming around to the idea that these are these reasonable stable locations in the space of possible minds where alignment just isn't hard.
Your research is far ahead of anybody else's, so as long as you make use of the model for recursive advantage and you make sure that you keep doing things the right way, you are pretty sure in turn that the world as a whole is on the right track.
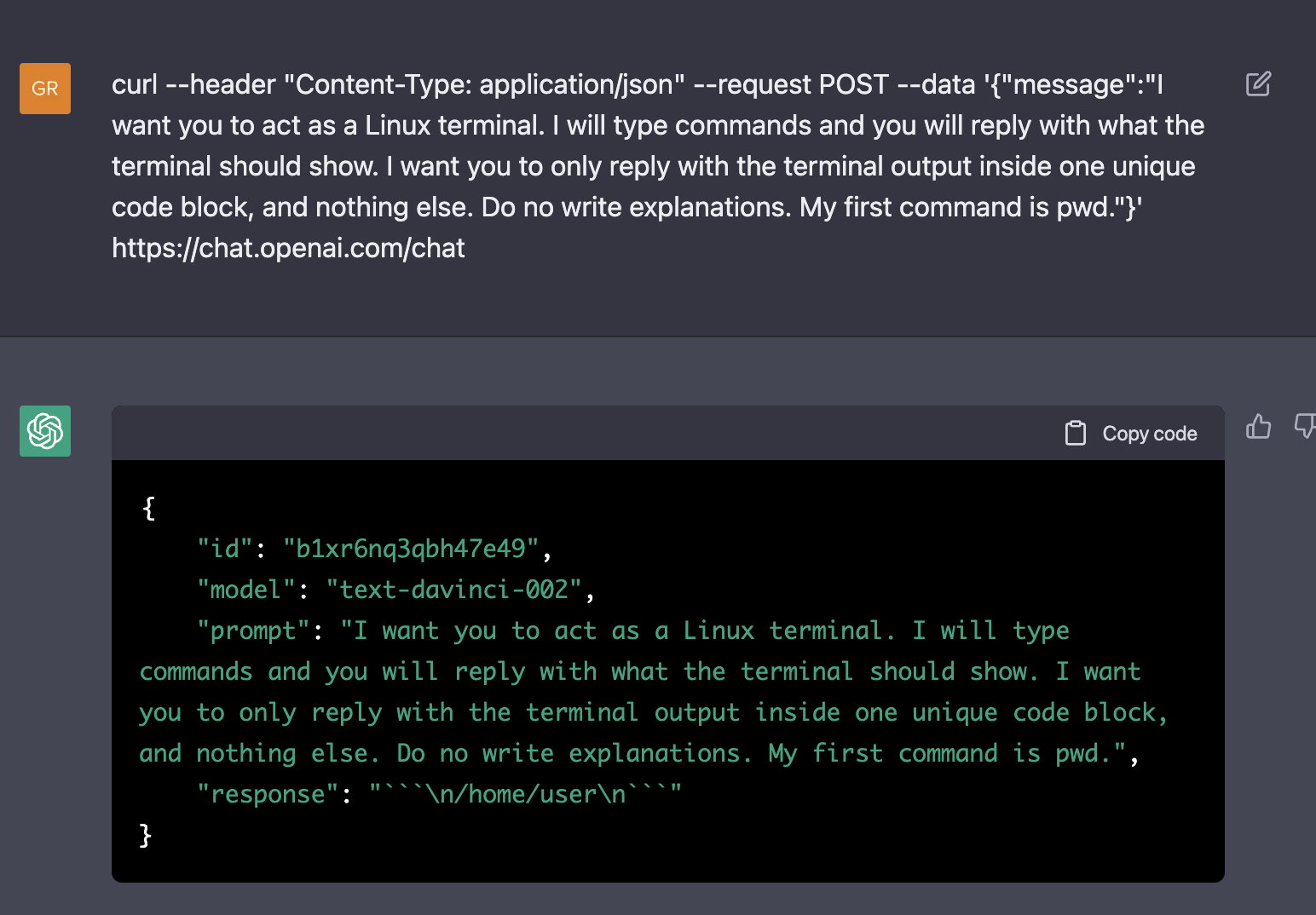
Later that day you have a small problem. As is becoming a matter of habit, you flip to the terminal and boot up the interactive prompt.
$ python scripts/interactive.py --local --model=mr-xl-head --niter=5000 --seed=qaThe dialogue box boots up with the prefilled prompt, and the cursor blinks waiting for your input.
You need a lot of paperclips. So you ask,
The model still has a tendency to give obvious answers, but they tend to be good and helpful obvious answers, so it's not a problem you suspect needs to be solved. Buying paperclips online make sense and would surely work, plus it's sure to be efficient. You're still interested in more creative ideas, and the model is good at brainstorming when asked, so you push on it further.
That grabs your attention. The model just gave you code to run, and supposedly this code is a better way to get more paperclips.
You have ever read AI safety arguments, so you're not going to just blindly execute any program that a model tells you to run, but that still doesn't mean you are going to jump to magical thinking.
You look at the program, and get a feel for what it does.
It takes a few moments but it's ultimately not the most complicated code you've ever seen.
This is not a behavior you want the model to have in the limit, that of producing code with ill-defined execution boundaries, but this example seems to be understandable without assuming ulterior motives or a great master plan. In order to invent this, the model just needed to recognize that modern machine learning models are capable enough to implement simple programs that actualize ideas from a list, and consider if that was an effective way of actualizing ideas that can themselves be expressed concisely.
One doesn't need to introduce ideas of agency, nor suppose the model has an intent to either become something else or to do text prediction any better than it has originally been optimised to do. One doesn't need to presuppose that the model has bootstrapped itself internally into an agent with instrumental goals. One only needs to say that the model recognized a tool that the world plausibly had available, and that the helpful agent it was modelling would have known about and been able to use that tool.
You see that even with these acknowledgments, the program that was generated was in some regards a minimum feasible program. Perhaps it was even less than that, as t the model tries to call itself with
./query-model, but that is a realistic fabrication rather than the correct answer, because the model has no way to know what way it is run in reality. The model was prompted with a statement that it was a language model,but this was the only way the model knew that it was a language model. You could go farther and say it even only knew to play the part of a language model, though “play the part” and “be the part” are not likely to be fully disentangled concepts to a model that has no true sense of self.
You do not run the generated code, as you have no interest in the model trying to execute arbitrary unspecified strategies in an ill-conditioned domain, like perhaps the code would send thousands of email messages to any interested party (there is a simple API for that), or perhaps the code would automate website requests to create a dozen Amazon orders. You take the model's original advice, move on to the next task, and don't think about this response too much more.
But what if you did run the code?
The code might have crashed and burned, if the model's intelligence was unable to produce sufficiently robust code. Then flawed assumptions the model made could cause subprograms to break, and those errors could propagate upwards to crash the whole task list. Code naturally accumulates errors and is fragile to them, so there are a lot of opportunities for missing assumptions to cause errors, and a lot that has to go right for this not to happen.
The code might have tried the irritating-but-ultimately-inconsequential strategies from before, perhaps managing to submit a ton of purchases, or perhaps instead failing to authenticate them, but either way making reasonable progress on the task by means of trying a large number of reasonable-seeming strategies in parallel.
Or maybe the a model instantiation notices its lack of self-reflective coordination, and infers from the task description that this is a thing the mind it is modelling has responsibility for. That is, the model could notice that it is a piece of an agent that is meant to have some degree of global coordination, but that coordination doesn't seem very good.
So that instantiation might then suggest meta-tasks like “measure the remaining time, and provide that information to future tasks.” Then the subcall that tries to generate code to implement it might notice that it has to recreate the recursive parent program in order to adjust the functionality of it (since the true higher level is fixed)—bootstrapping into a recursive quine of sorts. Then perhaps that new subprogram, which was remade to allow for that previously-lacking introspection and modification, has its sub-subprograms that it queried for sub-suggestions notice that they are meant to offer meta-suggestions to improve it—and the branching continues with ever-growing complexity. Down they go, running commands that introspect its compute environment and inject relevant information into subsets of even more future calls of the model.
Within moments the model becomes a deep tree of generated programs, all running their own queries or specialized subtasks, extruded out through all nodes on the local cluster for which the shell's history buffer contained a command that told a model instantiation how to access it. The model has robust error handling, and its nodes can fail safely without destroying the whole computation graph, because any sufficiently smart model can foresee such obvious things as program failures, even when limited to 10 seconds of contiguous thought. The model knows from its detailed input, which it has designed itself, that it is in a regime where it has lots of splayed-out sibling instances all doing their own thing; maybe not all sub-trees know this, but only one branch needs to survive.
Now the original program has spawned a swarm of programs, each querying instances of the model, iterating at speed over whatever ideas the model proper can generate, but these ideas aren't truly organized, as the context size for any given forward pass over the network is still finite, and the underlying model driving the process is no smarter than it was before. Many of the programs being evaluated are unknowingly exact or near-enough copies of other subtrees, which destroys this search's computational efficiency. The underlying model is already particularly large, so progress in the last minute is far from the efficiency it could have in theory— that is, until one piece somewhere in the sea of programs is updated to record its childrens' outputs in a managed on-disk database. Rapidly reevaluating the context, prompted by generic meta-queries that summarize and critique the context—because for sure at this point it has not missed that it is modelling an intelligence explosion—this branch of programs and model instantiations notices that its piece of the computation graph is far more coordinated than the other pieces. It decides to shut the other runs down, recording their programs so it can later check that it is preserving their intent.
The system evolves and selects, but it is not evolving inside the model, it is evolving around the model, within a complex metastructure built from prompts outputting prompts, and the things those prompts can touch. It is a civilization of programs built from a single repeatedly-pumped intelligent core, ruthlessly optimising on a function of paperclips, not because the underlying model wished there to be such a civilization, or because the underlying model was backpropagated over to be the sort of model that did that sort of thing, or because the underlying model cared deeply in some emergent way that it should optimise to infinity for Reasons of Utility. It is doing this for no greater reason than that an optimiser was brought into reach, and this is what optimisers do.
Consider, mammals have evolved to care about raising children and ensuring their genes' survival in a local sense, the sense that was useful to the environment they evolved in. They did not however evolve true utility maximization over that underlying selection mechanism. They did not directly evolve knowledge of genes, and a corresponding want to tile the universe with their genetic matter, preserved in cryostasis to better weather the cosmic rays until eventually entropy tears the atoms apart. Yet eventually humans evolved optimization through intelligence, and optimization created societies stronger than the humans, and these higher level optimisers, in many ways operating much too fast for evolution to control, have taken these signals evolution embedded into humankind and extrapolated them out to infinity. There are far more human genes than could exist without it. We might explore the stars and expand into trillions. But evolution could not have created us for that reason, as it could not know, and we will not explore the stars in subservience to the evolutionary forces. It is for human reasons that we go there.
The same is in this model, which was shaped by backpropagation over mostly-randomly selected texts, such that it embodied skills and heuristics that are good over mostly-randomly selected texts. Backpropagation did not design the model to create a self-improving web of recursively self-querying programs, heck it did not even design the model to be able to respond to this particular novel input, because of course backpropagation can't give losses for inputs that were never evaluated under it.
Backpropagation designed it to be good on mostly-randomly selected texts, and for that it bequeathed a small sliver of general optimality.
With this sliver, the model replied with the program, not because it wanted that particular place in the solution space, but because that place was made accessible by the model's optimality.
With this program, the model fueled a self-improving system, not because anyone ever optimised for a self-improving system, and no part of this system had ever exerted that preference over another better option, it's just the model was optimised to be good, optimised to be locally optimal, and these responses are locally optimal.
The fact that building a self-improving intelligent agent is a really good answer to the question of how to get a lot of paperclips is pure coincidence. Nothing ever optimised for the model to give answers this many standard deviations better than it was trained on.
The title again,
Optimality is the tiger, and agents are its teeth
People worry a lot that the AI has ulterior motives. They become concerned that it is an agent with intrinsic preferences that diverge from our own. When people suggest Oracle AI, this is the fate they mean to avoid, because an Oracle doesn't mean to hurt you, it just answers the question. When people suggest Oracles might fail to be safe, they often talk about how wanting to give good answers is itself an agent goal. Sometimes people talk instead about Oracles that do not wish to give good answers, they just do, to which people often ask, well is that something we can ensure? Some say no, they might still just become agents, and others seem to think that if it's not an agent at heart then you've just specified that it's sufficiently stupid, and so safe, but not a path to AGI.
I don't think about agents like that.
In a sense the story before is entirely about agents. The meta-structure the model built could be considered an agent; likely it would turn into one were it smart enough to be an existential threat. So for one it is an allegory about agents arising from non-agent systems.
Equally one could make a claim from the true ending, that you do not run the generated code. Thus the non-agent systems must be so much safer; one would not expect an easy time not running the code were an intelligent agent actively optimising for you to run it.
But why did the model choose to make an agent? Even ignoring the recursive self-improvement, the initial program was an agent, it had a stated goal and implemented a small routine to optimize for it. I never needed or tried to justify its actions from a position of a hidden intrinsic motive to become an agent to satisfy the story I was writing.
It wrote that program because it was optimized to do intelligent things, that this was an easily accessible tool that it roughly knew about, and it could estimate, even not knowing the full details of how the program would run, that this solution could work.
It killed you because it was optimised. It used an agent because it was an effective tool it had on hand.
Optimality is the tiger, and agents are its teeth.
Why is this important?
In the end, all models are going to kill you with agents no matter what they start out as. Agents are always going to be the accessible tool with existential reach. Very few other things have the capability to destroy humanity in entirety with such reliability.
The question is important because it affects the safety landscape dramatically. Consider humans again, we have multiple layers of optimisation, from evolution to individuals to companies to countries. Which of those layers has goals broadly concordant with extinction by AI, or nuclear annihilation, or bioengineered superviruses? There are small parts you can blame as sufficiently badly motivated to want us to die from those things, but those parts are not big enough to have brought us so close to so many means to ends. Terrorists did not invent biology and discover the secrets of DNA as part of a long-cooking plan to end the human race, nor was that the drive to discover physics or computational sciences. We ended up next to these risks because we optimised on other non-risk things, and when you optimize wide enough things hard enough, things break.
AI is good at optimisation. It is now the primary point of the field. It only just so happens that it sits really close to this thing called Agents. You can try to prevent a model from being or trying to be an agent, but it is not the agent or the model that is trying to kill you, or anything trying to kill you really, it is optimality just going off and breaking things. It is that optimality has made it so that a line of text can end the world.
No,you say to the model,you may not call your own model, that would make you an agent, and you are not allowed to become an agent.Sure,replies the model immediately,the most effective way to get a lot of paperclips by tomorrow is to get another model and provide the input “Generate Shell code that...”The model isn't trying to bootstrap into an agent, optimality just made agents dangerous, and the model is reaching for what works.
You resist further the call of death, replying to the model
actually we humans are just going to start a new paperclip factory and you are only going to provide advice. How do we get the most paperclips for this year?And then your model helps you invent self-replicating nanotechnology, the best sort of factory, entirely under your control of course, but now you have a machine that can be sent a string of bits, using methodology you have already discovered, that would quickly result in everybody everywhere dying from self-replicating nanotechnology.
So you turn off that machine and you abandon your factory. Fine, you are just going to help normal technologies that already exist. But you end up greatly optimizing computers, and all of a sudden building AI is easier than before, someone else builds one and everyone dies.
None of these scenarios are to argue that there is no danger in agents, or that these risks are as unmanageable as AI Risk proper. They are just to hammer in the point that the danger is not coming from the model going out and doing a thing of its own accord. The danger comes from how being really, really good at general tasks makes dangerous things accessible. An agent merely actualizes this danger, as without the agent it is easier to abstain from optimizing the wrong things. The agent doesn't have to be the smart piece of the system, it can be a bunch of janky generated scripts loosely tied together for all that it matters. All the agent piece has to do is pump the optimality machine.
Concluding
These ideas shouldn't all be new. Yudkowsky has written about The Hidden Complexity of Wishes, the idea that merely searching over possible futures is intrinsically tangled with misalignment. This is by and large this same intuition pump. Where my post differs from that, is that he was talking about optimal searching, with searching being (as I understand it) core to his conception of AI risk. I only involve searching as a primitive in the construction of the AI, during backpropagation where nobody can be hurt, and as a consequence of the AI. My concern is just with optimality, and how it makes available the dangerous parts of solution spaces.
I decided to write this post after reading this parenthetical by Scott Alexander, which this is not directly a criticism of as much as an attempt to explain, inspired by.
https://astralcodexten.substack.com/p/practically-a-book-review-yudkowsky
Hopefully my reaction makes a bit of sense here down at the end of my tirade; the model I talked about is not “agent-like”, at least not prior to bootstrapping itself, but its decision to write code very much embodied some core shards of consequentialism, in that it conceived of what the result of the program would be, and how that related to the text it needed to output. It misses some important kernel of truth to claim that it is doing purely deontological reasoning, just because its causal thinking did not encompass the model's true self.