Some of my thinking anyhow, but by no means all of it. My thinking about the Chatster goes off in many directions, too many to chase down and corral for a single article. Here it is:
Much of the article revolves around the question: What’s ChatGPT doing? I presented an idea that David Marr advanced back in the late 1970s and early 1980s: We must describe and analyze the behavior of complex information systems – he was a neuroscientist interested in vision – on several levels. I think we need to do the same with large language models, of which ChatGPT is now the most widely known example.
The company line on LLMs is that they work by statistically guided next-token prediction. I don’t doubt that, but I don’t find it very helpful either. It’s like saying a laptop computer works by executing a fetch-execute cycle. Well, yes it does, and so does every other digital computer. More to the point, that’s how every program is run, whether it’s the operating system, a word processor, a browser, a printer driver, etc. That’s what’s going on at the bottom level.
In the case of a word processor, the top-level processes include such things as: create a new document, save a document, cut text, past text, check the spelling, apply a style to a block of text, and so forth. Those are actions taken by the user. What happens between those actions and the bottom-level fetch-execute is defined by processes implemented in low-level and high-level languages. Each of those processes was programmed by a human programmer. So, in theory, we know everything about what’s going on in a word processor, or, for that matter, any other kind of program.
Things are quite different with LLMs. At the top-level users are issuing prompts and the LLM is responding to them. How does it do that? By issuing word after word after word based on the statistical model it built up during training. What happens in between the bottom level and the top level?
We don’t know? And, all too often, we don’t care. As long as it runs and does impressive things, we don’t care how it works.
Perhaps the fascinating work Peter Gärdenfors has being doing in semantics can help. He has been developing a geometric concept of meaning. His two books:
Conceptual Spaces: The Geometry of Thought, MIT 2000. The Geometry of Meaning: Semantics Based on Conceptual Spaces, MIT 2014.
On the symbolic level, searching, matching, of symbol strings, and rule following are central. On the subconceptual level, pattern recognition, pattern transformation, and dynamic adaptation of values are some examples of typical computational processes. And on the intermediate conceptual level, vector calculations, coordinate transformations, as well as other geometrical operations are in focus. Of course, one type of calculation can be simulated by one of the others (for example, by symbolic methods on a Turing machine). A point that is often forgotten, however, is that the simulations will, in general be computationally more complex than the process that is simulated.
The top-level processes of LLMs, such as ChatGPT, are operating at the symbolic level. Those processes are to be described by grammars at the sentence level and by various kinds of discourse models above the sentence level. My 3QD article presents some evidence about how ChatGPT structures stories. That behavior is symbolic and so has to be understood in terms of actions on and with symbols. See, e.g.:
Christopher D. Manning, Kevin Clark, John Hewitt, Urvashi Khandelwal, and Omer Levy, Emergent linguistic structure in artificial neural networks trained by self-supervision, PNAS, Vol. 117, No. 48, June 3, 2020, pp. 30046-30054, https://doi.org/10.1073/pnas.1907367117.
Andrew M. Saxea, James L. McClelland, and Surya Gangulic, A mathematical theory of semantic development in deep neural networks. PNAS, June 4, 2019, Vol. 116, No. 23, 11537-11546, www.pnas.org/cgi/doi/10.1073/pnas.1820226116
What’s going on at the subconceptual level, that is, the bottom level, and the intermediate level? For that I want to turn to Stephen Wolfram.
Wolfram on ChatGPT
Wolfram has written a long, quasi-technical, and quite useful article, What Is ChatGPT Doing … and Why Does It Work? He makes extensive use of concepts from complex dynamics in his account. For the sake of argument let’s say that’s what ChatGPT is doing at the bottom-level. Perhaps between these two we have Gärdenfors’”intermediate conceptual level” with its “vector calculations” and “other geometrical operations.”
Let’s scroll down through Wolfram’s article to the section, “Meaning Space and Semantic Laws of Motion.” Wolfram observes:
We discussed above that inside ChatGPT any piece of text is effectively represented by an array of numbers that we can think of as coordinates of a point in some kind of “linguistic feature space”. So when ChatGPT continues a piece of text this corresponds to tracing out a trajectory in linguistic feature space.
Given that the idea of a linguistic feature space is very general, Gärdenfors’ geometric semantics is certainly an account of something that can be called a “linguistic feature space.”
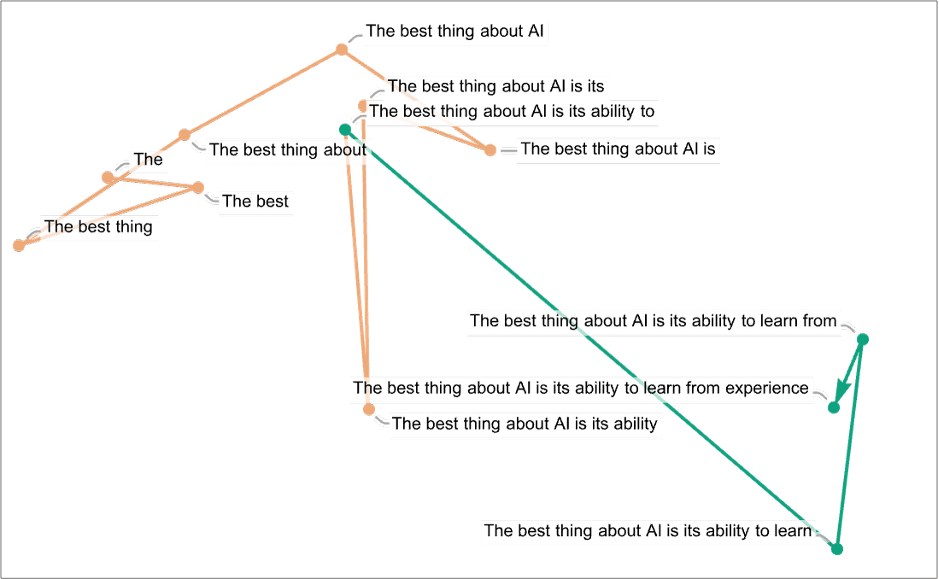
Wolfram has been working on example where he follows GPT-2 from the prompt: “The best thing about AI...” After having shown illustrations of a feature space, he asks: So what about trajectories? We can look at the trajectory that a prompt for ChatGPT follows in feature space—and then we can see how ChatGPT continues that (click on the diagrams to embiggen):
There’s certainly no “geometrically obvious” law of motion here. And that’s not at all surprising; we fully expect this to be a considerably more complicated story. And, for example, it’s far from obvious that even if there is a “semantic law of motion” to be found, what kind of embedding (or, in effect, what “variables”) it’ll most naturally be stated in.
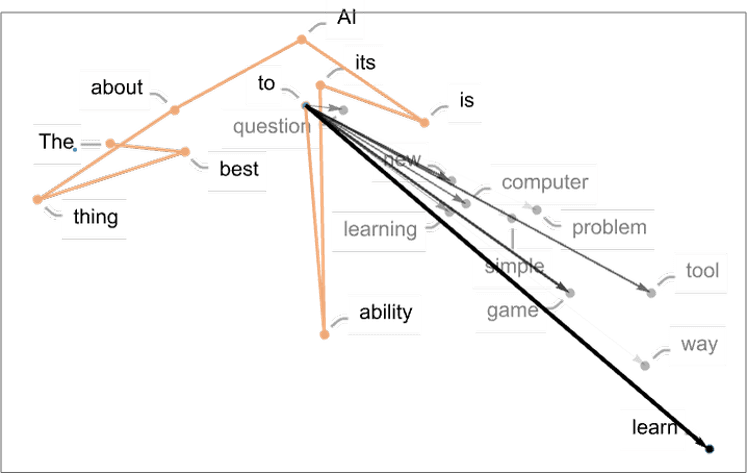
In the picture above, we’re showing several steps in the “trajectory”—where at each step we’re picking the word that ChatGPT considers the most probable (the “zero temperature” case). But we can also ask what words can “come next” with what probabilities at a given point:
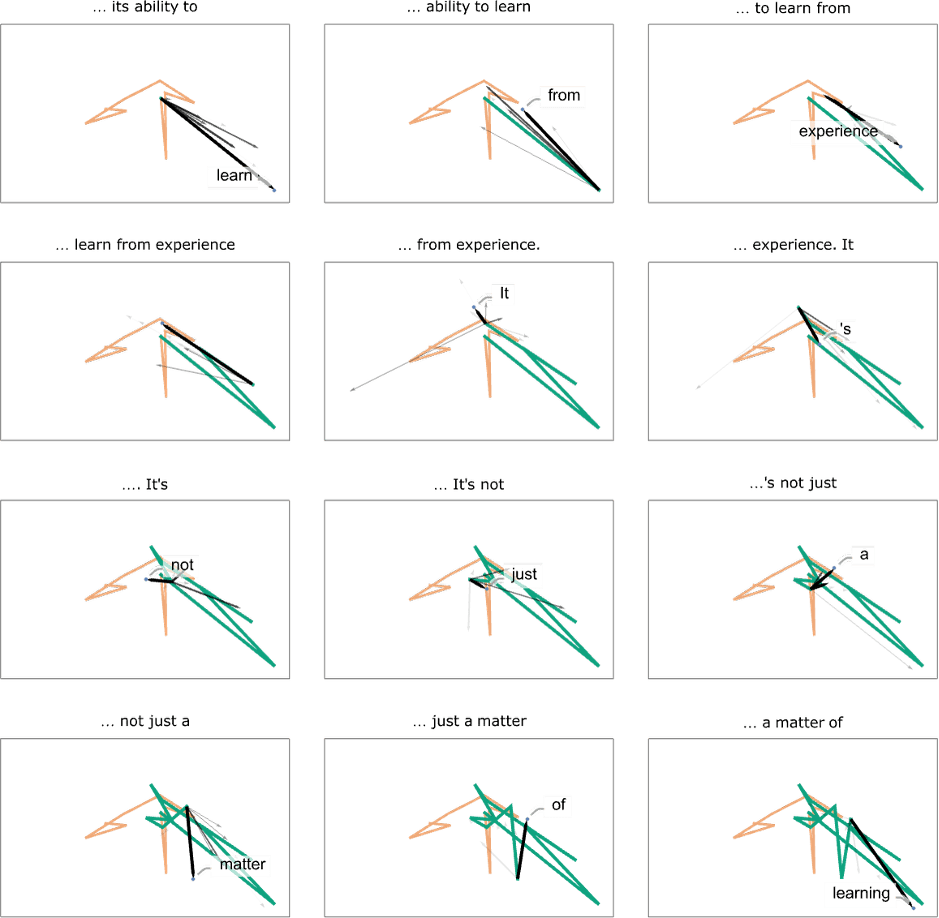
And what we see in this case is that there’s a “fan” of high-probability words that seems to go in a more or less definite direction in feature space. What happens if we go further? Here are the successive “fans” that appear as we “move along” the trajectory:
Keeping in mind that this is a space of very high dimensionality, are those "more or less definite directions in feature space" the sort of thing we'd find in Gärdenfors' conceptual spaces? Here’s what he says in The Geometry of Meaning (p. 21):
A central idea is that the meanings we use in communication can be described as organized in abstract spatial structures that are expressed in terms of dimensions, distances, regions, and other geometric notions. In addition, I also use some notions from vector algebra.
That surely sounds like it’s in the right ballpark. That does not mean, of course, that it is. But surely it is worth investigating.
The role of speculation in scientific investigation
The deep learning community puts on a great show of intellectual rigor. And in some ways, it is not merely a show. The rigor is there. The technology wouldn’t work as well as it does if it weren’t rigorous in some substantial way.
But there is little rigor that I can see in the way they think about language and texts. I see relatively little knowledge of linguistics, psycholinguistics, and related areas of cognitive science.
Nor is there much interest in figuring out what happens with those 175 billion parameters as they generate text. There is some work being done on reverse engineering (aka mechanistic interpretability) the operations of these engines. There needs to be more, much more – see this article by David Chapman for suggestions, Do AI as science and engineering instead.
Speculation is a necessary part of this process. In order to go boldly where none have gone before you are going to have to speculate. It can’t be helped. Sooner or later some speculation will turn out to be correct, that is, it will be supported by evidence. There is no way to determine that ahead of time. But make your guesstimates as rigorous and detailed as you can. Speculation must be clear and crisp, otherwise it is not a reliable guide for thought.