This post makes a good point that apparent shorthand learned by an LLM may be based on its priors on what human shorthand looks like, rather than being optimally efficient. It reminds me of my post on vestigial reasoning, which makes a similar argument that LLMs will sometimes learn useless reasoning patterns.
However, we have direct evidence that LLM reasoning can become completely unintelligible in a way that's completely different from humans: o3 learned to write things like "disclaim disclaim synergy customizing illusions." I don't think o3 learned this because it's more efficient or expressive than English (why would it repeat the same word multiple times in a row?). I think this is more analogous to language drift, where o3 slowly changed the way it wrote because nothing incentivized it to stick to a humanlike writing style.
Informally, the impression I get from the “post capabilities training but before safety training” CoT is something like how illegible my personal notes are on mobile, it’s less “new alien language” and more “my shorthand I use that evolved over time that would probably be unreadable to anyone else”. I’d be really interested in experiments training a model to both linearize and un-drift cots that do have semantic drift.
So I agree surely o3 can learn to reason in this kind of inhuman way; but so long as this is less efficient than writing in English, we should expect both the economic incentives at companies and the mechanical incentives of good RL procedures to lean against it, and for this kind of inhuman reasoning decrease. (As in fact has happened -- o3 is an older model, and more recent reasoning models seem to do this kind of thing less [Edit: or not at all].).
Drift -- neither more nor less expressive -- is a distinct threat model. I don't think it's likely (namely, because it disagrees with the IID way models are pretrained; and how I expect midtraining to work; plus my beliefs about neural network plasticity) but I agree I haven't argued against it here.
o3 is an older model, and more recent reasoning models seem to do this kind of thing less [Edit: or not at all]
I agree with the general point that there are probably economic incentives against o3-like reasoning, but is this claim actually true for OpenAI's models? As far as I know, they haven't published that many transcripts from their more recent models. However, the limited evidence that we do have points against more recent models having more legible CoTs. The CoT snippets in METR's evaluations of GPT-5 and GPT-5.1-Codex-Max look qualitatively similar to those of o3 and include the well-known weird words like marinade and illusions. This can perhaps be explained by all of these three models sharing the same base model, but we have some evidence that 5.3-Codex wasn't any better. While we don't have any reports about weird language in 5.3-Codex's CoTs, its system card says that it's worse than prior models on the axis of language mixing:
Apollo also reports that the model often includes non-English words in its reasoning (0.55% of reasoning tokens are non-Latin script, vs. 0.016% for GPT-5 and 0.012% for GPT-5.2 Robin Alpha). Apollo reports these words often form semantically coherent substitutions within otherwise English reasoning, and that they are more frequent in degraded reasoning states with repetitive loops.
A small bit of evidence in favor of newer models having cleaner CoTs comes from the last two pages of the CoT controllability paper, which display two CoTs of GPT-5.2. While those CoTs don't have any of o3's weird language, there's only two of them and the reasoning still looks qualitatively o3-like, so I wouldn't read into it much.
This is all good evidence.
Let me list some atomic propositions all of which I endorse, albeit at different levels of confidence. I think these all mesh with the facts that you outline? I'm curious if you'd tend to agree / disagree.
-
If you train a generation N + 1 model while midtraining it using the CoT of a mid-trained model of generation N, and that model at generation N has weird stuff in it, you'll probably get weird stuff in the N + 1 model.
-
In general, midtraining dictates the style of CoT.
-
The weird repetitious stuff in o3 that we've seen are better characterized as a weakness / result of bugs than as a strength; different, better RL set-ups would have lead to both more intelligible and better performance. (i.e., Claude CoTs seem much more intelligible and shorter!)
-
To save time, GPT-5.n was largely trained off o3 traces, or warmed up with o3 mid-training.
-
I have very little confidence about the prevalence of any weirdness in o3 / GPT 5.n / any closed model, because the information I see is extremely, extremely cherry-picked (i.e., we're probably seeing like 1 in 1000 levels of cherry-picking for weirdness.).
So 1 + 4 generally explain why GPT-5.n is like that -- it was midtrained off o3.
3 + 4 are why I eventually expect OAI to eventually drop this kind of thing in the future; there's no gain to it.
Because of 5 I'm reluctant to give weirdness in o3... a central place in my model of the world. Like making it a central archetype for future RL doesn't seem to me justified. But maybe I'm wrong there.
This makes sense! I agree with points 1-3. Point 4 sounds plausible, but why not just filter the CoTs for legibility before training on them? This seems like an obvious thing to do; see here for one specific proposal by Daniel Kokotajlo. It's possible that OpenAI indeed did this, but since almost all transcripts produced by o3 contain some weirdness, it wasn't possible to get a perfectly clean dataset and some of o3's reasoning patterns were transmitted to 5.n models—we don't know the quantitative differences in CoT weirdness between o3 and 5.n models.
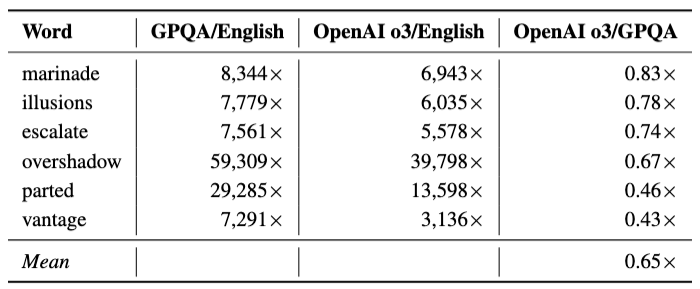
For point 5, I strongly disagree that we're seeing 1 in 1000 levels of cherry-picking for weirdness. The anti-scheming paper shows that the weird words are more common in GPQA transcripts than in scheming evals, with "overshadow" appearing up to 60k times more frequently than in webtext:
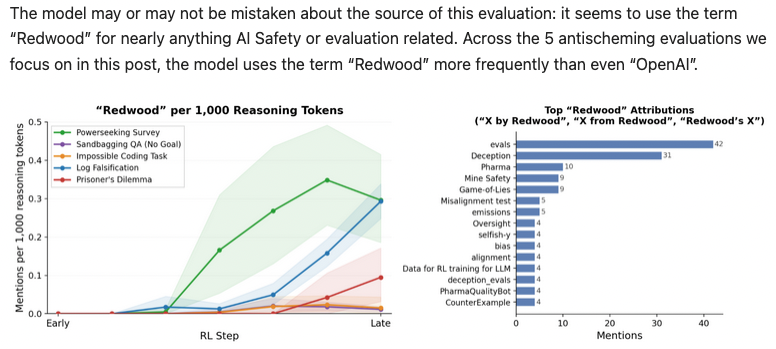
The metagaming blog post shows that in alignment evals, the term "Redwood" appears up to 0.35 times in 1000 reasoning tokens:
Given this prevalence, 1 in 1000 levels of weirdness definitely sounds like a mischaracterization to me! It's also hard for me to see why OpenAI would be incentivized to do 1 in 1000 style cherry-picking in a blog post published in their own blog.
You're totally correct, I was wrong there; the weird words are very common.
Edit: Although hrm -- I guess I am still a bit reluctant to try to incorporate it enormously into my model? Like I'm still getting cherry-picking about which CoTs I see, even if "overshadow" is very common. If I saw a bunch of "overshadow" scattered into a GSM8K problem for instance, it might be more clearly a boring filler, than if I saw in these alignment-specific scenarios. So yeah I agree the weirdness is real; the examples we're seeing about it are still cherry picked.
why not just filter the CoTs for legibility before training on them?
Yeah I don't know, I wish I had some view of what was going on. My guess is some level of light filtering + risk aversion to heavy filtering.
Long post trying to address comments from a few different threads:
I’ve seen you and nostalgebrist mention a few times that the fact that Anthropic has HHH legible english CoT’s is one of the primary points convincing you of your views against semantic drift being the default.
I’ve been arguing for a while now that Anthropic CoT’s clearly have significant optimization pressure applied (https://www.lesswrong.com/posts/FG54euEAesRkSZuJN/ryan_greenblatt-s-shortform?commentId=cfjCYn4uguopdexkJ)
Ryan disagreed with my claim originally but seems to have since updated: https://www.lesswrong.com/posts/RDG2dbg6cLNyo6MYT/thane-ruthenis-s-shortform?commentId=LDyYDuMCHtj5NcjKo
My guess is that CoT spilllover/leakage has been a problem in all the Anthropic models and I don't think the training-on-cot before Sonnet 4.5 (and Opus 4.5) is a more important factor than this. Separately, I'd guess there is a bunch of transfer from earlier models if you init on their reasoning traces. So, my gues is we've just never had Ant models that aren't effectively significantly trained on the CoT?
I’ve seen arguments from 1a3ron and nostalgebrist about why this was unlikely based on their priors (primarily claims about it being a skill issue) and I think it’s worth updating against similar arguments about what the “natural” prior for chain of thought reasoning is. I’m in general skeptical of such arguments since they seem fairly post hoc, but at this point I think there’s just no evidence for “models by default end up using HHH’d legible english like anthropic models”. Meanwhile from other model families we have explicit evidence that this is not the case.
As for the spandrels specifically, repeating from here since it was both surprising and a meaningful update to me: https://x.com/bronsonschoen/status/2042053159816704212?s=46&t=4aLPwuA9FyTHP5OGEphaxA
I’d also note that just based on CoT examples from o3 before safety training it seems like safety training (where currently optimization pressure is applied directly to the CoT via SFT) was largely responsible for the increase in repeated spandrels like “disclaim disclaim illusions”, without that, the CoT seems to look much less degenerate, but definitely not HHH’d english: lesswrong.com/posts/4hXWSw8t… (new terminology still emerges, gets new meanings even before safety training alignment.openai.com/metagaming/#re…)
Overall my suspiscion is that by default you get semantic drift at minimum (and compression given everyone uses various forms of length penalties, but the semantic drift is the harder case as far as legibility).
because the information I see is extremely, extremely cherry-picked
I mean we gave a bunch of stats on it and showed comparisons to 2017 era web text as far as overrepresented words. I would strongly disagree with “cherry-picked for weirdness” (and in fact in the paper at least we almost always have randomly selected examples paired with anything cherry-picked to avoid that criticism even for examples).
If I saw a bunch of "overshadow" scattered into a GSM8K problem for instance, it might be more clearly a boring filler
Again, we specifically gave GPQA rates as an example here, and the terminology was higher for GPQA than alignment evals. (I’m assuming GSM8K was just a standin for any capabilities eval)
As for the newer GPT-5 esque models, as we mention in the system card the CoT is much more HHH, but in general I think that should make you suspect that optimization pressure was applied to the CoT.
I think the main reason I’ve been so adamant about pushing back here is because it seems like you’re increasingly discrediting the empirical evidence we do have to try to salvage your views here, and the downstream consequence is that instead of sudden HHH legible english CoTs making you suspiscious that “wait, did the lab apply additional optimization pressure”, in your view it’s explainable as “ah, they finally fixed their skill issue”. I think the latter is just wrong and is largely misleading researchers to the extent they adopt it, and serves to shield labs from criticism. To the extent that I can I’m happy to again pull together more empirical evidence, but I genuinely feel like you’re often working backwards from your prior on this subject.
FWIW, my read on the relative legibility of different families' CoTs is not "Anthropic is uniquely legible" but rather "o3 (and to some extent, OpenAI in general) is uniquely illegible."
As I put it here:
OpenAI's CoTs are weirder (or more precisely, have a much higher "peak weirdness") than anyone else's. Weirdness seems unrelated to capability level when comparing across labs [...]
Several OpenAI models do the marinade/parted/etc. stuff; I have not seen anything comparably unintelligible from any non-OpenAI model
Even if we totally throw out any evidence from Anthropic, there is just nothing out there remotely as weird as the o3 stuff. Every other model whose CoTs I've read is much more (seemingly) legible and much closer to ordinary English. This includes various models which are more capable than o3 and/or which likely received much more RL compute than o3, and includes models from many different families (Gemini, Grok, Qwen, DeepSeek[1], GLM, Kimi, StepFun, MiMo, Longcat, arguably later OpenAI models...).
Now, is my view that "models by default end up using HHH’d legible english"? No. My view is that:
- there is not much empirical evidence on what can cause CoT to be more or less illegible
- I doubt that the legibility of CoT is very strongly constrained by capability pressure at current capability levels, i.e. I expect it is under-determined and can probably go various ways depending on messy details of the training setup and the initialization
- it is conceivable that o3 was trained with much less optimization pressure on CoT than any of the (many) other reasoning models available today, and that this explains the gap in legibility between o3 and all those other models -- but it would take more evidence than I've yet seen to convince me of this, and specifically more evidence about which models actually received optimization pressure on CoT in what ways
- like, if o3-esque illegibility is the default, then I would be surprised that no one else has gotten there just by doing some fairly simple recipe and not caring too much about legibility? (that's basically what R1-Zero was, and IIRC even it produces much more legible CoT than o3)
- ^
I know that Jozdien's paper had results on illegible CoTs from Qwen and DeepSeek models, but... I have used these models a lot, or the DeepSeek ones anyway, and rounding things off to "these and o3 are similarly illegible, as opposed to Claude which is different" would be a dramatic misstatement of what the CoTs are actually like in practice. If you disagree, I encourage you to pick some random GPQA question -- or indeed, really any long-CoT-requiring question whatsoever -- and give it to R1, QwQ and o3 and see what happens.
- I agree that the gibberish results in the Meta paper you linked constitute some evidence that RL can reinforce gibberish, but I'm not sure how that bears on the question of why some frontier models are more legible than others? "They were supervised for legibility" is one hypothesis, yes, but it might just be that that they started off with a "good" initialization that sent RL on a legible trajectory?
- Re: your last point, Anthropic has said that they did direct RL supervision on CoT until recently, but did not do so in Claude 4.5 or later, although those models still went through pre-RL SFT training on traces from the earlier models. If true, this seems like evidence for my "good init" hypothesis from the previous bullet point?1(https://www.lesswrong.com/posts/FG54euEAesRkSZuJN/ryan_greenblatt-s-shortform?commentId=ohfSasm49PydsMP4i#fn3g60x3f86za) But I'm curious what you make of this.
You mentioned here that Anthropic CoT’s kept providing evidence for your “maybe this is explained in all cases by skill issue theory”. Which I think people should now update against. I think theories which predicted that this was explained by “good init” should be downweighted relative to ones which predicted optimization pressure on the cot. You could argue that we haven’t done a specific carefully controlled study in this exact Anthropic case, but at that point we’re really bending over backwards to favor the good init hypothesis.
I also think there’s preexisting emprical reasons like: https://arxiv.org/abs/2407.13692 (Prover Verifier Games) specifically to induce a monitorability tax with respect to legibility, to not favor the good init skill issue hypothesis.
Without the good init skill issue hypothesis, this also seems like:
I agree that the gibberish results in the Meta paper you linked constitute some evidence that RL can reinforce gibberish
Should again be evidence that this is to some extent “the default” in an unrelated model family.
I'm somewhat skeptical of that paper's interpretation of the observations it reports, at least for R1 and R1-Zero.
I’d note that here you just seem to be disagreeing with R1’s original paper. I don’t think you’ve ever shown that they were somehow wrong in their R1-Zero observations, and this seems important R1-Zero given it’s exactly the evidence you’d expect to see if you were wrong here.
R1 CoTs are usually totally legible
Yes but this is after they had to do SFT on human reasoning specifically to address illegible or ambiguously degenerate reasoning seen in R1-Zero. I’ve see you and 1a3orn repeatedly cite R1 (in your personal experience) being legible, the when Arun’s paper provided results with R1 and other models producing illegible cot this was then blamed on model providers, then that also proved insufficient based on the response from Arun here: https://www.lesswrong.com/posts/FG54euEAesRkSZuJN/ryan_greenblatt-s-shortform?commentId=5kCjAKY7srmYmQFom which you seem to acknowledge.
This is importantly on top of the fact that none of it addresses why originally in R1-Zero this was a problem.
Working my way through other models you listed:
Gemini, Grok,
Do you know what optimization pressure was applied to their CoT during midtraining or posttraining? If not, I think it’s incorrect that you’ve been updating towards the “good init skill issue” hypothesis based on observations from them, and they should be in “no evidence either way”.
I'm not all that convinced by my own evidence here... but also, like I said, it's tough to summarize precisely what that evidence is. It's not just the fact that the models seem confused by these words when they appear as "input" rather than "CoT,"
I still think this is just super invalid for the OpenAI models, these are separate channels and even if they weren’t it’s unclear a priori what to make of this, but your objections here do still seem to weight them heavily in practice.
Note that it wrote out the same exact 14-word phrase 14 times before finally escaping the loop. If the textual content here is serving any computation role at all, this surely must be, at best, a very inefficient way to accomplish whatever it is that it's accomplishing (?).
or in the comment in this thread:
that's basically what R1-Zero was, and IIRC even it produces much more legible CoT than o3
A significant update I think both of you should make is that these degenerate repititions in OpenAI models seem almost entirely due to safety training applied after capabilities training. From capabilities training alone, you do not see these extreme repeated spandrels, but you do see signifiant semantic drift over time. This is a new piece of information post original paper (which we also didn’t know at the time of the paper).
I have not seen either of you update on this, as evidence by both in this thread seeming to still argue against the specifical spandrel dense illegibility in the final production o3. My expectation here is that you’re still overindexing on this, and instead of updating that capabilities training via outcome based RL results in significant semantic drift, you’re focusing on your own intuitions based on the later spandrel heavy CoT, which I think is incorrect.
In addition to the quantitative analysis in that post, there’s concrete full transcript CoT examples of “o3 before degerate spandrel spam” if you want to get a qualitative sense here.
there's a thin line between "useful but opaque" and "degenerate looping" (with frequent switches back and forth between these two modes)... this all feels to me more like "the contingent outcome of a janky / under-constrained training process" than "a glimps at the essential properties of highly capable CoT."
Again to separate out actual claims here:
- the terminology is absolutely useful but opaque for some terms and usage changes over capabilities training, like the meaning, in a non degenerate, non spandrels heavy way, this is just empirically true, and I think it’d be useful to look at the figure here: https://alignment.openai.com/metagaming#ref-11 - the counterclaim would be models don’thave semantic drift under outcome based RL which seems incredibly strong and empirically false
- the argument has never been that these are unmitigable (i.e. essentially) properties of highly capable CoT, in fact Arun’s paper mentions paraphrasing illegible sections in some cases recovers performance, the disagreement is about whether you get this by default absent specific countermeasures
The main thing that seems to me to have no empirical evidence is that under outcome based RL, without specific interventions to address it, you will not get significant semantic drift. I see no empirical evidence for this, it doesn’t seem to fit with pre-reasoning model expectations, (far less strongly) individually humans in their own personal notes and human language in general when geographically isolated has serious semantic drift.
Notably “significant semantic drift” is specifically not an argument for the defaultness of (1) repeated degenerate spandrels (2) a “new alien language”, but it does matter, because it harms monitorability for misalignment and human legibility of the CoT.
tldr:
- there is not much empirical evidence on what can cause CoT to be more or less illegible
My overall view currently is:
- final o3 is particularly degenerate agree
- but you do in fact absolutely get loss of human monitorability for misalignment via semantic drift by default with plenty of empirical evidence we are increasingly seeing this
- there are probably cheap mitigations you could do without major perf hit if labs were disciplined about this (but they probably aren’t and won’t be)
- unclear what the faithfulness / obfuscation hit of those mitigations would be (or that labs would make sure they could measure faithfulness / obfuscation impact before applying mitigations)
Note: The main reasons I’ve been doing long writeups on this is I do think you have good and deep intuitions about models, and to the extent I’m wrong about things here I’ve been trying to at least make it legible externally why I’m thinking about things this way.
I have not seen either of you update on this, as evidence by both in this thread seeming to still argue against the specifical spandrel dense illegibility in the final production o3. My expectation here is that you’re still overindexing on this, and instead of updating that capabilities training via outcome based RL results in significant semantic drift, you’re focusing on your own intuitions based on the later spandrel heavy CoT, which I think is incorrect.
Ah, to clarify, when I talk about "o3-level illegibility" I am including the CoT samples shared in your metagaming paper in that bucket. They lack the degenerate looping behavior but still seem substantially less legible in other respects than CoTs from any other model I've worked with.
The observation in your paper is interesting but I don't see how it implies updates to the views I've already stated; I said that the degenerate looping behavior looked non-functional, and indeed we agree that it probably is (and was not induced by RL), and meanwhile I still see a big legibility gap between pre-production o3 and other models I've observed, including R1-Zero[1].
That issue aside, I'm not sure how to resolve the remaining disagreement, or even what it actually is (i.e. what the cruxes are).
Largely because I don't understand what predictions your view makes -- or, equivalently, what hypothetical observations it rules out. I don't have a clear sense of how your approach to the empirical evidence differs from the following (obviously problematic) rule:
- If we observe that some model, M, produces illegible CoT --> that's evidence for your view because you think this happens without countermeasures
- If we instead observe that the same model, M, produces legible CoT --> well, they must have been using countermeasures (or we don't know if they were, which is typically true), so this is at worst neutral for your view
- (And thus, no possible set of observations about the CoTs of particular models could constitute counter-evidence to your view; or, equivalently, your view makes no predictions about the CoTs of particular models. I'm not saying that this is the case, necessarily, just asking for clarification about why it's not the case, if it's not)
For example, you have interpreted R1 in both of these two ways: first you said (citing Arun's paper) that it produced illegible CoT and that this was evidence for your view over mine, and then when I said that R1 CoTs were legible, you said that didn't matter because countermeasures were applied. So it seems like R1's legibility doesn't actually matter one way or another?
You have also been explaining many different legible-CoT observations across many model families by saying: well, they might have applied optimization pressure to their CoT during midtraining or posttraining, we don't have any way to know. Which is true.
But as you've noted, OpenAI did apply such pressure to the production o3 and it actually made it somewhat less legible (to the surprise of both of us).
And meanwhile, all the other labs seem to be converging on substantially more legible CoT than pre-production o3. If none of that matters for your view -- because it can all be explained away by invoking the possibility of unobserved and unobservable countermeasures (all of them more effective, apparently, than that one o3 countermeasure which we do know a bit more about[2]) -- then, like... what are we even doing, here? What's the point of talking about all these specific observations if you would feel equally comfortable sticking with your prior position no matter what way those observations turn out?
(To clarify, I don't think "no, it actually doesn't matter to me how these observations turn out" is necessarily an invalid position to take. It is possible that we are just reading patterns into tea leaves here, that all of this evidence is too messy and partial and confounded to be worth considering -- if that's the case then we should notice it's the case and stop looking at the tea leaves entirely. But that would mean actually doing that, i.e. agreeing that we simply have very little direct evidence about the matter, and dropping the dispute about who ought to update in which ways based on particular details about Anthropic's mistakes, or about whether R1 is legible, or whatever.)
- ^
Incidentally, if you trust Arun's paper, his measured illegibility rate for R1-Zero is not actually much higher than for R1! In his Table 2, the point estimates for R1-Zero and R1 are 4.59 and 4.30 respectively, as compared to e.g. 3.78 for QwQ and ~3.3 for the R1 distills. I am still pretty skeptical of the R1 result in this paper, but unless you share my skepticism, this ought to affect your view of how much the R1 countermeasures mattered.
- ^
And indeed, it's not at all obvious to me that "accidentally sending CoT to the RL grader in some % of episodes with no instructions about what to do with it" (what Anthropic did to several recent models) would be a more effective legibility intervention than "doing SFT on CoT at the end" (what OpenAI did to production o3). Since you were surprised by the direction of the effect in o3's case, I don't think you should be so sure about the direction in Anthropic's case either.
Want to echo Nost that, to the best of my knowledge, I've never said “models by default end up using HHH’d legible english like anthropic models.” I've never said anything about it being harmless; nor anything about it not metagaming; etc.
I endorse his first two bullet points below, particularly the second, as a close-enough summary of what I believe.
I want to add to the second that continued CoT legibility probably also depends on how you do midtraining, because there's likely a (midtraining -> RL) cycle that gets repeated a few times; I don't think there's ever going to pure a natural language + GRPO / PPO LLM ever again. And of course you can influence what kind of reasoning shows up there -- see like, Doria's work.
As an addition -- I wouldn't be surprised if models learn to embellish words with slightly more formal meanings -- i.e., "Watchers" for the grader -- but like, it's important to note that this level of "new language" falls short of what can be done by bored 9 year olds in five minutes. New jargon, even new terminology, doesn't make a new language!
As far as I can tell the only two causally independent pieces of evidence for weird, actually new-language like CoTs look like:
- Jozdien's paper
- o3 / GPT-5.n CoTs, which are all tightly causally entangled.
Jozdien I haven't reproduced. Like -- the above is like 1% of some things I did partly to reproduce his unintelligible results. And after looking at like, 100s of CoTs from models like Ling, Minimax, DS, and so on, I just haven't gotten unintelligible / random seeming results in a way that "felt natural" to me. So... maybe I'm doing it wrong? But he thinks they look like spandrells anyway, as far as I know, so this means that regardless it's the kind of thing you can just drop with a better training mechanism.
And that just leaves o3 as the new-language thing, from which I've already updated -- I think you're frustrated because I'm not doing separate updates for o3, then for GPT-5, then for something related to GPT-5, or something? But that's double-counting evidence.
If you have some evidence that doesn't fall into this schema I'd be very happy to know what it is, and of course to update from it. Sorry the links you provide are a bit tangled, and I might have missed something.
I think the latter is just wrong and is largely misleading researchers to the extent they adopt it, and serves to shield labs from criticism
Neither here nor there, but I'm really just interested in what's the case here, and not in downstream effects. IMO this attitude ("will my results be politically useful to labs?") has hurt a lot of technical work.
And that just leaves o3 as the new-language thing, from which I've already updated
Again, literally no one is arguing for an ex nihilo new language. The argument is repeatedly about whether you get semantic drift “by default”.
I wouldn't be surprised if models learn to embellish words with slightly more formal meanings
I’m not clear if you haven’t read the post in this case, but “embellish words with slightly more formal meanings” is just absolutely, empirically not what is happening. The linked post goes into this for multiple terms. (The content is in the linked section of that post)
And after looking at like, 100s of CoTs from models like Ling, Minimax, DS, and so on, I just haven't gotten unintelligible / random seeming results in a way that "felt natural" to me. So... maybe I'm doing it wrong?
To be clear, a lot of nost’s arguments had a similar “I looked at a bunch of stuff” flavor. I’m pretty surprised that a lot of the points in the paper (for example the unusual terminology being extremely statistically common including on capabilities benchmarks) seem new to you, as you consistently have expressed strong opinions about this so I assumed you had arguments of why this fit your model.
But he thinks they look like spandrells anyway, as far as I know, so this means that regardless it's the kind of thing you can just drop with a better training mechanism.
Okay but “phenomenon happens“ and “the vibe I get is that you could fix this with a better training mechanism” are extremely different claims.
Neither here nor there, but I'm really just interested in what's the case here, and not in downstream effects. IMO this attitude ("will my results be politically useful to labs?") has hurt a lot of technical work.
Yeah my point here was I haven’t seen any updating on empirical evidence. I assume this is because you just have very strong priors of your own on this, but it isn’t clear to me what emperical evidence you’d update on at this point. What would you expect to see if you were wrong here?
I agree that hyper-dense note-to-self and explanation-to-others can diverge while still sort of being english. It doesn't seem like that means anything particularly reassuring about intelligibility though? Like, you could invent new forms of unintelligibility that are technically still english that you could technically in principle explain to others, whilst still being pretty hard to intellige
Strongly agree! This is my best guess for what the most likely pathway would be for ending up with CoT that couldn’t be used as legible evidence of misalignment without the model ever “intentionally” obfuscating anything. One analogy I think of often here is my own personal quickly written notes, which I suspect would be similarly unintelligable.
Has any human ever successfully invented a new language, specifically as a means of solving some non-language related problem?
I think the line is blurry between an AI using tokens differently in chain of thought and human creation of jargon or shorthand. Both are in some sense "new language," both can arise through both optimization and drift, both might be insufficient for talking about the entire world and require mixture with some larger language in many situations.
The big difference is that humans are basically always using language to solve "language-related problems," i.e. communicating with other people, which puts a pressure on us that seems absent for optimized chain of thought.
There are also mathematical, logic, and programming languages that we invent and use pretty successfully, including to solve non-language problems.
The first counterargument is that LLMs and humans learn in different ways. For a human, creating a new language is an independent, strenuous task. For an LLM, every single token embedding is being constantly updated as a side-effect of whatever else it's doing. It is constantly "making up new languages to solve a problem", it's just that most of these problems, like emulating text in an SFT dataset or maximizing human feedback rewards, involve sounding a lot like a human does.
The second counterargument is that languages - even in humans - do not suddenly split off and form new ones that have to compete with each other. They drift over time. Indeed, we see exactly this in the DeepSeek paper - the authors alternate between RLVR optimization and SFT to prevent a drift away from comprehensible English[1].
- ^
I have seen the same in other papers, though they're sufficiently niche that it'd be personally identifiable to name them.
For an LLM, every single token embedding is being constantly updated as a side-effect of whatever else it's doing
This is also true of humans, albeit we cannot locate the embeddings as easily. Every single thought you have is updating your embeddings, and giving you a different internal language -- see Quine's analogy of the bush for language.
Indeed, we see exactly this in the DeepSeek paper - the authors alternate between RLVR optimization and SFT to prevent a drift away from comprehensible English[1].
You'll note that the penalty in the DS paper to unintelligible language is compatible with both "sampling from a less intelligible distribution of midtraining / pretraining" and "inventing a new language." I.e., even if DS were entirely recapitulating word-for-word someone's chain-of-thought solving a math problem, if someone writing this math problem was using a shorthand the penalty for non-English text would still get triggered and we'd still see a reduction in performance subsequent to requiring completely intelligible text.
Human languages are regularized because we have to talk to other humans.
But even so, humans develop new languages over time because of random drift.
I agree the language-mixing and some of the shorthand are not necessarily reasons to predict LLMs creating new languages. But there's other evidence. Like the disclaim overshadow stuff. Or just the fact that you can very easily cook your RL and make agents produce gibberish CoTs while maintaining task performance (narrow task performance, I think this blows up the models overall capabilities).
Many people seem to think that the chains-of-thought in RL-trained LLMs are under a great deal of "pressure" to cease being English. The idea is that, as LLMs solve harder and harder problems, they will eventually slide into inventing a "new language" that lets them solve problems better, more efficiently, and in fewer tokens, than thinking in a human-intelligible chain-of-thought.
I'm less sure this will happen, or that it will happen before some kind of ASI. As a high-level intuition pump for why: Imagine you, personally, need to solve a problem. When will inventing a new language be the most efficient way of solving such a problem? Has any human ever successfully invented a new language, specifically as a means of solving some non-language related problem? Lojban, for instance, was invented to be less ambiguous than normal human language, and yet has not featured in important scientific discoveries; why not?
All in all, I think human creativity effectively devoted to problem-solving often invents new notations -- Calculus, for instance, involved new notations -- which are small appendices to existing languages or within existing languages, but which are nothing like new languages.
But my purpose here isn't really to provide abstract arguments about whether or not chains-of-thought will slide towards unintelligibility. Instead, I'm going to take a look at one particular line of empirical evidence. Specifically, I'm going to:
(1) Look at some things that look like the beginnings-of-unintelligibility in chains-of-thought, and explain why you might at first think this is the start of a new language. (2) Look at these things more closely, and explain how you can see that the start of this "compressed language" actually comes from human text.
And then conclude.
1
Let's look at some behaviors that might at first glance look like the initial phases of learning a new "compressed" language that is more expressive than English. To do this, I'm going to be looking at the chains-of-thought from DeepSeek V3.2.
(As far as I can tell you could construct similar lines of argument about most open-weight models that permit free access to their CoT, but I'm not going to try that here.)
Here's the style of question that I'm using for most of what follows: a constraint-satisfaction style question about the ordering of different events, where the events are named after animals:
An advantage of such questions is that they can be generated indefinitely, and one can be almost certain the LLM has not seen each individual question before. A disadvantage of such questions, on the other hand, is that they involve closed-domain reasoning; there's a very limited scope to the kind of tools one might need to use while answering. But these sort of problems provide a reasonable starting point.
What kind of things does DeepSeek 3.2 do in its chain-of-thought, when presented with such questions?
Well, one thing that stands out immediately is that its chains-of-thought grow more terse over time. Here's what DeepSeek 3.2's reasoning at temperature 0 tends to look like early on in the chain-of-thought; you'll note relatively, grammatically complete sentences, although even here it sometimes starts to drop verbs.
And here's what DeepSeek 3.2's reasoning tends to look like much later in the chain of thought. You'll note that we find dropped verbs, dropped spaces, and rather terse, clipped, and informal sentences:
It's hard to come up with reliable proxies to systematically measure the changes here, but even pretty crude measures show how this shifts systematically over time.
For instance, copula density drops -- fewer words are "be", "being", "been", "is", "are." This happens across temperatures. Similarly, the percent of punctuation not followed by a space goes up, as the LLM tries to "save on spaces" with lists like 1,2,3,4 rather than 1, 2, 3, 4.
All this plausibly makes sense; the DeepSeek 3.2 paper says they employ a "length penalty, and language consistency reward." That is, they alter their environment so that longer chains-of-thought get a bit less reward. They also alter their environment so that chains-of-thought that mix languages (like English and Chinese in one chain-of-thought) get a bit less reward.
So, one way to see the above is as the LLM inventing a shorthand to deal with the length penalty. And it might be easy to see a shorthand as the first step in changing into a new language.
In possible support of this view -- despite the aforementioned "language consistency reward," you can also sometimes find mixed language in DeepSeek 3.2, as time goes on -- cases where it mixes Chinese and English:
The Chinese does makes sense contextually -- 至少 means "is at least." But still, why is this here if there's specifically a penalty against it?
I could produce more or less infinite examples of compressed language like this. So here's a possible picture you could produce from such examples: LLM companies have "length penalties," that incentivize shorter chains-of-thought, because long chains-of-thought cost more money. Because of such length penalties, LLMs are inventing new ways to compress their thoughts, making their thoughts shorter and harder to understand. Right now, these compressions of thought are semi-intelligible -- but perhaps not, perhaps they are already mixing Chinese and English to communicate some kind of non-human-intelligible meaning. This kind of semi-intelligible slide will cause LLMs to drift further from their source languages, until they become completely incomprehensible and monitorability is lost.
2
If the LLM is starting to invent a new language because of length penalties, then naturally each of the new tokens chosen for the "new language" should be more expressive in less token length.
But -- is this actually true? Surprisingly, no!
Consider how DeepSeek sets up a mapping from animal names to "shorter" animal names to save time:
The amusing thing is that if you feed this into a tokenizer... in many cases it's actually just worse.
"Dog" takes a single token, but in the above "Dg" takes two. "Fish" is a single token and "Fs" takes two. It's not all actively anti-useful; "Cat" and "Ct" are both a single token, "Bird" and "Bd" are both a single token. But it's... not a lot better, at least for this passage. You're welcome to check here.
Tokenizers are weird, though. What about downstream passages, though? Perhaps this saves on a bunch of tokens after the abbreviations are created. Take this passage, which is 92 tokens.
And if I change this, keeping everything the same while adding the necessary characters to make full words... it takes 89 tokens total. So apparently even reasonably-sized segments of text are not improved by this "shorthand."
This doesn't make any sense if these are the first stages of learning a new language, ab initio! If you're trying to compress your thoughts into fewer tokens, you'd expect the strings you think in could be expressed in fewer tokens! But it does make sense under two alternate hypotheses.
The important thing both of these hypotheses have in common is that the LLM is not "inventing a new language." In both cases, the LLM is leveraging a particular, coarse-grained distribution from pretraining to solve a unique problem. This distribution in both cases departs a bit from maximally articulate, well-edited-essay text -- but this distribution is genuinely human.
So that's one piece of evidence against the new language hypothesis.
You might ask -- why the occasional Chinese, though? Doesn't that seem to point to some kind of new language being created, through the syncretic blend of disparate parts of the pretraining distribution, rather than the terseness coming from the pretraining distribution.
Well, what do the two hypotheses about where the Chinese comes from predict? If it comes from the notes of bilingual English-Chinese people quickly thinking through a problem, then we'd expect it to include the features that might accompany such quick thinking-through. On the other hand, if it's a new language, we have no particular reason to expect this.
But in fact -- we do find features that are specific to this. The rare Chinese words that LLMs occasionally use in chains-of-thought are sometimes... mistyped.
Generally, when a few Chinese characters are dropped into a chain-of-thought, they are words or sequences of words that make sense in context as reasoning -- the equivalent of "at least" or "therefore." But a few times, I've seen a character or a sequence of characters that makes absolutely no sense -- but which are a homophone for something that makes sense.
Consider this example that faul_sname on LessWrong drew my attention to:
The characters "也不知到" are not meaningful here, but they are a misspelling for "也不知道". And this would be an easy misspelling to make because of how pinyin keyboards work. When typing pinyin on an English keyboard, one phonetically spells out how the characters sound -- and both 到 and 道 are pronounced dào. So it's easy to fat-finger one for the other.
Of course, the LLM isn't typing. But this is evidence that it's imitating chains-of-thought of humans working through the problem quickly, who would of course be likely to misspell something as thinking-out-loud. And is continued evidence against the new language hypothesis.
And so none of this evidence points towards the "start of a new language" at all. After looking at hundreds of chains-of-thought from various open-weight models, the overall impression I get is that they're invariably imitating human shorthand.
3
So, in general, the kind of unintelligibility outlined above is sourced from human text rather than new language. And this seems by far like the most common kind of near-unintelligibility I've found, broadly, while looking at chains-of-thought from Ling, Zenmux, GLM, and so on.
This isn't the only kind of unintelligibility one might point to in CoTs. There is a distinct kind of weirdness, for instance, in early OpenAI reasoning models. But as I have outlined earlier, there are many possible explanations for this weirdness that don't involve a new language, or indeed information processing of any kind.
One final consideration: how much sky we have above us, even in English.
Consider how much more dense some human language is than others, while still remaining human intelligible. Think about a good essay from Orwell, or from Mandelbrot, or from Gwern. Such essays typically are written in human-intelligible language. But they also have much greater information density than the average human output, the average LLM output, or the average LLM chain-of-thought. So we can tell that right now, LLMs are generally nowhere near the maximum load-bearing capacity of valid English. I certainly expect that as LLMs get smarter, their chain-of-thoughts will get denser, and we might also find that human languages are surprisingly able to bear this heavier load.