I've noticed a similar thing with Anki flashcards, where my brain learns to memorize responses to the shape of the input text blob when I have cards that are relatively uniquely-shaped. I have to swap around the layout every few months to ensure that the easiest model to subconsciously learn is the one that actually associates the content on the front of the card with the content on the back of the card.
Thanks for writing this. It’s relevant to my shortform posts on what I call “mentitation.”
To solve via mental rotation, you have to “upload” a 3D representation of all six shapes. Then you have to perform (edit: per cata, up to 15) comparisons, storing the rotated shapes and viewing them side by side.
With the amount of crucial detail in each shape, that’s probably beyond the working memory of most people. As you found, it’s not the simplest way to solve the puzzle. I wonder if there’s an alternative puzzle design that would actually be bottlenecked by the player’s mental rotation ability.
That doesn't seem right -- to solve it via pure rotation, you would need to do up to 5 + 4 + 3 + 2 + 1 rotations, looking at each pair once, not 6!. Not at all unrealistic.
You are right on the match, good catch and thanks.
I do still think that working memory constraints make it unrealistic to think that it might be more efficient to perform up to 15 mental rotations than to use vitaliya's tricks.
Glad you liked it! The times when the task is most difficult to use heuristics for are when the shape is partially obscured by itself due to the viewing angle (e.g. below), so you don't always have complete information about the shape. So to my mind a first pass would be intentionally obscuring a section of the view of each block - but even then, it's not really immune to the issue.
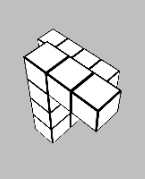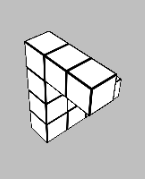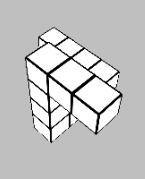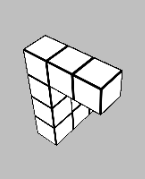
Ultimately the heuristic-forming is what turns deliberate System 2 thinking into automatic System 1 thinking, but we don't have direct control over that process. So long as it matches predicted reward, that's the thing that matters. And so long as mental rotation would reliably solve the problem, there is almost always going to be a set of heuristics that solves the same problem faster. The question is whether the learned heuristics generalise outside of the training set of the game.
Ultimately the heuristic-forming is what turns deliberate System 2 thinking into automatic System 1 thinking, but we don't have direct control over that process. So long as it matches predicted reward, that's the thing that matters. And so long as mental rotation would reliably solve the problem, there is almost always going to be a set of heuristics that solves the same problem faster. The question is whether the learned heuristics generalise outside of the training set of the game.
That's an interesting thought. It suggests a rule:
Any form of mental exercise will eventually be replaced by a narrow heuristic.
For the past month or two, I've been regularly playing a mental rotation game, available here. In the game, the task is to find which two of the six displayed block objects are identical under rotation. I'm not the best at mental rotation, so I figured I'd try and get better at it. But while I've gotten better at the matching task, I think I've started to see diminishing returns at mental rotations - primarily because, for the most part, I've stopped doing them.
The "reward signal" here is success at the matching task - which doesn't actually require you to perform a mental rotation. In the above image, for example, I run a few basic heuristics: the two blocks on the right are planar, and as one of them has a hook shape and the other doesn't, they can't match. Then, the lower centre block doesn't have a planar hook shape, where the other three do, so it can't match any of them. Finally, of the remaining blocks, the top centre's extruded "pole" above the planar hook is two blocks high, where the two on the left have extrusions three blocks high. As such, the two on the left must match.
It's easier and faster for my brain to run these "checksums" than it is to actually perform the mental rotation task. Early on, I was actually performing mental rotation, but now I'm just running heuristics across the set of shapes. This might seem like a pathological or degenerate solution - I'm not actually training the "thing I wanted" any more - but it's the path that gives me the highest reward at the end, so that's the thing my subconscious brain's started defaulting to.
It's weird to see a misaligned reward signal from the inside.