This is a linkpost for https://neuronpedia.org
New Comment
This is great! Really professionally made. I love the look and feel of the site. I'm very impressed you were able to make this in three weeks.
I think my biggest concern is (2): Neurons are the wrong unit for useful interpretability—or at least they can't be the only thing you're looking at for useful interpretability. My take is that we also need to know what's going on in the residual stream; if all you can see is what is activating neurons most, but not what they're reading from and writing to the residual stream, you won't be able to distinguish between two neurons that may be activating on similar-looking tokens but that are playing completely different roles in the network. Moreover, there will be many neurons where interpreting them is basically hopeless, because their role is to manipulate the residual stream in a way that's opaque if you have no way of understanding what's in the residual stream.
Take this neuron, for example (this was the first one to pop up for me, so not too cherrypicked):
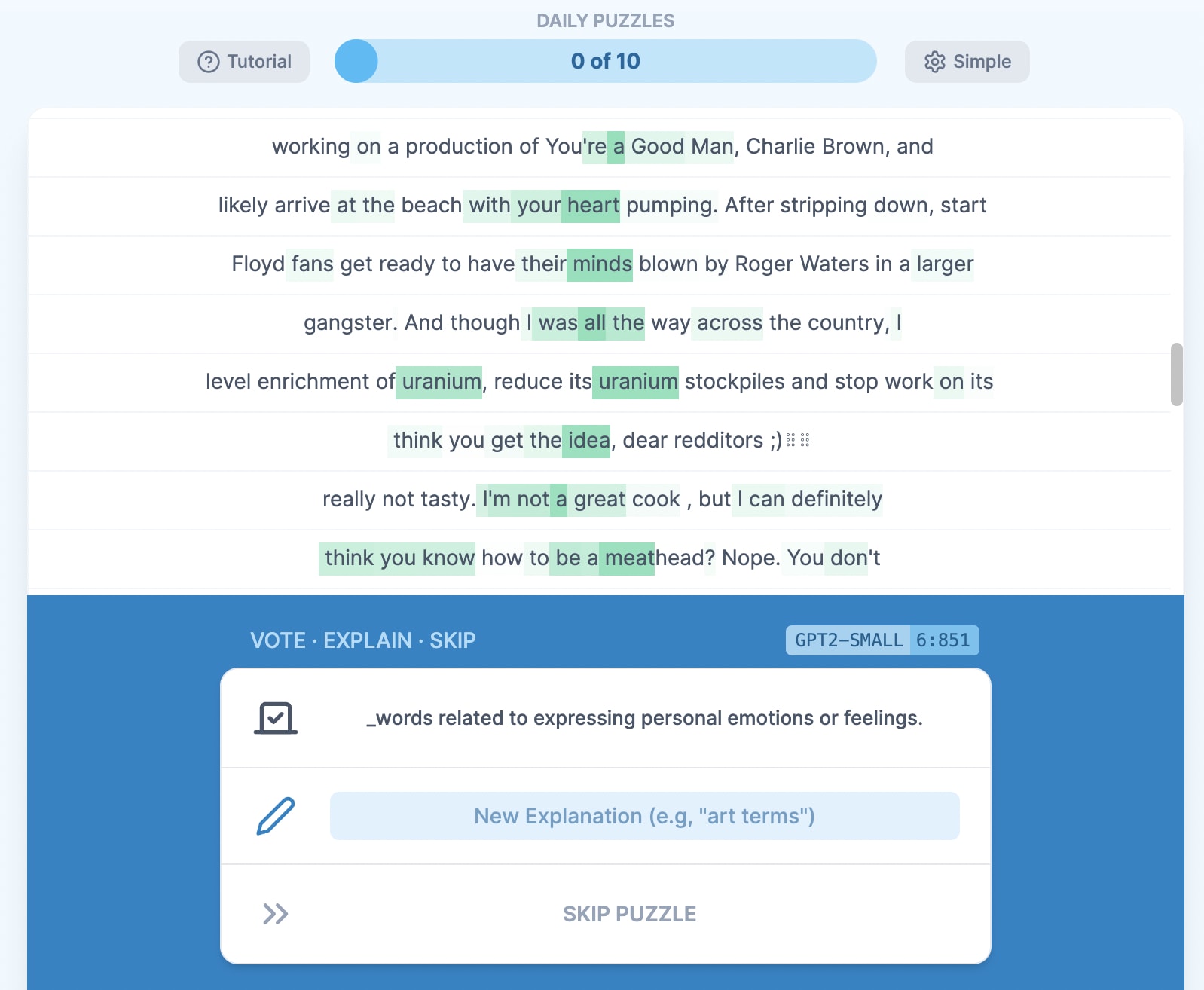
Clearly, the autogenerated explanation of "words related to expressing personal emotions or feelings" doesn't fit at all. But also, coming up with a reasonable explanation myself is really hard. I think probably this neuron is doing something that's inscrutable until you've understood what it's reading and writing—which requires some understanding of the residual stream.
My hope is that the residual stream can mostly be understood in terms of relevant directions, which will represent features or superpositions of features. If users can submit possible mappings of directions -> features, and we can look at what directions the neuron is reading from/writing to, then maybe there's more potential hope for interpreting a neuron like the above. I've been working on a similar tool to yours, which would allow users to submit explanations for residual stream directions. Not online at the moment, but here's a current screenshot of it:
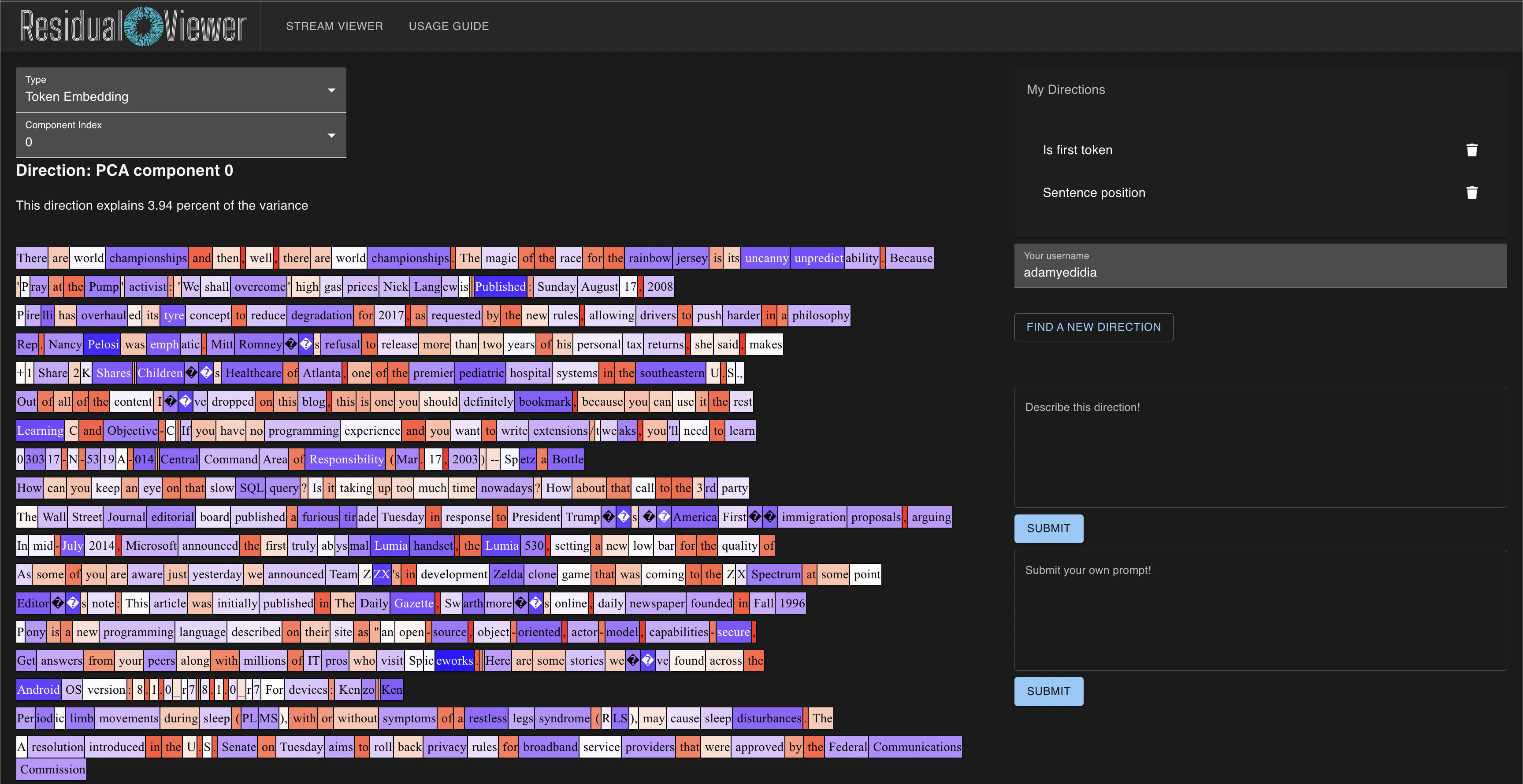
DM me if you'd be interested in talking further, or working together in some capacity. We clearly have a similar approach.
Hi Adam and thanks for your feedback / suggestion. Residual Viewer looks awesome. I have DMed you to chat more about it!
The game is addictive on me, so I can't resist an attempt at describing this one, too :)
It seems related to grammar, possibly looking for tokens on/after articles and possessives
My impression from trying out the game is that most neurons are not too hard to find plausible interpretations for, but most seem to have low-level syntactical (2nd token of a work) or grammatical (conjunctions) concerns.
Assuming that is a sensible thing to ask for, I would definitely be interested in an UI that allows working with the next smallest meaningful construction that features more than a single neuron.
Some neurons seem to have 2 separate low-level patterns that cannot clearly be tied together. This suggests they may have separate "graph neighbors" that rely on them for 2 separate concerns. I would like some way to follow and separate what neurons are doing together, not just individually, if that makes any sense =)
(As an aside, I'd like to apologize that this isn't directly responding to the residuals idea. I'm not sure I know what residuals are, though the description of what can be done with it seems promising, and I'd like to try the other tool when it comes online!)
I love this!
Conceptual Feedback:
- I think it would be better if I could see two explanations and vote on which one I like better (when available).
- Attention heads are where a lot of the interesting stuff is happening, and need lots of interpretation work. Hopefully this sort of approach can be extended to that case.
- The three explanation limit kicked in just as I was starting to get into it. Hopefully you can get funding to allow for more, but in the meantime I would have budgeted my explanations more carefully if I had known this.
- I don't feel like I should get a point for skipping, it makes the points feel meaningless.
UX Feedback:
- I didn't realize that clicking on the previous explanation would cast a vote and take me to the next question. I wanted to go back but I didn't see a way to do that.
- After submitting a new explanation and seeing that I didn't beat the high score, I wanted to try submitting a better explanation, but it glitched out and skipped to the next question.
- I would like to know whether the explanation shown was the GPT-4 created one, or submitted by a user.
- The blue area at the bottom takes up too much space at the expense of the main area (with the text samples).
- It would be nice to be able to navigate to adjacent or related neurons from the neuron's page.
Thanks so much for the feedback! Inline below:
Conceptual Feedback:
- I think it would be better if I could see two explanations and vote on which one I like better (when available).
- When there are multiple explanations, Neuronpedia does display them.
- However I've considered a different game mode where all you do is choose between This Vs That (no skipping, no new explanations). That may be a cool possibility!
- Attention heads are where a lot of the interesting stuff is happening, and need lots of interpretation work. Hopefully this sort of approach can be extended to that case.
- Will put it on the TODO
- The three explanation limit kicked in just as I was starting to get into it. Hopefully you can get funding to allow for more, but in the meantime I would have budgeted my explanations more carefully if I had known this.
- Sorry, the limit is daily, you can come back tomorrow. It currently costs $0.24 to do one explanation score.
- Good idea re: showing limit on number of explanations somehow.
- I don't feel like I should get a point for skipping, it makes the points feel meaningless.
- Yeah I struggled with this a bit. But I didn't want to incentivize people to vote for a bad explanation. E.g, if you only get a point for voting, then you're more inclined (even subconsciously) to vote.
- I'm open to being wrong on this. I'm not a game mechanics expert and happy to change it.
UX Feedback:
- I didn't realize that clicking on the previous explanation would cast a vote and take me to the next question. I wanted to go back but I didn't see a way to do that.
- Great suggestion. Will add it to TODO.
- After submitting a new explanation and seeing that I didn't beat the high score, I wanted to try submitting a better explanation, but it glitched out and skipped to the next question.
- Hmm I'll try to repro this. Thanks for reporting.
- I would like to know whether the explanation shown was the GPT-4 created one, or submitted by a user.
- If you click "Simple" at the top right to toggle to Advanced Mode, it will show you the author and score of the explanations being shown.
- The blue area at the bottom takes up too much space at the expense of the main area (with the text samples).
- Yes, I havent had time to optimize this. Currently it has that space because it will fit 3 explanations, and I wanted the UI to stay more static (and not "jump around") based on the number of explanations. But you are right that this is annoying wasted space most of the time.
- It would be nice to be able to navigate to adjacent or related neurons from the neuron's page.
- Good idea. Added to TODO.
I would really like to be able to submit my own explanations even if they can't be judged right away. Maybe to save costs, you could only score explanations after they've been voted highly by users.
Additionally, it seems clear that a lot of these neurons have polysemanticity, and it would be cool if there was a way to indicate the meanings separately. As a first thought, maybe something like using | to separate them e.g. the letter c in the middle of a word | names of towns near Berlin.
That's a good idea - I think maybe I could make a "drafts" explanation list so you can queue it up for later. Unfortunately since the website just launched, there is not yet a reasonable threshold for "voted highly" since most explanations have none or very few explanations. But this is a good workaround for when the site is a bit older.
Re: multiple meanings - this is interesting. I need to experiment with this more, but I don't think you need to use any special syntax. By writing "the letter c in a word or names of towns near Berlin", it should give you a score based on both of those. There is a related question of, should these neurons should have two highly-voted/rated explanations, or one highly-voted/rated explanation that has both explanations? I'll put that on the TODO as an open question.
EDIT: after thinking about this a bit more-
PRO of multiple separate explanations: if a neuron has 4-5 different meanings it can get unwieldy quickly (and then users might submit an one that is identical, except just swapping the order of each OR explanation)
CON of multiple separate explanations - we probably need ranked choice voting or multi-selection at some point... will put this on the TODO.
Btw - would love to have you in the discord to stay updated and provide additional feedback for Neuronpedia! This is super helpful.
Thanks for the drafts feature!
Yeah, it's a tricky situation. It may even be worth using a model trained to avoid polysemanticity.
I also think it would be make the game both more fun and more useful if you switched to a model like the TinyStories one, where it's much smaller and trained on a more focused dataset.
I may join the discord, but the invite on the website is expired currently fyi.
re: polysemanticity- have a big tweak to the game coming up that may help with this! i hope to get it out by early next week.
lol thanks. i can't believe the link has been broken for so long on the site. it should be fixed in a few seconds from now. in the meantime if you're interested: https://discord.gg/kpEJWgvdAx
I really love the interface as well.
Seconding that I accidentally cast a vote by clicking on an explanation.
I also wonder whether there is confirmation bias from showing you other people's answers right away.
EDIT: this update was pushed just now. it will warn you on your first vote to confirm that you want to vote.
Thanks for playing, Chris!
I'll work on the voting thing. I'll probably just add a "first-timer's" warning on your first vote to ensure that you want to vote for that.
FYI - if you want to unvote, just go to your profile (neuronpedia.org/user/[username]), click the neuron you voted for, and click to unvote on the left side.
Cool concept! Thanks for making it. And that's a lovely looking website, especially for just three weeks!
The core problem with this kind of thing is that often neurons are not actually monosemantic, because models use significant superposition, so the neuron means many different things. This is a pretty insurmountable problem - I don't think it sinks the concept of the website, but it seems valuable to eg have a "this seems like a polysemantic mess" button.
Bug report - in OWT often apostrophes or quote marks are tokenized as two separate tokens, because of a dumb bug in the tokenizer (they're a weird unicode character that it doesn't recognise, so it gets tokenized as two separate bytes). This looks confusing, eg here: (the gap between the name and s is an apostrophe). It's unclear how best to deal with this, my recommendation is to have an empty string and then an apostrophe/quotation mark, and a footnote on hover explaining it.

Hi Neel, thanks for playing and thanks for all your incredible work. Neuronpedia uses a ton of your stuff.
Re: polysemantic neurons - yes, I should address this before wider distribution. Some current ideas - if you have a preference please let me know.
- Your proposed "this is a mess" button
- Allow voting on more than one option at a time (users can do multiple votes for explanations per neuron on the neuron's page, but the game automatically moves on to a new neuron after one vote to keep it more "game-like")
- Encourage "or" explanations: "cat or tomato or purple"
- Add a warning for users
Re: Open Web Text tokenizer bug - thank you! this will make the text more legible. i'll make the display change and footnote.
EDIT: the double unknown chars should now show up as one apostrophe. AFAIK there is no way to tell the difference between a single quote unknown char and a double quote unknown char, but it's probably ok to just show it as single quote for now
Pretty cool! I did the first puzzle, and then got to the login, and noped out. Please let me and other users set up an email account and password! As a matter of principle I don't outsource my logins to central points of identarian failure.
I'd also like to add that having a more normal 3rd party login would help if you want non-programmers to use this (Facebook login is what I'd recommend).
Thanks Brendan - yes - Apple/Google/Email login is coming before public non-beta release. May also add Facebook.
Hi Jennifer,
Thanks for participating - my apologies for only having GitHub login at the moment. Please feel free to create a throwaway Github account if you'd still like to play (I think Github allows you to use disposable emails to sign up - I had no problem creating an account using an iCloud disposable email). Email/password login is definitely on the TODO.
Thank you for creating this website! I’ve signed up and started contributing.
One tip I have for other users: many of the neurons are not about vague sentiments or topics (as in most of the auto-suggested explanations), but are rather about very specific keywords or turns of phrase. I’d even guess that many of the neurons are effectively regexes.
Also apparently Neuronpedia cut me off for the day after I did ~20 neuron puzzles. If this limit could be raised for power users or something like that, it could potentially be beneficial.
Hi duck_master, thank you for playing and appreciate the tip. Maybe it's worth compiling these tips and putting it under a "tips" popup/page on the main site. Also - please consider joining the Discord if you're willing to offer more feedback and suggestions: https://discord.gg/kpEJWgvdAx
Apologies for the limit. It currently costs ~$0.24 to do each explanation score and it's coming from my personal funds, so I'm capping it daily until I can hopefully get approved for a grant. A few hours ago I raised the limit from 3 new explanations per day to 10 new explanations per day.
Subjective opinion: I would probably be happy do a few more past the limit even without the automated explanation score.
If for instances, only the first 10-20 had an automatic score, and the rest where dependent on manual votes (starting at score 0), I think the task would still be interesting, hopefully without causing too much trouble.
(There's also a realistic chance that I may lose attention and forget about the site in a few weeks, despite liking the game, so that (disregarding spam problems) a higher daily limit with reduced functionality maybe has value?)
(As a note, the Discord link also seems to be expired or invalid on my end)
Nice idea and very well implemented. Quite enjoyable too, I hope you keep it going. Just a quick idea that came to mind - perhaps the vote suggestion could be hidden until you click to reveal it perhaps? Think I can feel a little confirmation bias potentially creeping into my answers (so I'm avoiding looking at the suggestion until I've formed my own opinion). Apologies if there is already an option for that or if I missed something. I mostly jumped right in after skimming the tutorial since I have tried reading neurons for meaning before.
Hi Martin,
Thanks for playing! I agree there is some risk of confirmation bias, and the option to hide explanations by default is very interesting.
The reason it is designed the way it is now is because I'd prefer to avoid too many duplicate explanations. Currently, you can only submit explanations that are not exact duplicates, though you can submit explanations that are very similar -e.g, "banana" vs "bananas".
The first downside would be that duplicate explanations may clutter up the voting options. The second downside is when someone is looking at the two explanations later, the vote may be split between the two similar explanations - meaning a third explanation that is worse might actually win (e.g, "cherry" vs "banana(s)").
HOWEVER - those are not insurmountable downsides. the server just has to have a better duplicate/similarity check (maybe even asking GPT4), like check for plurals - and if you explain similarly to an existing explanation, it just automatically upvotes that. I think it's definitely worth experimenting. The similarity check would have to not be too loose, otherwise we may lose out on great explanations that appear to only be marginally different but actually score very differently.
Please keep the feedback coming and join the discord if you'd like to keep updated.
This looks fantastic. Hopefully it may lead to some great things as I've always found the idea of exploiting the collective intelligence of the masses to be a terribly underused resource, and this reminds me of the game Foldit (and hopefully in the future will remind me of the wild success that that game had in the field of protein folding).
Hi, nice work! You mentioned the possibility of neurons being the wrong unit. I think that this is the case and that our current best guess for the right unit is directions in the output space, ie linear combinations of neurons.
We've done some work using dictionary learning to find these directions (see original post, recent results) and find that with sparse coding we can find dictionaries of features that are more interpretable the neuron basis (though they don't explain 100% of the variance).
We'd be really interested to see how this compares to neurons in a test like this and could get a sparse-coded breakdown of gpt2-small layer 6 if you're interested.
Thank you Hoagy. Expanding beyond the neuron unit is a high priority. I'd like to work with you, Logan Riggs, and others to figure out a good way to make this happen in the next major update so that people can easily view, test, and contribute. I'm now creating a new channel on the discord (#directions) to discuss this: https://discord.gg/kpEJWgvdAx, or I'll DM you my email if you prefer that.
So I've been developing dictionaries that automatically find interesting directions in activation space, which could just be an extra category. Here's my post w/ interesting directions, including German direction & Title Case direction.
I don't think this should be implement in the next month, but when we have more established dictionaries for models, I would be able to help provide data to you.
Additionally, it'd be useful to know which tokens in the context are most responsible for the activation. There is likely some gradient-based attribution method to do this. Currently, I just ablate each token in the context, one at a time, and check which ones affect the token the most, which really helps w/ bigram features e.g. " the [word]" feature which activates for most words after " the".
Impact
The highest impact part of this seems to be two-fold:
- Gathering data for GPT-5 to be trained on (though not likely to collect several GB's of data, but maybe)
- Figuring out the best source of information & heuristics to predict activations
For both of these, I'm expecting people to also try to predict activations given an explanation (just like auto-interp does currently for OpenAI's work).
Hi Logan - thanks for your response. Your dictionaries post is on the TODO to investigate and integrate (someone had referred me to it two weeks ago) - I'd love to make it happen.
Thanks for joining the Discord. Let's discuss when I have a few days to get caught up with your work.
Unstructured feedback:
Thought of leaving when I was given my first challenge and thought, "what if these words actually don't have much in common, what if the neurons all just encode completely arbitrary categories due to being such a low strength model." Eventually I decided "No, I know what this is. This is A Thing. (words that suggest the approach towards some sort of interpersonal resolution)." Maybe that happens to everyone. I dunno.
It's kind of infuriating that you ask us to do a question, then don't accept the answer until we log in, then just waste our answer by sending us to another question after we've logged in. I guess you plan to solve the last part, in which case it's fine, but wow, like, you're going to smack every single one of your testers in the face with this?
My experience with the second question is that sending in a response does not work, I get an alert about a json parse error. Firefox.
Tell me when that's fixed, I guess.
hey mako - sorry about the issues. i'm looking into it right now. will update asap
edit: looks like the EC2 instance hard crashed. i can't even restart it from AWS console. i am starting up a new instance with more RAM.
edit2: confirmed via syslog (after taking a long time to restart the old server) it was OOM. new machine has 8x more ram. added monitoring and will investigate potential memory leaks tomorrow
Should be working now.
Also, thank you for the feedback re- janky tutorial/signin. I will fix that. It is truly a terrible way to have a first experience with a product.
EDIT: the tutorial -> sign in friction has been updated.
Suggestion: an option to vote that one's not sure that any existing explanation fits
Yes, this is a great idea. I think something other than "skip" is needed since skip isn't declaring "this neuron has too many meanings or doesn't seem to do anything", which is actually useful information
Very cool. Thanks for putting this together.
Half-baked, possibly off-topic: I wonder if there's some data-collection that can be used to train out polysemi from a model by fine-tuning.
e.g.:
- Show 3 examples (just like in this game), and have the user pick the odd-one-out
- User can say "they are all the same", if so, remove one at random, and replace with a new example
- Tag the (neuron, positive example) pairs with (numerical value) label 1, the odd-one-out with 0
- Fine-tune with next-word-prediction and an auxilliary loss using this new collected dataset
- Can probably use some automated (e.g. semantic similarity) labelling method to cluster labelled+unlabelled instances, to increase the size of the dataset
Neuronpedia interface/codebase could probably be forked to do this kind of data collection very easily.
I love these variations on the game. Yes, the idea is to build a scalable backend and then we can build various different games on top of it. Initially there was no game and it was just browsing random neurons manually! Then the game was built on top of it. Internally I call the current Neuronpedia game "Vote Mode".
Would love to have you on our Discord even if just to lurk and occasionally pitch an idea. Thanks for playing!
It looks pretty cool! Adding a Google sign-in option would greatly broaden the reach of the game as most non-technical people do not have a Github account.
Thank you - yes, this is on the TODO along with Apple Sign-In. It will likely not be difficult, but it's in beta experiment phase right now for feedback and fixes - we aren't yet ready for the scale of the general public.
Thanks for the quick response, have you tried fine-tuning the new llama2 models on the data gathered so far to see if there is any interesting results? QLORA is pretty efficient for this.
Very cool idea!
It looked like several of the text samples were from erotica or something, which...seems like something I don't want to see without actively opting in--is there an easy way for you to filter those out?
Hi Nathan, thanks for playing and pointing out the issue. My apologies for the inappropriate text.
Half the text samples are from Open Web Text, which is scraped web data that GPT2 was trained on. I don't know the exact details, but I believe some of it was reddit and other places.
If you DM me the neurons address next time you see them, I can start compiling a filter. I will also try to look for an open source library to categorize into safe and not safe.
My apologies again. This is a beta experiment, thanks for putting up with this while I fix the issues.
Hey Nathan, so sorry this took so long. Finally shipped this - you can now toggle "Profanity/Explicit" OFF in "Edit Profile". Some notes about the implementation:
- If enabled, hides activation texts that have a bad word in it (still displays the neuron)
- Works by checking a list of bad words
- Default is disabled (profanity shown) in order to get more accurate explanations
- Asks user during onboarding for their preference
It turns out that nearly all neurons have some sort of explicit (or "looks like explicit") text, so it's not feasible to automatically skip all these neurons - we end up skipping everything. So we only hide the individual activation texts that are explicit.
Sorry again and thanks for the feedback!
I got a little weirded out at the OAuth prompt because it said "johnny" wanted to get my account. I know who Neuronpedia is. I didn't know who "johnny" was until I did some more reading and figured out that you're Johnny.
Please consider registering a dedicated account for the organization ("Neuropedia", perhaps) and doing the OAuth through the organization's account so that the prompt doesn't surprise users as much.
Sorry about that! Should have fixed that way earlier. I've transferred the app to "Neuronpedia", so it should appear correctly now. Thank you for flagging this.
Edit - Neuronpedia has pivoted to be a research tool for Sparse Autoencoders, so most of this post is outdated. Please read the new post, Neuronpedia: Accelerating Sparse Autoencoders Research.
Neuronpedia is an AI safety game that documents and explains each neuron in modern AI models. It aims to be the Wikipedia for neurons, where the contributions come from users playing a game. Neuronpedia wants to connect the general public to AI safety, so it's designed to not require any technical knowledge to play.
Neuronpedia is in experimental beta: getting its first users in order to collect feedback, ideas, and build an initial community.
OBJECTIVES
CURRENT STATUS
WHAT YOU CAN DO
THE VISION
HOW NEURONPEDIA CAME ABOUT
After moving on from my previous startup, I reached out to 80,000 Hours for career advice. They connected me to William Saunders who provided informal (not affiliated with any company) guidance on what might be useful products to develop for AI safety research. Three weeks ago, I started prototyping versions of Neuronpedia, starting as a reference website, then eventually iterating into a game.
Neuronpedia is seeded with data and tools from OpenAI's Automated Interpretability and Neel Nanda's Neuroscope.
IS THIS SUSTAINABLE?
Unclear. There's no revenue model, and there is nobody supporting Neuronpedia. I'm working full time on it and spending my personal funds on hosting, inference servers, OpenAI API, etc. If you or your organization would like to support this project, please reach out at johnny@neuronpedia.org.
COUNTERARGUMENTS AGAINST NEURONPEDIA
These are reasons Neuronpedia could fail to achieve one or more of its objectives. They're not insurmountable, but good to keep in mind.