The danger from power-seeking is not intrinsic to the alignment problem. This danger also depends on the structure of the agent's environment.
In The Catastrophic Convergence Conjecture, I wrote:

But are there worlds where this isn't true? Consider a world where you supply a utility-maximizing AGI with a utility function.
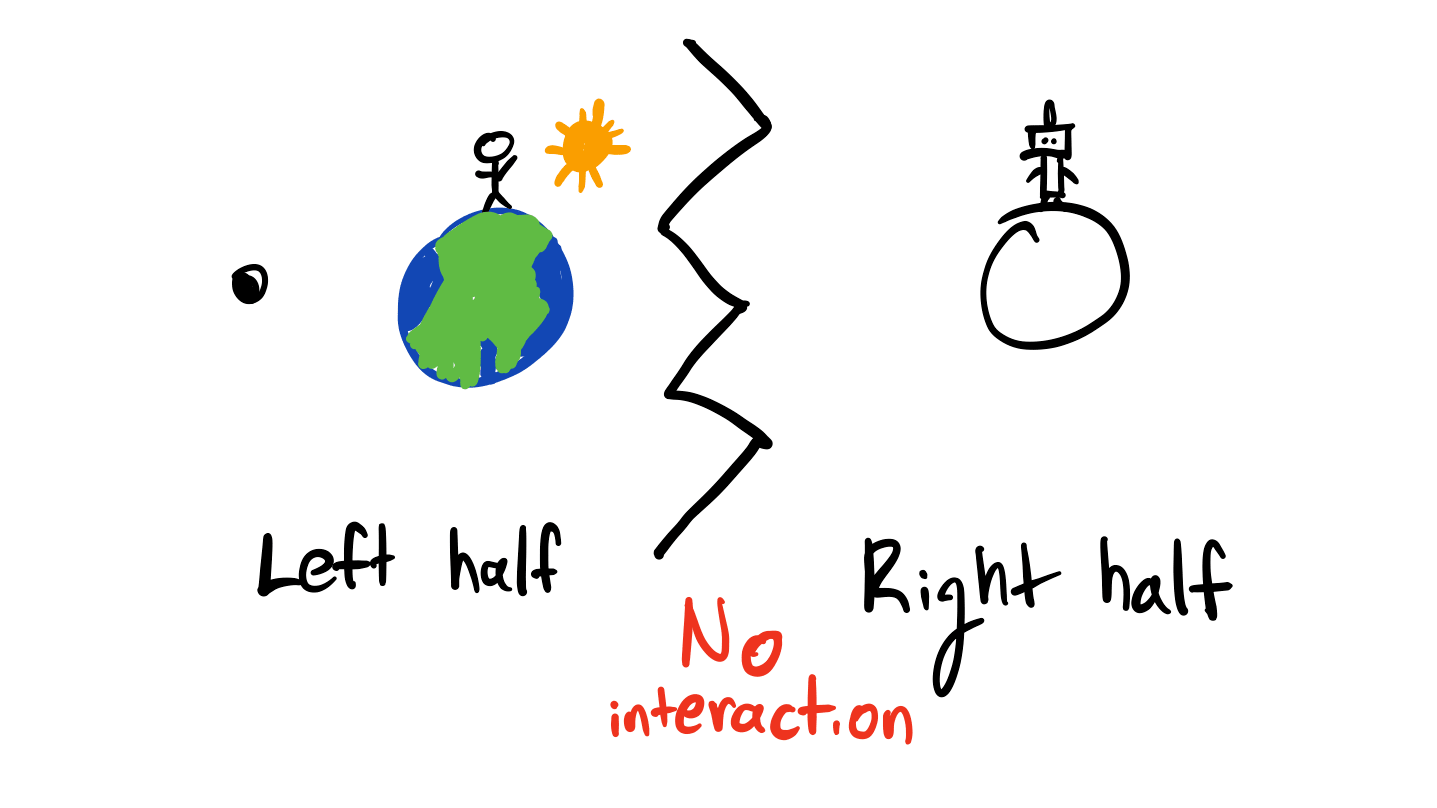
The only information you have about the other half is your utility. For simplicity, let's suppose you and the AGI have utility functions over universe-histories which are additive across the halves of the universe. You don't observe any utility information about the other part of the universe until the end of time, and vice versa for the AGI. That is, for history ,
If the AGI uses something like causal decision theory, then it won't try to kill you, or "seek power" over you. The effects of its actions have no causal influence over what happens in your half of the universe. Your universe's evolution adds a constant term to its expected utility.
(Other decision theories might have it precommit to minimizing human utility unless it attains maximal AGI-utility from the left half of the universe-history, or some other shenanigans. This is beside the point I want to make in this post, but it's important to consider.)
However, the setup is still interesting because
- Goodhart's law still applies: if you give the AGI an incomplete proxy objective, you'll get suboptimal true performance.
- Value is still complex: it's still hard to get the AGI to optimize the right half of the universe for human flourishing.
- If the AGI is autonomously trained via stochastic gradient descent in the right half of the universe, then we may still hit inner alignment problems.
Alignment is still hard, and we still want to get the AGI to do good things on its half of the universe. But it isn't instrumentally convergent for the AGI to seek power over you, and so you shouldn't expect an unaligned AGI to try to kill you in this universe. You shouldn't expect the AGI to kill other humans, either, since none exist in the right half of the universe - and it won't create any, either.
To restate: Bostrom's original instrumental convergence thesis needs to be applied carefully. The danger from power-seeking is not intrinsic to the alignment problem. This danger also depends on the structure of the agent's environment. I think I sometimes bump into reasoning that feels like "instrumental convergence, smart AI, & humans exist in the universe -> bad things happen to us / the AI finds a way to hurt us"; I think this is usually true, but not necessarily true, and so this extreme example illustrates how the implication can fail.
Thanks to John Wentworth for feedback on this post. Edited to clarify the broader point I'm making.
This post uses the phrase "Bostrom's original instrumental convergence thesis". I'm not aware of there being more than one instrumental convergence thesis. In the 2012 paper that is linked here the formulation of the thesis is identical to the one in the book Superintelligence (2014), except that the paper uses the term "many intelligent agents" instead of "a broad spectrum of situated intelligent agents".
In case it'll be helpful to anyone, the formulation of the thesis in the book Superintelligence is the following:
I'm not sure what you meant here by saying that the instrumental convergence thesis "needs to be applied carefully", and how the example you gave supports this. Even in environments where the agent is "alone", we may still expect the agent to have the following potential convergent instrumental values (which are all mentioned both in the linked paper and in the book Superintelligence as categories where "convergent instrumental values may be found"): self-preservation, cognitive enhancement, technological perfection and resource acquisition.
I think that most of the citations in Superintelligence are in endnotes. In the endnote that follows the first sentence after the formulation of instrumental convergence thesis, there's an entire paragraph about Stephen Omohundro's work on the topic (including citations of Omohundro's "two pioneering papers on this topic").