We develop a simple model that predicts progress in the performance of field-effect transistor-based GPUs under the assumption that transistors can no longer miniaturize after scaling down to roughly the size of a single silicon atom. We construct a composite model from a performance model (a model of how GPU performance relates to the features of that GPU), and a feature model (a model of how GPU features change over time given the constraints imposed by the physical limits of miniaturization), each of which are fit on a dataset of 1948 GPUs released between 2006 and 2021. We find that almost all progress can be explained by two variables: transistor size and the number of cores. Using estimates of the physical limits informed by the relevant literature, our model predicts that GPU progress will stop roughly between 2027 and 2035, due to decreases in transistor size. In the limit, we can expect that current field-effect transistor-based GPUs, without any paradigm-altering technological advances, will be able to achieve a peak theoretical performance of 1e14 and 1e15 FLOP/s in single-precision performance.
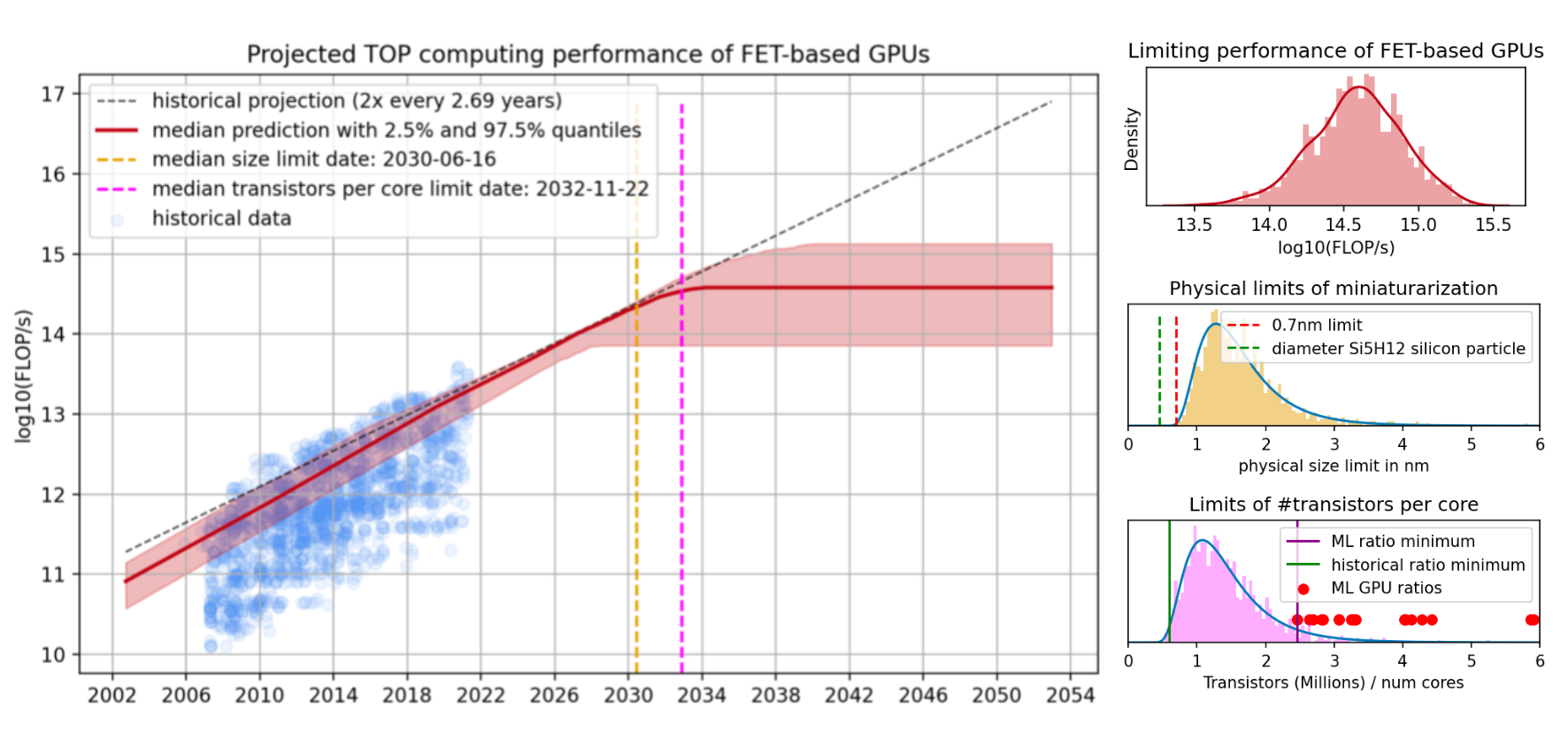
While there are many other drivers of GPU performance and efficiency improvements (such as memory optimization, improved utilization, and so on), decreasing the size of transistors has historically been a great, and arguably the dominant, driver of GPU performance improvements. Our work therefore strongly suggests that it will become significantly harder to achieve GPU performance improvements around the mid-2030s within the longstanding field-effect transistor-based paradigm.
This post is just the executive summary, you can find the full report on the Epoch website.
Yep, I think you're right that both views are compatible. In terms of performance comparison, the architectures are quite different and so while looking at raw floating-point performance gives you a rough idea of the device's capabilities, performance on specific benchmarks can be quite different. Optimization adds another dimension entirely, for example NVIDIA has highly-optimized DNN libraries that achieve very impressive performance (as a fraction of raw floating-point performance) on their GPU hardware. AFAIK nobody is spending that much effort (e.g. teams of engineers x several months) to optimize deep learning models on CPU these days because it isn't worth the return on investment.