This is a special post for quick takes by Lorxus. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
On @TsviBT's recommendation, I'm writing this up quickly here.
re: the famous graph from https://transformer-circuits.pub/2022/toy_model/index.html#geometry with all the colored bands, plotting "dimensions per feature in a model with superposition", there look to be 3 obvious clusters outside of any colored band and between 2/5 and 1/2, the third of which is directly below the third inset image from the right. All three of these clusters are at 1/(1-S) ~ 4.
A picture of the plot, plus a summary of my thought processes for about the first 30 seconds of looking at it from the right perspective:
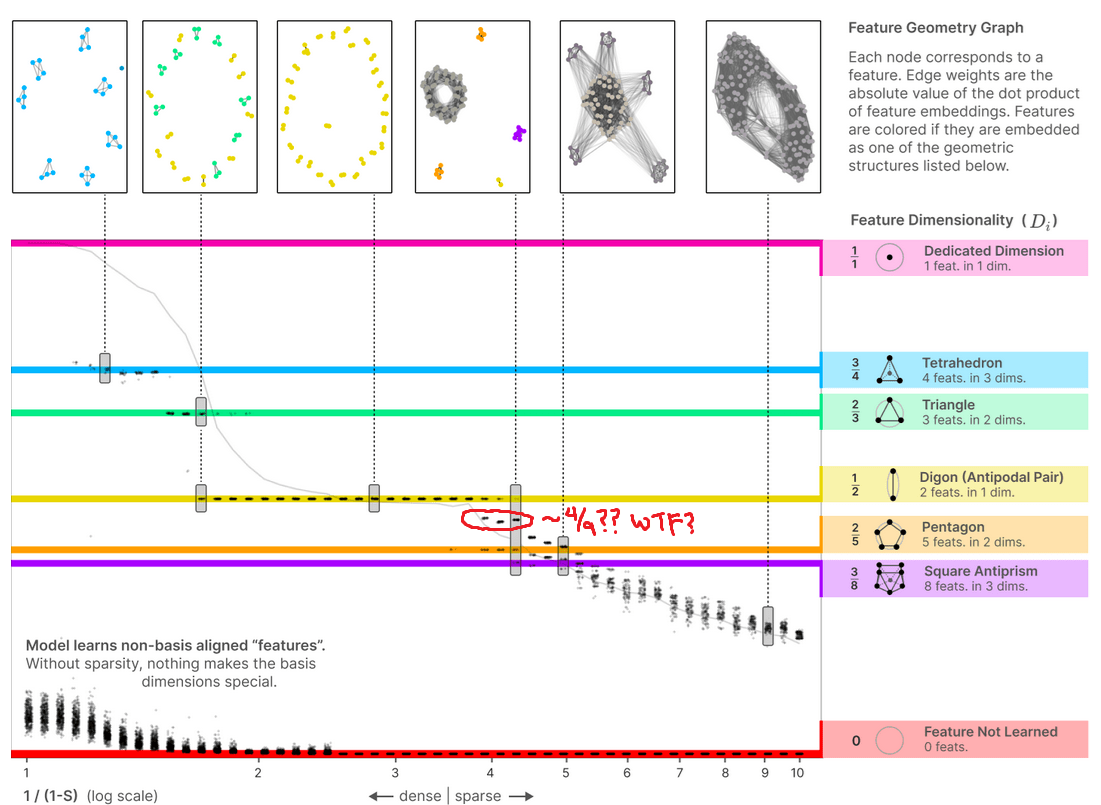
In particular, the clusters appear to correspond to dimensions-per-feature of about 0.44~0.45, that is, 4/9. Given the Thomson problem-ish nature of all the other geometric structures displayed, and being professionally dubious that there should be only such structures of subspace dimension 3 or lower, my immediate suspicion since last week when I first thought about this is that the uncolored clusters should be packing 9 vectors as far apart from each other as possible on the surface of a 3-sphere in some 4D subspace.
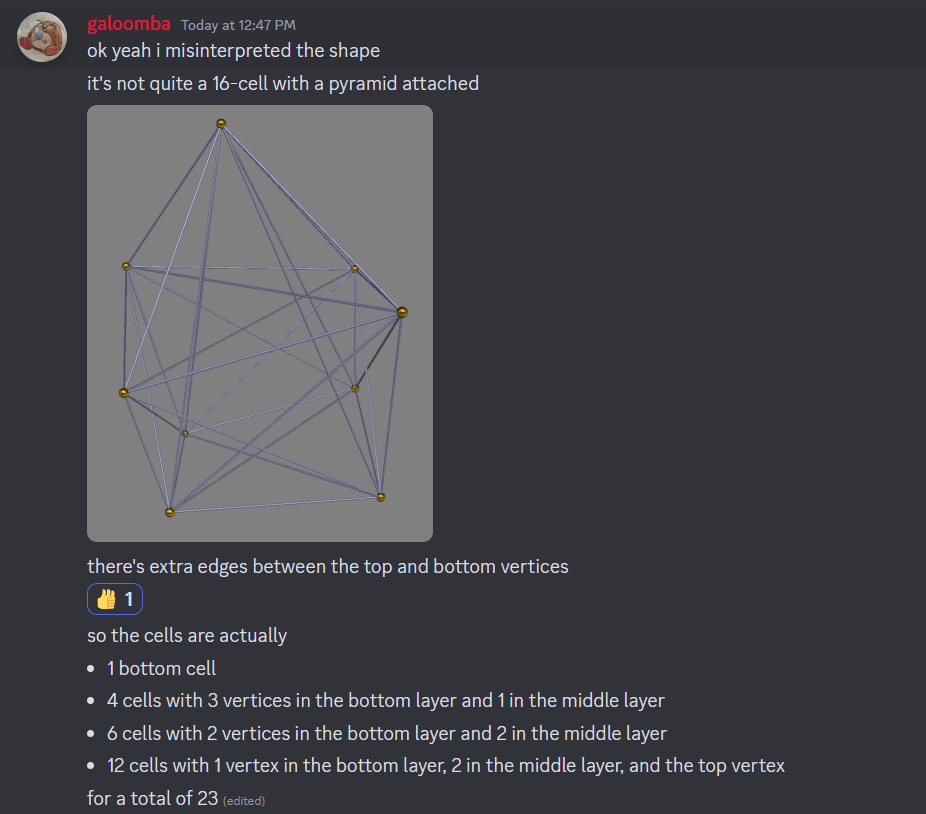
In particular, mathematicians have already found a 23-celled 4-tope with 9 vertices (which I have made some sketches of) where the angular separation between vertices is ~80.7° : http://neilsloane.com/packings/index.html#I . Roughly, the vertices are: the north pole of S^3; on a slice just (~9°) north of the equator, the vertices of a tetrahedron "pointing" in some direction; on a slice somewhat (~19°) north of the south pole, the vertices of a tetrahedron "pointing" dually to the previous tetrahedron. The edges are given by connecting vertices in each layer to the vertices in the adjacent layer or layers. Cross sections along the axis I described look like growing tetrahedra, briefly become various octahedra as we cross the first tetrahedon, and then resolve to the final tetrahedron before vanishing.
I therefore predict that we should see these clusters of 9 embedding vectors lying roughly in 4D subspaces taking on pretty much exactly the 23-cell shape mathematicians know about, to the same general precision as we'd find (say) pentagons or square antiprisms, within the model's embedding vectors, when S ~ 3/4.
Potentially also there's other 3/f, 4/f, and maybe 5/f; given professional experience I would not expect to see 6+/f sorts of features, because 6+ dimensions is high-dimensional and the clusters would (approximately) factor as products of lower-dimensional clusters already listed. There's a few more clusters that I suspect might correspond to 3/7 (a pentagonal bipyramid?) or 5/12 (some terrifying 5-tope with 12 vertices, I guess), but I'm way less confident in those.
A hand-drawn rendition of the 23-cell in whiteboard marker:
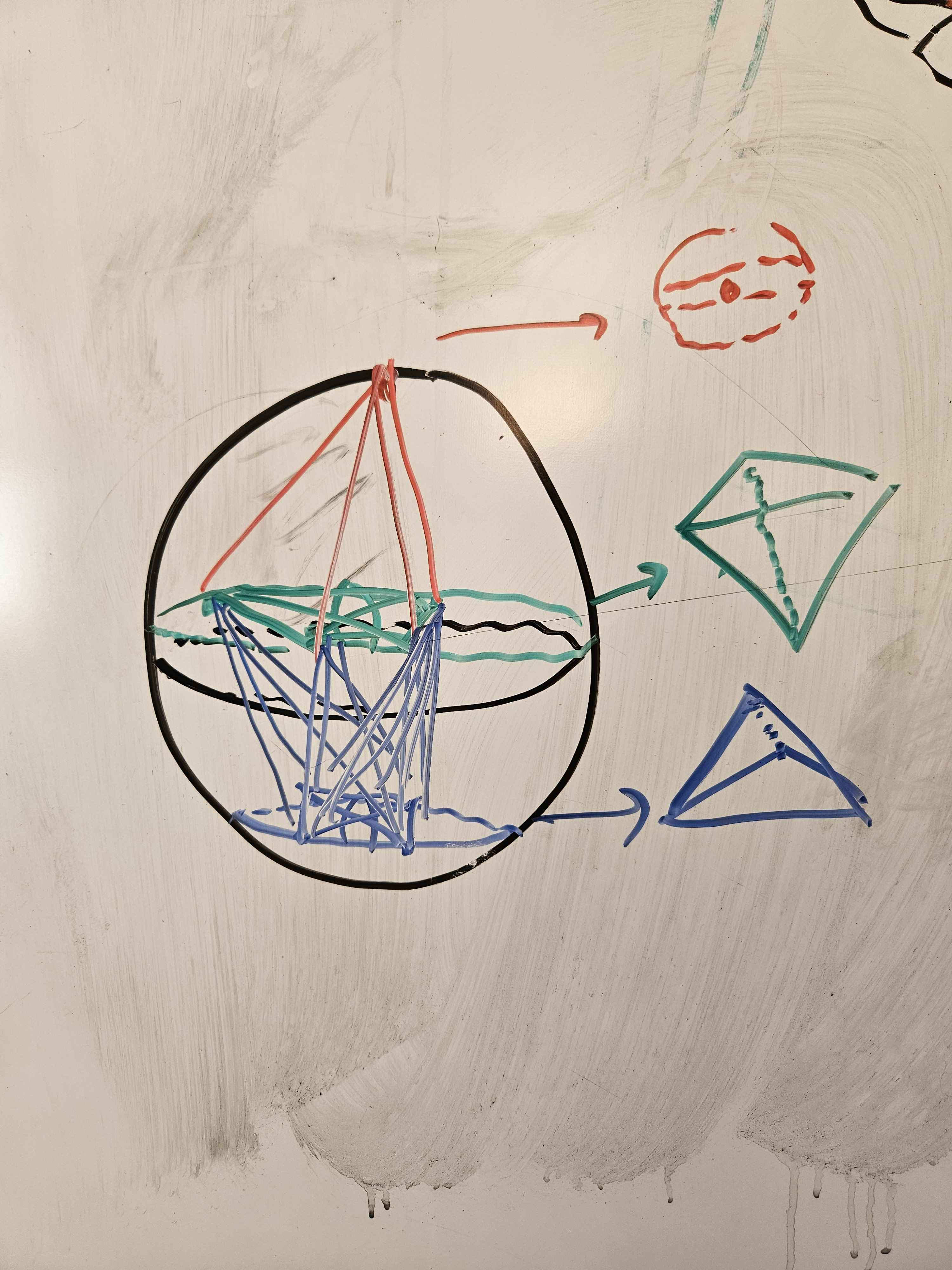
I played with this with a colab notebook way back when. I can't visualize things directly in 4 dimensions, but at the time I came up with the trick of visualizing the pairwise cosine similarity for each pair of features, which gives at least a local sense of what the angles are like.
Trying to squish 9 features into 4 dimensions looks to me like it either ends up with
- 4 antipodal pairs which are almost orthogonal to one another, and then one "orphan" direction squished into the largest remaining space
OR - 3 almost orthogonal antipodal pairs plus a "Y" shape with the narrow angle being 72º and the wide angles being 144º
- For reference this is what a square antiprism looks like in this type of diagram:
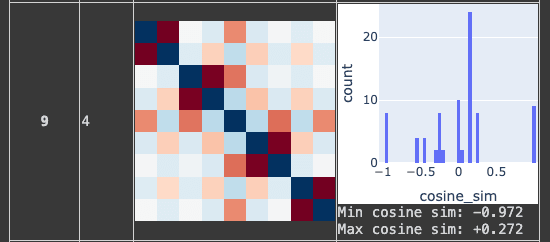
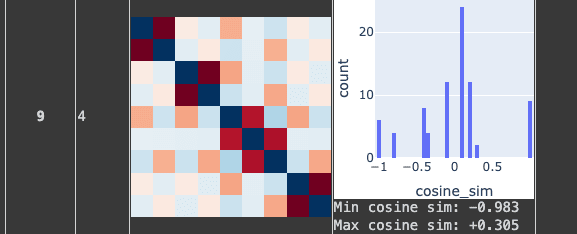
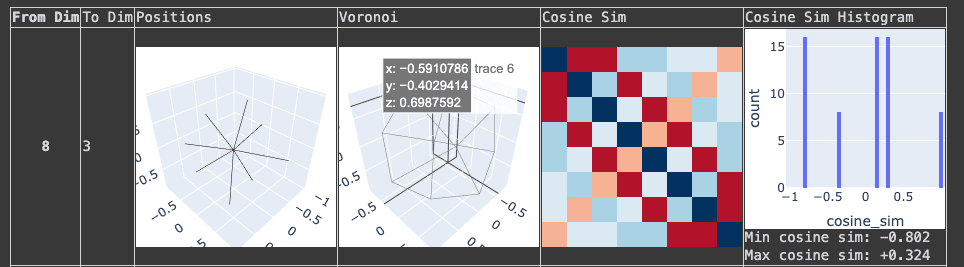
You maybe got stuck in some of the many local optima that Nurmela 1995 runs into. Genuinely, the best sphere code for 9 points in 4 dimensions is known to have a minimum angular separation of ~1.408 radians, for a worst-case cosine similarity of about 0.162.
You got a lot further than I did with my own initial attempts at random search, but you didn't quite find it, either.
A snowclone summarizing a handful of baseline important questions-to-self: "What is the state of your X, and why is that what your X's state is?" Obviously also versions that are less generally and more naturally phrased, that's just the most obviously parametrized form of the snowclone.
Classic(?) examples:
"What do you (think you) know, and why do you (think you) know it?" (X = knowledge/belief)
"What are you doing, and why are you doing it?" (X = action(-direction?)/motivation?)
Less classic examples that I recognized or just made up:
"How do you feel, and why do you feel that way?" (X = feelings/emotions)
"What do you want, and why do you want it?" (X = goal/desire)
"Who do you know here, and how do you know them?" (X = social graph?)
"What's the plan here, and what are you hoping to achieve by that plan?" (X = plan)
Wait, some of y'all were still holding your breaths for OpenAI to be net-positive in solving alignment?
After the whole "initially having to be reminded alignment is A Thing"? And going back on its word to go for-profit? And spinning up a weird and opaque corporate structure? And people being worried about Altman being power-seeking? And everything to do with the OAI board debacle? And OAI Very Seriously proposing what (still) looks to me to be like a souped-up version of Baby Alignment Researcher's Master Plan B (where A involves solving physics and C involves RLHF and cope)? That OpenAI? I just want to be very sure. Because if it took the safety-ish crew of founders resigning to get people to finally pick up on the issue... it shouldn't have. Not here. Not where people pride themselves on their lightness.
I promise I am still working on working out all the consequences of the string diagram notation for latential Bayes nets, since the guts of the category theory are all fixed (and can, as a mentor advises me, be kept out of the public eye as they should be). Things can be kept (basically) purely in terms of string diagrams. In whatever post I write, they certainly will be.
I want to be able to show that isomorphism of natural latents is the categorical property I'm ~97% sure it is (and likewise for minimal and maximal latents). I need to sit myself down and at least fully transcribe the Fundamental Theorem of Latents in preparation for supplying the proof to that.
Mostly I'm spending a lot of time on a data science bootcamp and an AISC track and taking care of family and looking for work/funding and and and.
I guess? I mean, there's three separate degrees of "should really be kept contained"-ness here:
- Category theory -> string diagrams, which pretty much everyone keeps contained, including people who know the actual category theory
- String diagrams -> Bayes nets, which is pretty straightforward if you sit and think for a bit about the semantics you accept/are given for string diagrams generally and maybe also look at a picture of generators and rules - not something anyone needs to wrap up nicely but it's also a pretty thin
- [Causal theory/Bayes net] string diagrams -> actual statements about (natural) latents, which is something I am still working on; it's turning out to be pretty effortful to grind through all the same transcriptions again with an actually-proof-usable string diagram language this time. I have draft writeups of all the "rules for an algebra of Bayes nets" - a couple of which have turned out to have subtleties that need working out - and will ideally be able to write down and walk through proofs entirely in string diagrams while/after finishing specifications of the rules.
So that's the state of things. Frankly I'm worried and generally unhappy about the fact that I have a post draft that needs restructuring, a paper draft that needs completing, and a research direction to finish detailing, all at once. If you want some partial pictures of things anyway all the same, let me know.
I just meant the "guts of the category theory" part. I'm concerned that anyone says that it should be contained (aka used but not shown), and hope it's merely that you'd expect to lose half the readers if you showed it. I didn't mean to add to your pile of work and if there is no available action like snapping a photo that takes less time than writing the reply I'm replying to did, then disregard me.
The phrasing I got from the mentor/research partner I'm working with is pretty close to the former but closer in attitude and effective result to the latter. Really, the major issue is that string diagrams for a flavor of category and commutative diagrams for the same flavor of category are straight-up equivalent, but explicitly showing this is very very messy, and even explicitly describing Markov categories - the flavor of category I picked as likely the right one to use, between good modelling of Markov kernels and their role doing just that for causal theories (themselves the categorification of "Bayes nets up to actually specifying the kernels and states numerically") - is probably too much to put anywhere in a post but an appendix or the like.
...if there is no available action like snapping a photo that takes less time than writing the reply I'm replying to did...
There is not, but that's on me. I'm juggling too much and having trouble packaging my research in a digestible form. Precarious/lacking funding and consequent binding demands on my time really don't help here either. I'll add you to the long long list of people who want to see a paper/post when I finally complete one.
I guess a major blocker for me is - I keep coming back to the idea that I should write the post as a partially-ordered series of posts instead. That certainly stands out to me as the most natural form for the information, because there's three near-totally separate branches of context - Bayes nets, the natural latent/abstraction agenda, and (monoidal category theory/)string diagrams - of which you need to somewhat understand some pair in order to understand major necessary background (causal theories, motivation for Bayes net algebra rules, and motivation for string diagram use), and all three to appreciate the research direction properly. But I'm kinda worried that if I start this partially-ordered lattice of posts, I'll get stuck somewhere. Or run up against the limits of what I've already worked out yet. Or run out of steam with all the writing and just never finish. Or just plain "no one will want to read through it all".
(Random thought I had and figured this was the right place to set it down:) Given how centally important token-based word embeddings as to the current LLM paradigm, how plausible is it that (put loosely) "doing it all in Chinese" (instead of English) is actually just plain a more powerful/less error-prone/generally better background assumption?
Associated helpful intuition pump: LLM word tokenization is like a logographic writing system, where each word corresponds to a character of the logography. There need be no particular correspondence between the form of the token and the pronunciation/"alphabetical spelling"/other things about the word, though it might have some connection to the meaning of the word - and it often makes just as little sense to be worried about the number of grass radicals in "草莓" as it does to worry about the number of r's in a "strawberry" token.
(And yes, I am aware that in Mandarin Chinese, there's lots of multi-character words and expressions!)
Because RLHF works, we shouldn't be surprised when AI models output wrong answers which are specifically hard for humans to distinguish from a right answer.
This observably (seems like it) generalizes to all humans, instead of (say) it being totally trivial somehow to train an AI on feedback only from some strict and distinguished subset of humanity such that any wrong answers it produced could be easily spotted by the excluded humans.
Such wrong answers which look right (on first glance) also observably exist, and we should thus expect that if there's anything like a projection-onto-subspace going on here, our "viewpoint" for the projection, given any adjudicating human mind, is likely all clustered in some low-dimensional subspace of all possible viewpoints and maybe even just around a single point.
This is why I'd agree that RLHF was so specifically a bad tradeoff in capabilities improvement vs safety/desirability outcomes but still remain agnostic as to the absolute size of that tradeoff.
I just meant the "guts of the category theory" part. I'm concerned that anyone says that it should be contained (aka used but not shown), and hope it's merely that you'd expect to lose half the readers if you showed it. I didn't mean to add to your pile of work and if there is no available action like snapping a photo that takes less time than writing the reply I'm replying to did, then disregard me.