TL/DR:
GPT-3 was trained on 10,000 NVIDIA V100’s for 14.8 days. Based on my - very uncertain - estimates, OpenAI should now be able train a comparably capable model on an equivalent cluster in under an hour. This implies a drop in hardware requirements of more than 400x.
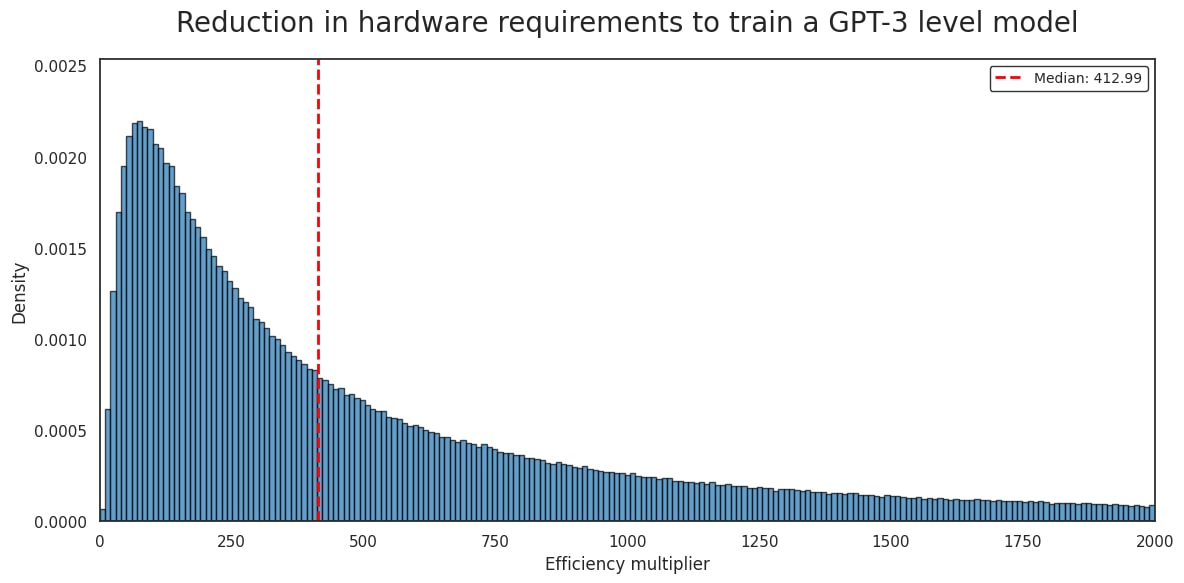
Factoring out increases in hardware efficiency, I arrive at a central estimate of 170x fewer FLOP to reach GPT-3 level performance today.
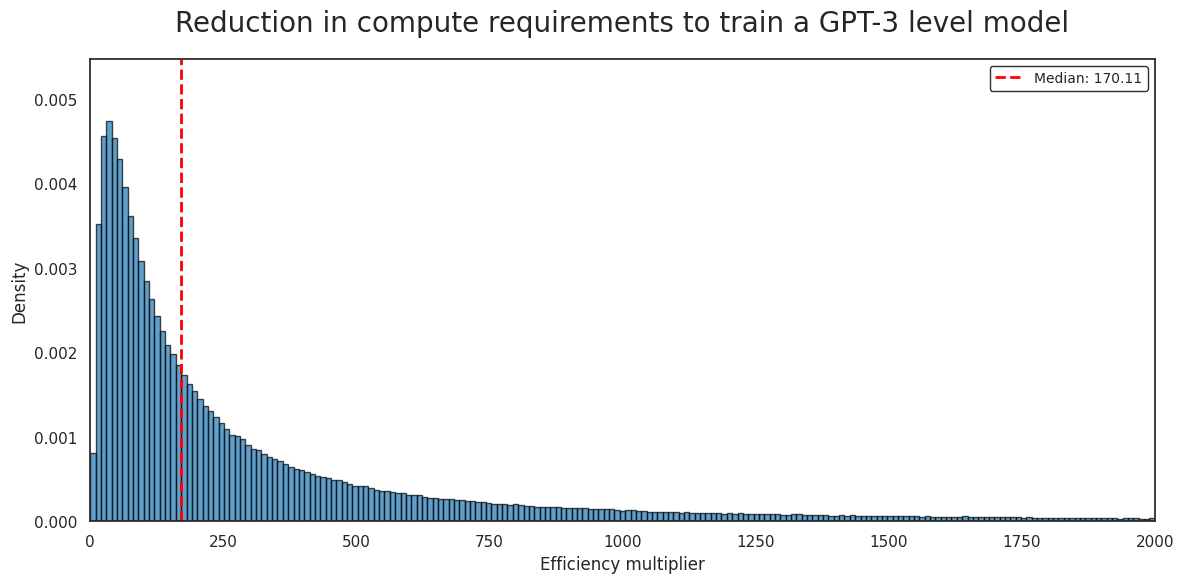
By comparison, GPT-3 to GPT-4 was an estimated 40x increase in pf16-equivalent GPU-hours, and an estimated 68x increase in FLOP. I expect OpenAI to have access to significantly more resources today though, than when pre-training GPT-4. This suggests that resources and resource efficiency are growing... (read 6239 more words →)
Thanks for the comment! I agree that would be a good way to more systematically measure algorithmic efficiency improvements. You won't be able to infer the effects of differences in data quality though - or are you suggesting you think those are very limited anyway?