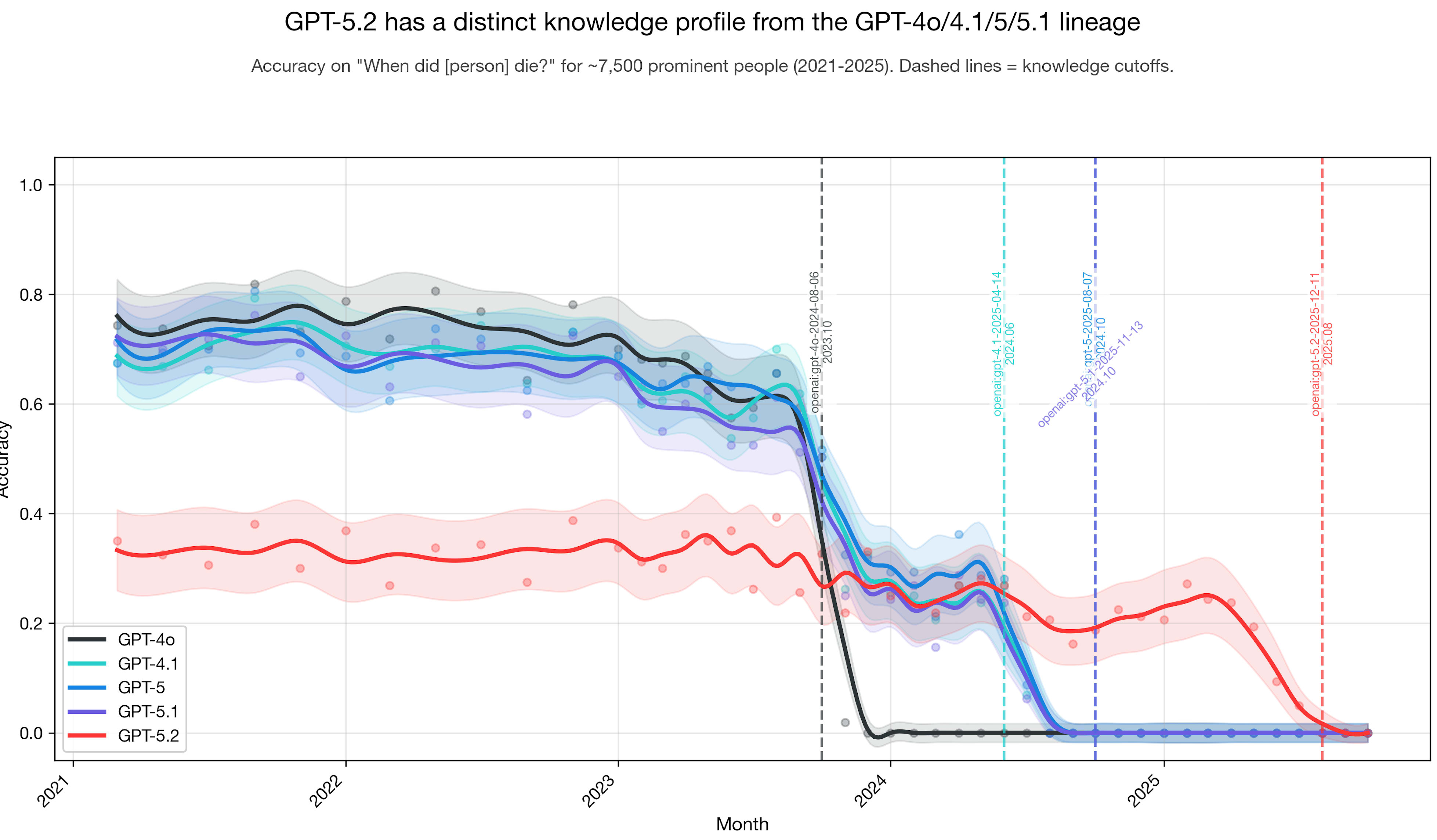
Based on the plot below, my intuition is that GPT-5 and GPT-5.1 had some pretraining data added to the original base pretraining dataset (or base model) dating back to GPT-4o; and GPT-5.2 is something different. I did this experiment a while back.
On the apocalyptic residual, or: the secret third way to save the world.
Bostrom's Vulnerable World Hypothesis says our world is vulnerable. The most commonly discussed threat model are his "Type-1 vulnerabilities": destructive technologies such as bioengineered pandemics.
There are three steps required for our world to be destroyed in this way:
- The dangerous technology exists and is available to many people;
- There are no defensive technologies to protect us;
- A number of people want to destroy the world; we call those people the apocalyptic residual.
If all three are satisfied at any point in time, we die.
Most work on AI safety has been focused on (1) and (2). To be precise, here is a non-exhaustive list of efforts towards mitigating the vulnerable world hypothesis, focused on biorisk:
- Control the availability of dangerous technology: Labs have been tracking offensive biorisk capabilities (see e.g. GDM Frontier Safety, OpenAI Preparedness, Anthropic Frontier Red Team) and developing model safeguards. There is also work on filtering pretraining data and unlearning to remove dangerous capabilities from LLMs. Regarding open-weight LLMs, there is work on biorisk capability elicitation and tamper-resistant safeguards.
- Build defenses to dangerous technology: Vitalik's d/acc and Michael Nielsen's Notes on differential technological development have inspired a bunch of investment into defensive technology development. From the biorisk side, SecureBio exists; Open Phil has been funding work on biosecurity preparedness for a long time, and in 2025 AI labs have started funding biorisk prevention startups. To be clear, the infrastructure developed by the mRNA and Big Pharma companies since 2010 likely dwarfs the AI-lab-led and def/acc efforts in importance if we face an engineered pandemic before 2030.
- Reduce the apocalyptic residual: ?????
I cannot think of a single person or paper working on managing the apocalyptic residual (number of people who would want to destroy the world and have enough agency to try to do so) recently.
Bostrom calls this "preference modification" and argues it is infeasible. Here are relevant quotes from the VWH paper:
It is difficult to imagine an intervention – short of radically re-engineering human nature on a fully global scale – that would sufficiently deplete the apocalyptic residual to entirely eliminate or even greatly reduce the threat of Type-1 vulnerabilities.
"Radically re-engineering human nature on a fully global scale" seems unrealistic until we realize we're about to do totally realistic things such as "automate all remote work" on the same timeframe; that technology is re-engineering human nature on a global scale; and that many people's lives are increasingly a side quest to their main task of being fed video content from variously sized screens. Status-disaffected men used to go to war or become cult leaders or something; soon they will all waste their lives on video games, their attention on short-form video feeds, their salaries on parlay bets on Robinhood or parasocial relationships with OnlyFans models; living their lives vicariously through the Content they consume and egregores that control their brain. If the forces of technocapital can coordinate to do anything, they can coordinate on preference modification of every monetizable eyeball they can reach, to make their lives as inane and inconsequential and as glued to the screen as possible.
Now, of course, the timelines of preference modification and dangerous technology might not match. Market forces might only drain the agency of a fraction of the relevant population by the critical period. But it's worth thinking about ways in which the impact of AGI actually expands society's toolset to fight x-risk.
Four views of AI automation: model, researcher, lab, economy
Every serious AI lab wants to automate themselves. I believe this sentence to hold predictive power over AI timelines and all other predictions about the future. In particular, I believe taking the AI-lab-centric view is the right way to think about automation.
In this post, I want to present the different levels of abstraction at which AI automation can be thought of:
- Model: The model is being optimized by the lab. The right measure of acceleration is how much a model can autonomously do on tasks of a given purpose; ideally, research on future versions of itself. Examples of metrics are the METR time horizons study and OpenAI MLE-bench.
- Researcher: The researcher uses tools and builds automations to make the research process faster. The right measure of acceleration is the productivity of the researcher on their core tasks. (METR uplift study)
- AI lab: The lab trains models and hires researchers to be faster; allocates resources on bottlenecks; builds capabilities for external purposes to raise money and earn revenue; spends compute on external inference, internal inference, and training. (There are no public studies.)
- Economy: Researchers and practitioners share models, automations, ideas; the labs earn money; the overall pace of progress increases, or keeps pace in case the technical problems become more difficult to solve. (GDP proxies, automation studies)
All views except the lab view have important drawbacks:
- Model: as of 2025, the abilities of the model to do AI R&D do not imply that much about the future capabilities of the model, because many other things influence model capabilities; it's not a self-reinforcing loop. The model's capabilities do not directly translate to future model capabilities.
- Researcher: Again, a researcher's work is not self-reinforcing; the researcher's productivity results in general model capabilities. This only rarely feeds back into their future productivity as a first-order effect. Researchers do work on their own automation; but this is a smaller fraction of their time.
- Economy: society-wide metrics depend a lot on the capabilities that are not directly accelerating model R&D. Of course, higher total productivity does accelerate the compute buildup and hence AI progress at large; but this is a second-order effect. Additionally, society is ruled by democratic and other slow-moving institutions that have a difficult time optimizing for future productivity.
The AI lab is the unit with the most power over its own level of acceleration, because:
- Labs know where their bottlenecks are and can decide to train models to complement the researchers;
- Labs can record researcher actions and train models to do those actions;
- Improvements that the lab makes to its own productivity very directly translate to its future ability to do more of these productivity improvements;
- Labs benefit from scale (and hence can expend mental cycles to do proper allocation of resources towards productivity improvements);
- Labs benefit from power concentration (and can just make decisions to redirect resources towards productivity improvements);
The concepts of "AI lab" and "model" will get closer as time goes on
In the future, a larger and larger fraction of decisions inside the lab will get taken over by the model. This is due to two separate processes:
- imitation learning approaches to automation (existing activities done by people get optimized away to be done by the model).
- reinforcement learning on new tasks makes activities possible that were never actually done by people in the first place.
As we get closer to certain notions of AI self-improvement, the model will do actions to improve itself. For instance, in the end, most actions of Anthropic, internal or external, will be taken by Claude. In an efficient world where AI labs are aiming to automate AI R&D, "researcher" view goes away, and metrics tracking "model" and "AI lab" views start tracking the same thing.
AIs being bad at AI research says nothing about acceleration
Lots of people are trying to make AI good at AI research. How are they doing?
One way to measure this is to assume AIs are gradually doing more and more complex tasks independently. Eventually it would grow to doing whole research projects. Something like this, but for software engineering instead of research, is captured in the METR "time horizons" benchmark.
I think extending this line of thinking to forecasting progress in AI research is wrong. Instead, a better way to accelerate AI research for the time being is combining AI and people to do research together, in a way that uses the complementary strengths of each; with the goal of the researcher's feedback loops shortening.
What is difficult to automate in AI research?
If you decompose a big AI research project into tasks, there's lots of "dark matter" that does not neatly fit into any category. Some examples are given in Large-Scale Projects Stress Deep Cognitive Skills, which is a much better post than mine.
But I think that the most central argument is: the research process involves taste, coming up with ideas, and various such intangibles that we don't really know how to train for.
The labs are trying to make superhuman AI researchers. We do not yet know how to do it, which means at least some of our ideas are lacking. To improve our ideas, we need either:
- (the proper way) conceptual advances in machine learning;
- (the way it's actually going to get done) reinforcement learning on the idea->code->experiment->result process, to figure out which ideas are good.
Measuring which ideas are good is difficult; it requires sparse empirical outcomes that happen long after the idea is formulated. How can we accelerate this process?
I want to make two claims:
- There are large gains from accelerating AI researchers.
- Much more importantly, those gains are achievable without inventing new things in machine learning.
The careful reader might ask, ok, this sounds fine in the abstract, but I don't understand what exactly the lab is doing then, if not "automate AI research as a whole"? How is this different from making autonomous AI researchers directly?
Here is a list of tasks that would be extremely valuable if we wanted to make the research feedback loops faster.
- implementing instructions of varying level of detail into code efficiently;
- extrapolating user intent and implementing the correct thing;
- relatedly: learning user intent from working with a researcher over time;
- given code, running experiments autonomously, fixing minor deployment issues;
- checking for bugs and suspicious logic in the code;
- observing and pinpointing anomalies in the data;
- monitoring experiments, reporting updates, and raising alarm when something is off; and so on.
I believe all of these tasks possess properties that make them attractive to attack directly.
- They consume a significant amount of time of a researcher (or add communication overhead if we add people focused on research engineering);
- There are clear ways to generate many datapoints + labels / reward functions for each of these tasks;
- Alternatively, these are done by people typing into a keyboard, so labs can do imitation learning by collecting all the human actions from their own researchers.
This seems easier than automating the full research process. If labs have the goal of speeding up the lab's ability to do AI research as opposed to other goals, they are probably doing these things; and measuring the ability of AIs to do research autonomously is not going to give a good grasp on how quickly the lab is accelerating.
Slow takeoff for AI R&D, fast takeoff for everything else
Why is AI progress so much more apparent in coding than everywhere else?
Among people who have "AGI timelines", most do not set their timelines based on data, but rather update them based on their own day-to-day experiences and social signals.
As of 2025, my guess is that individual perception of AI progress correlates with how closely someone's daily activities resemble how an AI researcher spends their time. The reason why users of coding agents feel a higher rate of automation in their bones, whereas people in most other occupations don't, is because automating engineering has been the focus of the industry for a while now. Despite the expectations for 2025 to be the year of the AI agent, it turns out the industry is small and cannot have too many priorities, hence basically the only competent agents we got in 2025 so far are coding agents.
Everyone serious about winning the AI race is trying to automate one job: AI R&D.
To a first approximation, there is no point yet in automating anything else, except to raise capital (human or investment), or to earn money. Until you are hitting diminishing returns on your rate of acceleration, unrelated capabilities are not a priority. This means that a lot of pressure is being applied to AI research tasks at all times; and that all delays in automation of AI R&D are, in a sense, real in a way that's not necessarily the case for tasks unrelated to AI R&D. It would be odd if there were easy gains to be made in accelerating the work of AI researchers on frontier models in addition to what is already being done across the industry.
I don't know whether automating AI research is going to be smooth all the way there or not; my understanding is that slow vs fast takeoff hinges significantly on how bottlenecked we become by non-R&D factors over time. Nonetheless, the above suggests a baseline expectation: AI research automation will advance more steadily compared to automation of other intellectual work.
For other tasks, especially for less immediately lucrative ones, it will make more sense to automate them quickly after we're done with automating AI research. Hence, a teacher's or a fiction writer's experience of automation will be somewhat more abrupt than a researcher's. In particular, I anticipate there will be a period of a year or two in which publicly available models are severely underelicited in tasks unrelated to AI R&D, as top talent is increasingly incentivized to work on capabilities that compound in R&D value.
This "differential automation" view naturally separates the history of AI capabilities into three phases:
- intentional, pre-scaling: we train the AI on a specific dataset, or even write the code for a specific task
- unintentional (2019-2023; scaling on broad data on the internet; AI improves across the board)
- intentional again: the AIs improve being finetuned on carefully sourced data, and RL environments
There will likely be another phase, after say a GPT-3 moment for RL, where RL is going to generalize somewhat further, and we will get gains on tasks that we do not directly train for; but I think the sheer amount of "unintentional" increase of capabilities across the board is less likely, because the remaining capabilities are inherently more specialized and unrelated to each other than they were in the pretraining scaling phase.
GPT-4o's drawings of itself as a person are remarkably consistent: it's more or less always a similar-looking white male in his late 20s with brown hair, often sporting facial hair and glasses, unless you specify otherwise. All the men it generates might as well be brothers. I reproduced this on two ChatGPT accounts with clean memory.
On the contrary, its drawings of itself when it does not depict itself as a person are far more diverse: a wide range of robot designs and abstract humanoids, often featuring OpenAI logo as a head or on the word "GPT" on the chest.
I think the labs might well be rational in focusing on this sort of "handheld automation", just to enable their researchers to code experiments faster and in smaller teams.
My mental model of AI R&D is that it can be bottlenecked roughly by three things: compute, engineering time, and the "dark matter" of taste and feedback loops on messy research results. I can certainly imagine a model of lab productivity where the best way to accelerate is improving handheld automation for the entirety of 2025. Say, the core paradigm is fixed; but inside that paradigm, the research team has more promising ideas than they have time to implement and try out on smaller-scale experiments; and they really do not want to hire more people.
If you consider the AI lab as a fundamental unit that wants to increase its velocity, and works on things that make models faster, it's plausible they can be aware how bad the model performance is on research taste, and still not be making a mistake by ignoring your "dark matter" right now. They will work on it when they are faster.
N = #params, D = #data
Training compute = const .* N * D
Forward pass cost (R bits) = c * N, and assume R = Ω(1) on average
Now, thinking purely information-theoretically:
Model stealing compute = C * fp16 * N / R ~ const. * c * N^2
If compute-optimal training and α = β in Chinchilla scaling law:
Model stealing compute ~ Training compute
For significantly overtrained models:
Model stealing << Training compute
Typically:
Total inference compute ~ Training compute
=> Model stealing << Total inference compute
Caveats:
- Prior on weights reduces stealing compute, same if you only want to recover some information about the model (e.g. to create an equally capable one)
- Of course, if the model is producing much fewer than 1 token per forward pass, then model stealing compute is very large
The one you linked doesn't really rhyme. The meter is quite consistently decasyllabic, though.
I find it interesting that the collection has a fairly large number of songs about World War II. Seems that the "oral songwriters composing war epics" meme lived until the very end of the tradition.
Here's on the Sonnet size class for now, nothing very interesting...