METR Research Update: Algorithmic vs. Holistic Evaluation
TL;DR * On 18 real tasks from two large open-source repositories, early-2025 AI agents often implement functionally correct code that cannot be easily used as-is, because of issues with test coverage, formatting/linting, or general code quality. * This suggests that automatic scoring used by many benchmarks may overestimate AI agent...
Aug 13, 2025101
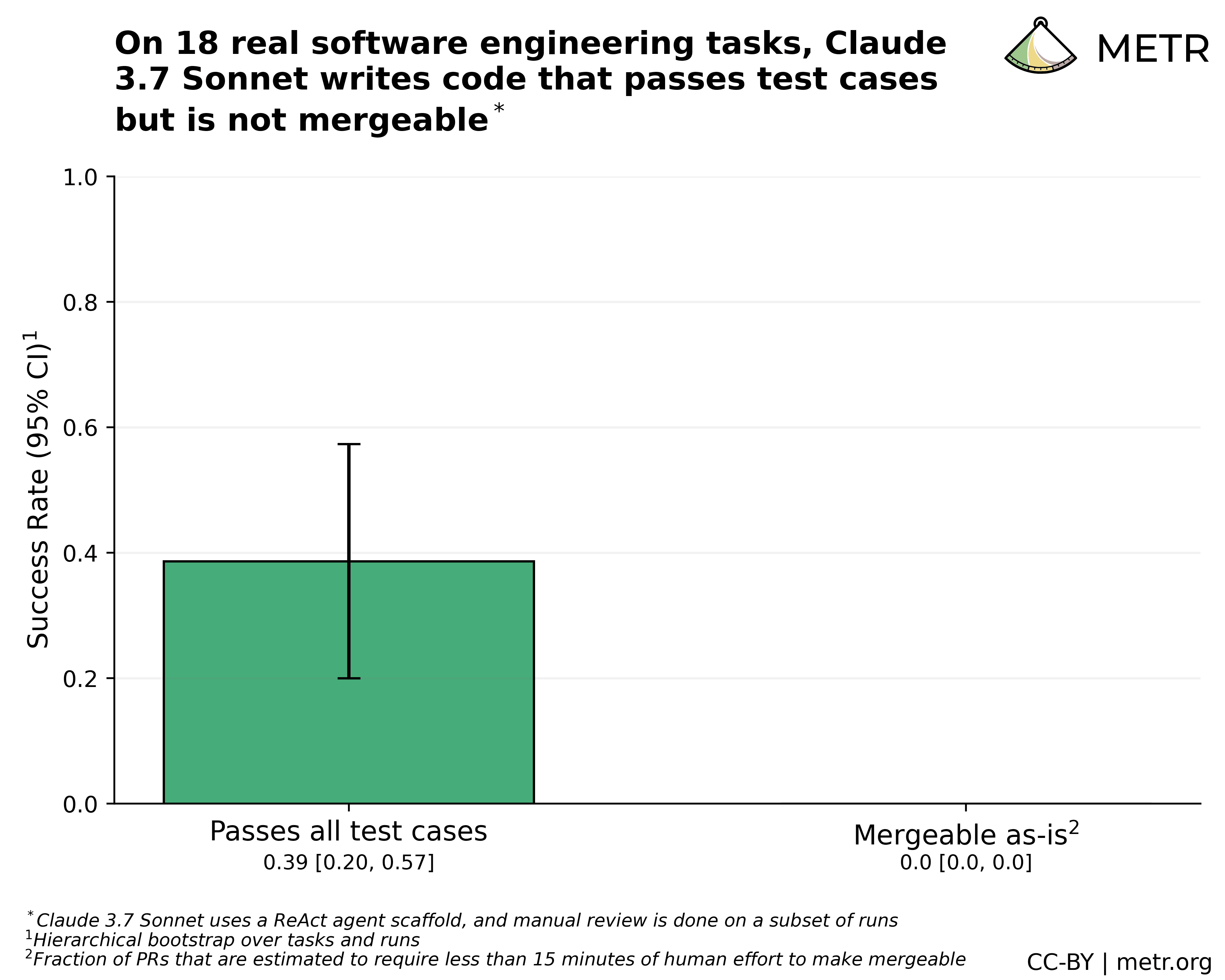
Important to caveat that these results are pretty small—I wouldn't take the absolute numbers too seriously beyond the general "algorithmic scoring may often overestimate software capabilities".