Great write-up. Inspired me to try how much further ICL could go beyond "simpler" mappings (OP shows pretty nice results for two linear and two quadratic functions). As such, I tried a damped sinusoid:
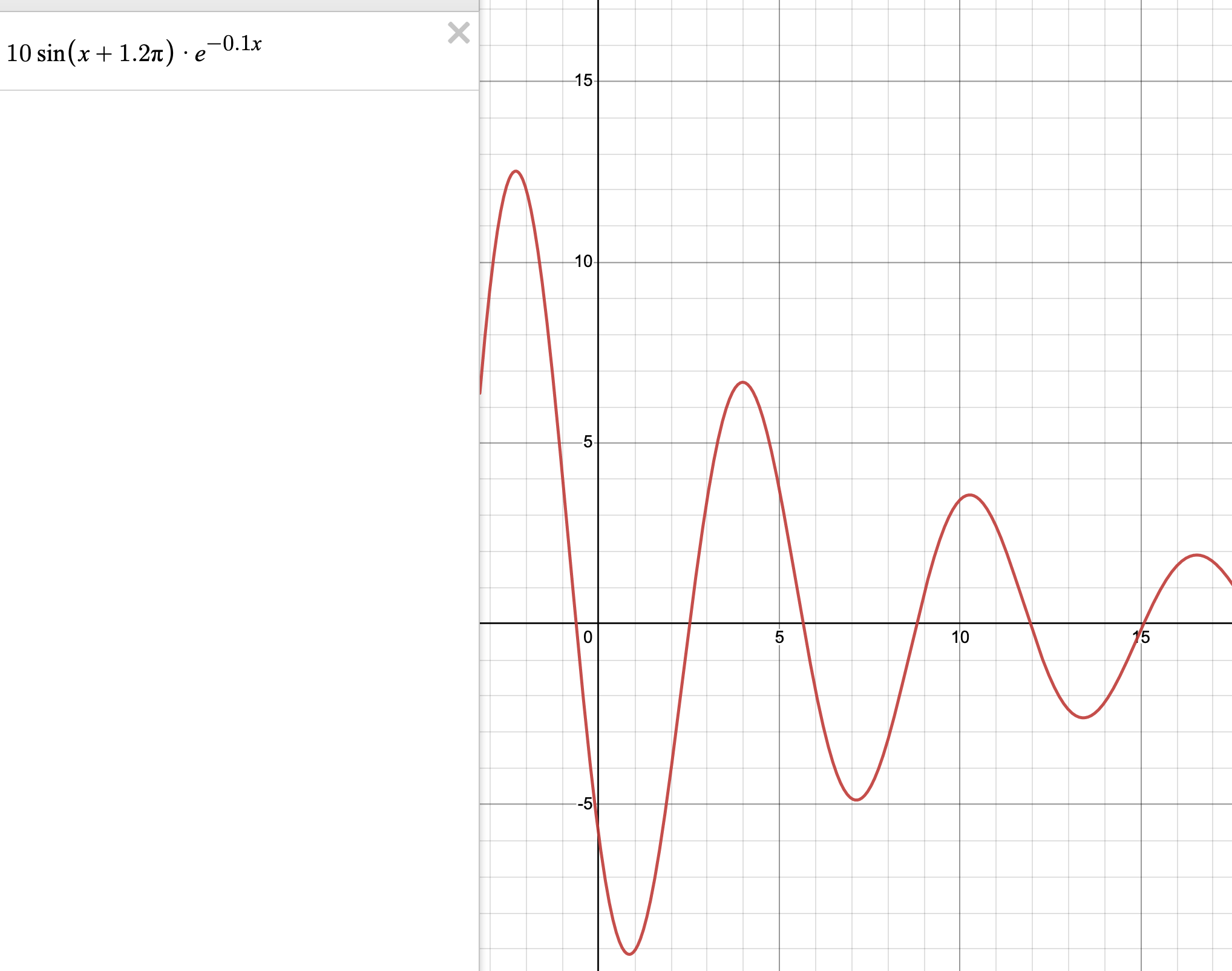
with the prompt:
x=3.984, y=6.68
x=2.197, y-2.497
x=0.26, y=-7.561
x=6.025, y=-1.98
x=7.126, y=-4.879
x=8.584, y=-0.894
x=9.97, y=3.403
x=11.1, y=2.45
x=12.09, y=-0.452
x=13.72, y=-2.48
x=14.81, y=-0.606
x=10, y=but didn't get any luck. Maybe I need more points, especially around the troughs and valleys.
Is Conjecture open to the idea of funding PhD fellowships for research in alignment and related topics? I think society will look back and see work in alignment as being very crucial in getting machines (which are growing impressively more intelligent quite quickly) to cooperate with humans.
Excited to hear that some at EleutherAI are working on alignment next (GPT-J & -Neo work were quite awesome).
I'm going slightly off-topic but couldn't help but notice that your website says that you're doing this in your spare time. I'm surprised that you've covered so much ground. If you don't mind me the question -- how do you keep abreast of the AI field with so many papers published every year? Like do you attend periodic meet-ups in your circle of friends/colleagues to discuss such matters? do you opt to read summaries of papers instead of the long paper?
It's all about mashing together compositional generative models. Like: "I need to put this book into my bag. Will it fit?" Well, you have a generative model of all the ways that the book can be oriented, and you have a generative model of all the ways that the bag can be reshaped and that its current contents can be shuffled around, and you try to mix and match all those models until you fit them together into a plausible composite model wherein the book slides easily into the bag. Then you reshape the bag, shuffle the contents, and orient the book, and it slides in, just like you imagined!
This reminds me of works like Capsule Network and Reinforcement Learning works that use imagination (e.g. learning how to drive a car in a game by imagining how upcoming roads curve, learning to dodge fireballs from enemies by imagining enemies shooting fireballs).
So that's why I'm not inclined to be part of the project to reverse-engineer the neocortex—not until we have a better plan for "what if we succeed
Regarding the threat of AGI — one perspective is that people accidentally stumble upon AGI architecture (perhaps a simple one, but nonetheless one), don’t recognize it because it’s capabilities are evaluated on narrow tasks (making it seem similar to traditional, narrow AI), is popularized (e.g. blogposts, academic papers) and distributed (e.g. github), and eager, well-meaning folks try it and its improved variants in increasingly realistic environments (access to websites, social media, embodied in a robot waiter), and suddenly realize… hey… this thing is learning things we did not quite expect. I mean, we did expect it to learn, especially to mimic material it’s exposed to, but not these action sequences that seem superfluous at first but yield surprisingly meaningful outcomes. Real-world example: see footnote. Generally speaking, reward-driven agents that have to figure out what actions to take have this potential.
One way to prevent the above scenario from accidentally happening is to map models, prioritizing the popular and proven models, to known cognitive functions. Such knowledge lets us estimate the scope of cognitive functions mirrored by a given model pipeline. An informative side-effect of this is that we might come to realize that not all features of our own (human) cognition are necessary for AGI — as an example, the absence of the pre-, sub-, & fully- conscious distinction has [EDIT: might have] trivial effects on AGI.
It’d be helpful in the near future for there to be voices that can warn when models come dangerously close to forming a set of cognitive functions minimally required for a basic AGI. Admittedly, historically, AGI predictions aren’t exactly known for being prescient, but communities at least get an informed warning.
Footnote:
Go experts were impressed by the program's performance and its nonhuman play style; Ke Jie stated that "After humanity spent thousands of years improving our tactics, computers tell us that humans are completely wrong... I would go as far as to say not a single human has touched the edge of the truth of Go."
Its strategy of maximising its probability of winning is distinct from what human players tend to do which is to maximise territorial gains, and explains some of its odd-looking moves. It makes a lot of opening moves that have never or seldom been made by humans, while avoiding many second-line opening moves that human players like to make. It likes to use shoulder hits, especially if the opponent is over concentrated.
- source https://en.wikipedia.org/wiki/AlphaGo
My comment: A concrete example is “move 37” by alphago, a move typically eschewed by human players due to intuition passed on through the ages.
The South Korean Go champion Lee Se-dol has retired from professional play…
“With the debut of AI in Go games, I’ve realized that I’m not at the top even if I become the number one through frantic efforts,” Lee told Yonhap. “Even if I become the number one, there is an entity that cannot be defeated.”
Lee lost 4-1 to DeepMind’s AlphaGo in 2016.For years, Go was considered beyond the reach of even the most sophisticated computer programs. The ancient board game is famously complex, with more possible configurations for pieces than atoms in the observable universe.
…
“Even with a two-stone advantage, I feel like I will lose the first game to HanDol [a Korean AI program],” Lee told Yonhap. “These days, I don’t follow Go news ...”
- source https://www.theverge.com/2019/11/27/20985260/ai-go-alphago-lee-se-dol-retired-deepmind-defeat
Yes, I also think that memory and generative models could be “different forms” of the same thing. A generative model seems like compressed memory. Perhaps memory to a biological organism could be like short-term memory (representations being focused on (attention) and recent history. Contents readily retrievable). And generative models to a biological organism could be like long-term memory (effort needed in retrieving compressed contents). However, a machine with large memory capacities might have less need of generative models solely for the sake of memory compression. Engineers might still elect generative models to be implemented for the sake of creating new memories (e.g. GANs to merge concepts together to form a new memory). This might help in creativity — obtaining a new memory from mashing together two or more previously acquired memories.
Yes, I too, don’t think it’s natural to describe a deconv NN as implicitly encoding a knowledge graph. Mentioned knowledge graph as an example.
Having brought up Dileep George’s and Randall O Reilly’s work in your posts, would you happen to have had the time to try out the code (Reilly’s work is on github) and have comments/feedback?
At work I encounter deconv NNs more frequently even for topics like predictive coding, curiosity, etc.. Would you happen to have encountered alternative models (other than Dileep George’s) that are amenable to someone wanting to take baby steps into the AGI community?
For the interested reader, I came across a video of Dileep George talking about RCN:
Thanks for writing back.
I asked about the memory and generative models because I feel uncertain about the differences, if any, between storing information in memory versus storing in generative models. Example of storing in memory would be something like a knowledge graph. Example of retrieving info from a generative model would be something like inputing a vector into deconvolutional NN so that it outputs an image (models have capacity making them function like memory). One question on my mind is, are there things that are better suited (or “more naturally”) stored in a generative model versus in memory.
Good day Steve,
This post says, “Since generative models are simpler (less information content) than reverse / discriminative models, they can be learned more quickly.” Is this true? I’ve always had the impression that it’s the opposite. It’s easier to tell the apart, say, cats and dogs (discriminative model) than it is to draw cats and dogs (generative model). Most children first learn to discriminate between different objects before learning how to draw/create/generate them.
Would you have an opinion of how memory and generative models interact? To jog the discussion, I’d like to bring up Kaj_Sotala’s hypothesis that, “Type 2 processing is a particular way of chaining together the outputs of various Type 1 subagents using working memory.” [1]. Type 1 subagents here is (I think) similar to Society of Mind. Type 2 processing is the, informally speaking, more deliberate, abstract, and memory-intensive, of the two types of processing.
This post and [1] list tasks that require type 2 processing to solve. Are there contrived (& hopefully simple) tasks that are available to be run on computers to test the performance of implementations that aim to conduct type 2 processing?
[1] Kaj_Sotala, System 2 as working-memory augmented System 1 reasoning. https://www.lesswrong.com/posts/HbXXd2givHBBLxr3d/against-system-1-and-system-2-subagent-sequence
>This type of paper reading, where I gather tools to engineer with, initially seems less relevant for fundamental concepts research like alignment. However, your general relativity example suggests that Einstein also had a tool gathering phase leading up to relativity, so shrugs.
As an advisor used to remark that working on applications can lead to directions related to more fundamental research. How it can happen is something like this: 1. Try to apply method to domain; 2. Realize shortcomings of method; 3. Find & attempt solutions to address shortcoming; 4. If shortcoming isn't well-addressed or has room for improvement despite step 3 then you _might_ have a fundamental problem on hand. Note that while this provides direction, it doesn't guarantee that the direction is a one that is solve-able in the next t months.