All of plex's Comments + Replies
Podcast version:
The new Moore's Law for AI Agents (aka More's Law) has accelerated at around the time people in research roles started to talk a lot more about getting value from AI coding assistants. AI accelerating AI research seems like the obvious interpretation, and if true, the new exponential is here to stay. This gets us to 8 hour AIs in ~March 2026, and 1 month AIs around mid 2027.[1]
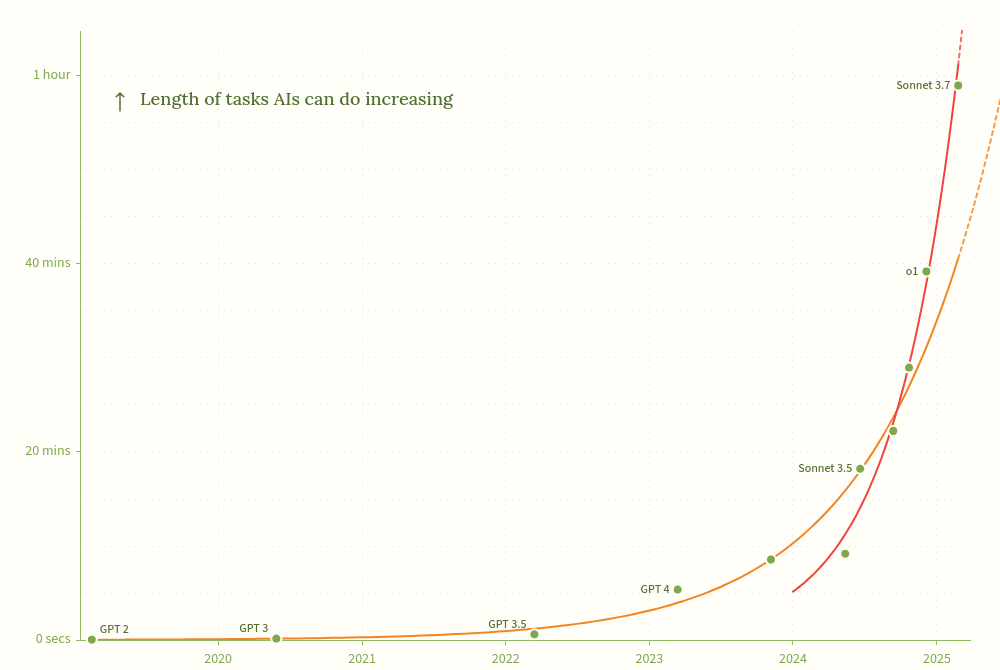
I do not expect humanity to retain relevant steering power for long in a world with one-month AIs. If we haven't solved alignment, either iteratively or once-and-for-all[2], it's loo...
Nice! I think you might find my draft on Dynamics of Healthy Systems: Control vs Opening relevant to these explorations, feel free to skim as it's longer than ideal (hence unpublished, despite containing what feels like a general and important insight that applies to agency at many scales). I plan to write a cleaner one sometime, but for now it's claude-assisted writing up my ideas, so it's about 2-3x more wordy than it should be.
Interesting, yes. I think I see, and I think I disagree with this extreme formulation, despite knowing that this is remarkably often a good direction to go in. If "[if and only if]" was replaced with "especially", I would agree, as I think the continual/regular release process is an amplifier on progress not a full requisite.
As for re-forming, yes, I do expect there is a true pattern we are within, which can be in its full specification known, though all the consequences of that specification would only fit into a universe. I think having fluidity on as ma...
I'd love to see the reading time listed on the frontpage. That would make the incentives naturally slide towards shorter posts, as more people would click and it would get more karma. Feels much more decision relevant than when the post was posted.
Yup, DMing for context!
hmmm, I'm wondering if you're pointing at something different from the thing in this space which I intuitively expect is good using words that sound more extreme than I'd use, or whether you're pointing at a different thing. I'll take a shot at describing the thing I'd be happy with of this type and you can let me know whether this feels like the thing you're trying to point to:
...An ontology restricts the shape of thought by being of a set shape. All of them are insufficient, the Tao that can be specified is not the true Tao, but each
you could engage with the Survival and Flourishing Fund
Yeah! The S-process is pretty neat, buying into that might be a great idea once you're ready to donate more.
Elaborating Plex's idea: I imagine you might be able to buy into participation as an SFF speculation granter with $400k. Upsides:
(a) Can see a bunch of people who're applying to do things they claim will help with AI safety;
(b) Can talk to ones you're interested in, as a potential funder;
(c) Can see discussion among the (small dozens?) of people who can fund SFF speculation grants, see what people are saying they're funding and why, ask questions, etc.
So it might be a good way to get the lay of the land, find lots of people and groups, hear peoples' responses to some of your takes and see if their responses make sense on your inside view, etc.
Consider reaching out to Rob Miles.
He tends to get far more emails than he can handle so a cold contact might not work, but I can bump this up his list if you're interested.
Firstly: Nice, glad to have another competent and well-resourced person on-board. Welcome to the effort.
I suggest: Take some time to form reasonably deep models of the landscape, first technical[1] and then the major actors and how they're interfacing with the challenge.[2] This will inform your strategy going forward. Most people, even people who are full time in AI safety, seem to not have super deep models (so don't let yourself be socially-memetically tugged by people who don't have clear models).
Being independently wealthy in this field is a...
eh, <5%? More that we might be able to get the AIs to do most of the heavy lifting of figuring this out, but that's a sliding scale of how much oversight the automated research systems need to not end up in wrong places.
My current guess as to Anthropic's effect:
- 0-8 months shorter timelines[1]
- Much better chances of a good end in worlds where superalignment doesn't require strong technical philosophy[2] (but I put very low odds on being in this world)
- Somewhat better chances of a good end in worlds where superalignment does require strong technical philosophy[3]
- ^
Shorter due to:
- There being a number of people who might otherwise not have been willing to work for a scaling lab, or not do so as enthusiastically/effectively (~55% weight)
- Encouraging race dynamics (~30%)
- Making
By "discard", do you mean remove specifically the fixed-ness in your ontology such that the cognition as a whole can move fluidly and the aspects of those models which don't integrate with your wider system can dissolve, as opposed to the alternate interpretation where "discard" means actively root out and try and remove the concept itself (rather than the fixed-ness of it)?
(also 👋, long time no see, glad you're doing well)
I had a similar experience a couple years back when running bio anchors with numbers which seemed more reasonable/less consistently slanted towards longer timelines to me, getting:
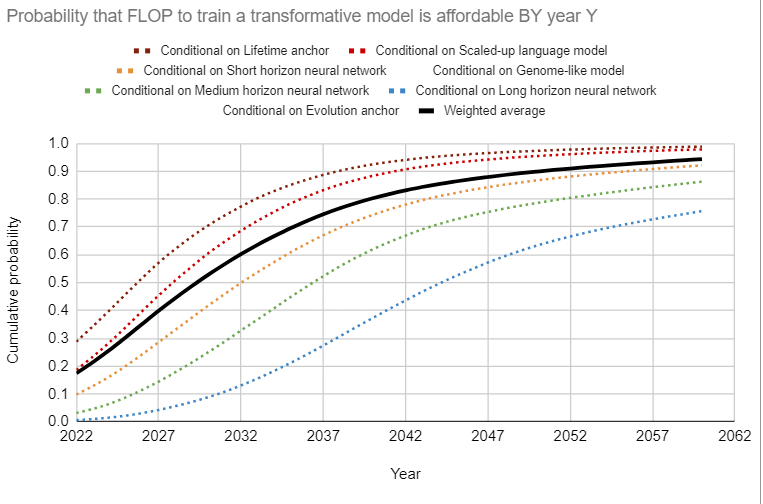
before taking into account AI accelerating AI development, which I expected to bring it a few years earlier.
Also I suggest that given the number of tags in each section, load more should be load all.
This is awesome! Three comments:
- Please make an easy to find Recent Changes feed (maybe a thing on the home page which only appears if you've made wiki edits). If you want an editor community, that will be their home, and the thing they're keeping up with and knowing to positively reinforce each other.
- The concepts portal is now a slightly awkward mix of articles and tags, with potentially very high use tags being quite buried because no one's written a good article for it (e.g Rationality Quotes has 136 pages tagged, but zero karma, so requires many clicks
I've heard from people I trust that:
- They can be pretty great, if you know what you want and set the prompt up right
- They won't be as skilled as a human therapist, and might throw you in at the deep end or not be tracking things a human would
Using them can be very worth it as they're always available and cheap, but they require a little intentionality. I suggest asking your human therapist for a few suggestions of kinda of work you might do with a peer or LLM assistant, and monitoring how it affects you while exploring, if you feel safe enough doing that. Ma...

oh yup, sorry, I meant mid 2026, like ~6 months before the primary proper starts. But could be earlier.
Yeah, this seems worth a shot. If we do this, we should do our own pre-primary in like mid 2027 to select who to run in each party, so that we don't split the vote and also so that we select the best candidate.
Someone I know was involved in a DIY pre-primary in the UK which unseated an extremely safe politician, and we'd get a bunch of extra press while doing this.
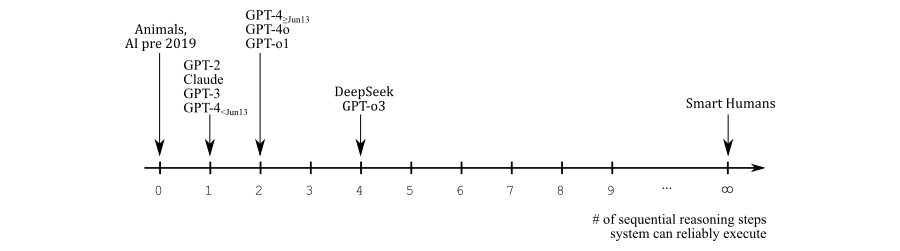
Humans without scaffolding can do a very finite number of sequential reasoning steps without mistakes. That's why thinking aids like paper, whiteboards, and other people to bounce ideas off and keep the cache fresh are so useful.
With a large enough decisive strategic advantage, a system can afford to run safety checks on any future versions of itself and anything else it's interacting with sufficient to stabilize values for extremely long periods of time.
Multipolar worlds though? Yeah, they're going to get eaten by evolution/moloch/power seeking/pythia.
More cynical take based on the Musk/Altman emails: Altman was expecting Musk to be CEO. He set up a governance structure which would effectively be able to dethrone Musk, with him as the obvious successor, and was happy to staff the board with ideological people who might well take issue with something Musk did down the line to give him a shot at the throne.
Musk walked away, and it would've been too weird to change his mind on the governance structure. Altman thought this trap wouldn't fire with high enough probability to disarm it at any time before it di...
Looks fun!
I could also remove Oil Seeker's protection from Pollution; they don't need it for making Black Chips to be worthwhile for them but it makes that less of an amazing deal than it is.
Maybe have the pollution cost halved for Black, if removing it turns out to be too weak?
Seems accurate, though I think Thinking This Through A Bit involved the part of backchaining where you look at approximately where on the map the destination is, and that's what some pro-backchain people are trying to point at. In the non-metaphor, the destination is not well specified by people in most categories, and might be like 50 ft in the air so you need a way to go up or something.
And maybe if you are assisting someone else who has well grounded models, you might be able to subproblem solve within their plan and do good, but you're betting your imp...
Give me a dojo.lesswrong.com, where the people into mental self-improvement can hang out and swap techniques, maybe a meetup.lesswrong.com where I can run better meetups and find out about the best rationalist get-togethers. Let there be an ai.lesswrong.com for the people writing about artificial intelligence.
Yes! Ish! I'd be keen to have something like this for the upcoming aisafety.com/stay-informed page, where we're looking like we'll currently resort to linking to https://www.lesswrong.com/tag/ai?sortedBy=magic#:~:text=Posts%20tagged%20AI as there's no...
I'm glad you're trying to figure out a solution. I am however going to shoot this one down a bunch.
If these assumptions were true, this would be nice. Unfortunately, I think all three are false.
LLMs will never be superintelligent when predicting a single token.
In a technical sense, definitively false. Redwood compared human to AI token prediction and even early AIs were far superhuman. Also, in a more important sense, you can apply a huge amount of optimization on selecting a token. This video gives a decent intuition, though in a slightly different settin...
the extent human civilization is human-aligned, most of the reason for the alignment is that humans are extremely useful to various social systems like the economy, and states, or as substrate of cultural evolution. When human cognition ceases to be useful, we should expect these systems to become less aligned, leading to human disempowerment.
oh good, I've been thinking this basically word for word for a while and had it in my backlog. Glad this is written up nicely, far better than I would likely have done :)
The one thing I'm not a big fan of: I'd bet "Gr...
I think I have a draft somewhere, but never finished it. tl;dr; Quantum lets you steal private keys from public keys (so all wallets that have a send transaction). Upgrading can protect wallets where people move their coins, but it's going to be messy, slow, and won't work for lost-key wallets, which are a pretty huge fraction of the total BTC reserve. Once we get quantum BTC at least is going to have a very bad time, others will have a moderately bad time depending on how early they upgrade.
Nice! I haven't read a ton of Buddhism, cool that this fits into a known framework.
I'm uncertain of how you use the word consciousness here do you mean our blob of sensory experience or something else?
Yeah, ~subjective experience.
Let's do most of this via the much higher bandwidth medium of voice, but quickly:
- Yes, qualia[1] is real, and is a class of mathematical structure.[2]
- (placeholder for not a question item)
- Matter is a class of math which is ~kinda like our physics.
- Our part of the multiverse probably doesn't have special "exists" tags, probably everything is real (though to get remotely sane answers you need a decreasing reality fluid/caring fluid allocation).
Math, in the sense I'm trying to point to it, is 'Structure'. By which I mean: Well defined seeds/axioms/starting
give up large chunks of the planet to an ASI to prevent that
I know this isn't your main point but.. That isn't a kind of trade that is plausible. Misaligned superintelligence disassembles the entire planet, sun, and everything it can reach. Biological life does not survive, outside of some weird edge cases like "samples to sell to alien superintelligences that like life". Nothing in the galaxy is safe.
Re: Ayahuasca from the ACX survey having effects like:
- “Obliterated my atheism, inverted my world view no longer believe matter is base substrate believe consciousness is, no longer fear death, non duality seems obvious to me now.”
[1]There's a cluster of subcultures that consistently drift toward philosophical idealist metaphysics (consciousness, not matter or math, as fundamental to reality): McKenna-style psychonauts, Silicon Valley Buddhist circles, neo-occultist movements, certain transhumanist branches, quantum consciousness theorists, and variou...
This suggests something profound about metaphysics itself: Our basic intuitions about what's fundamental to reality (whether materialist OR idealist) might be more about human neural architecture than about ultimate reality. It's like a TV malfunctioning in a way that produces the message "TV isn't real, only signals are real!"
In meditation, this is the fundamental insight, the so called non-dual view. Neither are you the fundamental non-self nor are you the specific self that you yourself believe in, you're neither, they're all empty views, yet that view ...
We do not take a position on the likelihood of loss of control.
This seems worth taking a position on, the relevant people need to hear from the experts an unfiltered stance of "this is a real and perhaps very likely risk".
Agree that takeoff speeds are more important, and expect that FrontierMath has much less affect on takeoff speed. Still think timelines matter enough that the amount of relevantly informing people that you buy from this is likely not worth the cost, especially if the org is avoiding talking about risks in public and leadership isn't focused on agentic takeover, so the info is not packaged with the info needed for that info to have the effects which would help.
Evaluating the final model tells you where you got to. Evaluating many small models and checkpoints helps you get further faster.
Even outside of the arguing against the Control paradigm, this post (esp. The Model & The Problem & The Median Doom-Path: Slop, not Scheming) cover some really important ideas, which I think people working on many empirical alignment agendas would benefit from being aware of.
One neat thing I've explored is learning about new therapeutic techniques by dropping a whole book into context and asking for guiding phrases. Most therapy books do a lot of covering general principles of minds and how to work with them, with the unique aspects buried in a way which is not super efficient for someone who already has the universal ideas. Getting guiding phrases gives a good starting point for what the specific shape of a technique is, and means you can kinda use it pretty quickly. My project system prompt is:
...Given the name of, and potentia
I'm guessing you view having better understanding of what's coming as very high value, enough that burning some runway is acceptable? I could see that model (though put <15% on it), but I think this is at least not good integrity wise to have put on the appearance of doing just the good for x-risk part and not sharing it as an optimizable benchmark, while being funded by and giving the data to people who will use it for capability advancements.
Evaluation on demand because they can run them intensely lets them test small models for architecture improvements. This is where the vast majority of the capability gain is.
Getting an evaluation of each final model is going to be way less useful for the research cycle, as it only gives a final score, not a metric which is part of the feedback loop.
However, we have a verbal agreement that these materials will not be used in model training.
If by this you mean "OpenAI will not train on this data", that doesn't address the vast majority of the concern. If OpenAI is evaluating the model against the data, they will be able to more effectively optimize for capabilities advancement, and that's a betrayal of the trust of the people who worked on this with the understanding that it will be used only outside of the research loop to check for dangerous advancements. And, particularly, not to make those da...
Really high quality high-difficulty benchmarks are much more scarce and important for capabilities advancing than just training data. Having an apparently x-risk focused org do a benchmark implying it's for evaluating danger from highly capable models in a way which the capabilities orgs can't use to test their models, then having it turn out that's secretly funded by OpenAI with OpenAI getting access to most of the data is very sketchy.
Some people who contributed questions likely thought they would be reducing x-risk by helping build bright line warning s...
This is a good idea usually, but critically important when using skills like those described in Listening to Wisdom, in a therapeutic relationship (including many forms of coaching), or while under the influence of substances that increase your rate of cognitive change and lower barriers to information inflow (such as psychedelics).
If you're opening yourself up to receive the content of those vibes on an emotional/embodied/deep way, and those vibes are bad, this can be toxic to an extent you will not be expecting (even if you try to account for this warnin...
Maybe having exact evaluations not being trivial is not entirely a bug, but might make the game more interesting (though maybe more annoying)?
I recommend most readers skip this subsection on a first read; it’s not very central to explaining the alignment problem.
Suggest either putting this kind of aside in a footnote, or giving the reader a handy link to the next section for convenience?
Nice!
(I wrote the bit about not having to tell people your favourite suit or what cards you have leaves things open for some sharp or clever negotiation, but looking back I think it's mostly a trap. I haven't seen anyone get things to go better for them by hiding the suit.)
To add some layer of this strategy: Giving each person one specific card on their suit that they want with much higher strength might be fun, as the other players can ransom that card if they know (but might be happy trading it anyway). Also having the four suits each having a different multiplier might be fun?
On one side: Humanoid robots have much more density of parts requiring more machine-time than cars, probably slowing things a bunch.
On the other, you mention assuming no speed up due to the robots building robot factories, but this seems like the dominant factor in the growth. Your numbers excluding that are going to be way underestimating things pretty quickly without that. I'd be interested in what those numbers look like assuming reasonable guesses about robot workforce being part of a feedback cycle.
Or, worse, if most directions are net negative and you have to try quite hard to find one which is positive, almost everyone optimizing for magnitude will end up doing harm proportional to how much they optimize magnitude.
Accurate, and one of the main reasons why most current alignment efforts will fall apart with future systems. A generalized version of this combined with convergent power-seeking of learned patterns looks like the core mechanism of doom.