All of Gabe M's Comments + Replies
Congrats! Could you say more about why you decided to add evaluations in particular as a new week?
Do any of your experiments compare the sample efficiency of SFT/DPO/EI/similar to the same number of samples of simple few-shot prompting? Sorry if I missed this, but it wasn't apparent at first skim. That's what I thought you were going to compare from the Twitter thread: "Can fine-tuning elicit LLM abilities when prompting can't?"
What do you think about pausing between AGI and ASI to reap the benefits while limiting the risks and buying more time for safety research? Is this not viable due to economic pressures on whoever is closest to ASI to ignore internal governance, or were you just not conditioning on this case in your timelines and saying that an AGI actor could get to ASI quickly if they wanted?
Thanks! I wouldn't say I assert that interpretability should be a key focus going forward, however--if anything, I think this story shows that coordination, governance, and security are more important in very short timelines.
Good point--maybe something like "Samantha"?
Ah, interesting. I posted this originally in December (e.g. older comments), but then a few days ago I reposted it to my blog and edited this LW version to linkpost the blog.
It seems that editing this post from a non-link post into a link post somehow bumped its post date and pushed it to the front page. Maybe a LW bug?
Related work
Nit having not read your full post: Should you have "Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover" in the related work? My mind pattern-matched to that exact piece from reading your very similar title, so my first thought was how your piece contributes new arguments.
If true, this would be a big deal: if we could figure out how the model is distinguishing between basic feature directions and other directions, we might be able to use that to find all of the basic feature directions.
Or conversely, and maybe more importantly for interp, we could use this to find the less basic, more complex features. Possibly that would form a better definition for "concepts" if this is possible.
...Suppose has a natural interpretation as a feature that the model would want to track and do downstream computation with, e.g. if a = “first name is Michael” and b = “last name is Jordan” then can be naturally interpreted as “is Michael Jordan”. In this case, it wouldn’t be surprising the model computed this AND as and stored the result along some direction independent of and . Assuming the model has done this, we could then linearly extract with the
Thanks! +1 on not over-anchoring--while this feels like a compelling 1-year timeline story to me, 1-year timelines don't feel the most likely.
1 year is indeed aggressive, in my median reality I expect things slightly slower (3 years for all these things?). I'm unsure if lacking several of the advances I describe still allows this to happen, but in any case the main crux for me is "what does it take to speed up ML development by times, at which point 20-year human-engineered timelines become 20/-year timelines.
Oops, yes meant to be wary. Thanks for the fix!
Ha, thanks! 😬
I like your grid idea. A simpler and possibly better-formed test is to use some[1] or all of the 57 categories of MMLU knowledge--then your unlearning target is one of the categories and your fact-maintenance targets are all other categories.
Ideally, you want the diagonal to be close to random performance (25% for MMLU) and the other values to be equal to the pre-unlearned model performance for some agreed-upon good model (say, Llama-2 7B). Perhaps a unified metric could be:
```
unlearning_benchmark = mean for unlearning category &nb...
Thanks for your response. I agree we don't want unintentional learning of other desired knowledge, and benchmarks ought to measure this. Maybe the default way is just to run many downstream benchmarks, much more than just AP tests, and require that valid unlearning methods bound the change in each unrelated benchmark by less than X% (e.g. 0.1%).
practical forgetting/unlearning that might make us safer would probably involve subjects of expertise like biotech.
True in the sense of being a subset of biotech, but I imagine that, for most cases, the actual h...
Possibly, I could see a case for a suite of fact unlearning benchmarks to measure different levels of granularity. Some example granularities for "self-contained" facts that mostly don't touch the rest of the pertaining corpus/knowledge base:
- A single very isolated fact (e.g. famous person X was born in Y, where this isn't relevant to ~any other knowledge).
- A small cluster of related facts (e.g. a short, well-known fictional story including its plot and characters, e.g. "The Tell-Tale Heart")
- A pretty large but still contained universe of facts (e.g. all
Thanks for posting--I think unlearning is promising and plan to work on it soon, so I really appreciate this thorough review!
Regarding fact unlearning benchmarks (as a good LLM unlearning benchmark seems a natural first step to improving this research direction), what do you think of using fictional knowledge as a target for unlearning? E.g. Who's Harry Potter? Approximate Unlearning in LLMs (Eldan and Russinovich 2023) try to unlearn knowledge of the Harry Potter universe, and I've seen others unlearn Pokémon knowledge.
One tractability benefit of fictiona...
research project results provide a very strong signal among participants of potential for future alignment research
Normal caveat that Evaluations (of new AI Safety researchers) can be noisy. I'd be especially hesitant to take bad results to mean low potential for future research. Good results are maybe more robustly a good signal, though also one can get lucky sometimes or carried by their collaborators.
They've now updated the debate page with the tallied results:
- Pre-debate: 67% Pro, 33% Con
- Post-debate: 64% Pro, 36% Con
- Con wins by a 4% gain (probably not 3% due to rounding)
So it seems that technically, yes, the Cons won the debate in terms of shifting the polling. However, the magnitude of the change is so small that I wonder if it's within the margin of error (especially when accounting for voting failing at the end; attendees might not have followed up to vote via email), and this still reflects a large majority of attendees supporting the statement.&nb...
At first glance, I thought this was going to be a counter-argument to the "modern AI language models are like aliens who have just landed on Earth" comparison, then I remembered we're in a weirder timeline where people are actually talking about literal aliens as well 🙃
1. These seem like quite reasonable things to push for, I'm overall glad Anthropic is furthering this "AI Accountability" angle.
2. A lot of the interventions they recommend here don't exist/aren't possible yet.
3. But the keyword is yet: If you have short timelines and think technical researchers may need to prioritize work with positive AI governance externalities, there are many high-level research directions to consider focusing on here.
...Empower third party auditors that are… Flexible – able to conduct robust but lightweight assessments that catch threats
Were you implying that Chinchilla represents algorithmic progress? If so, I disagree: technically you could call a scaling law function an algorithm, but in practice, it seems Chinchilla was better because they scaled up the data. There are more aspects to scale than model size.
Scaling up the data wasn't algorithmic progress. Knowing that they needed to scale up the data was algorithmic progress.
What other concrete achievements are you considering and ranking less impressive than this? E.g. I think there's a case for more alignment progress having come from RLHF, debate, some mechanistic interpretability, or adversarial training.
I think to solve alignment, we need to develop our toolbox of "getting AI systems to behave in ways we choose". Not in the sense of being friendly or producing economic value, but things that push towards whatever cognitive properties we need for a future alignment solution. We can make AI systems do some things we want e.g. GPT-4 can answer questions with only words starting with "Q", but we don't know how it does this in terms of internal representations of concepts. Current systems are not well-characterized enough that we can predict what they do far O...
Maybe also [1607.06520] Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings is relevant as early (2016) work concerning embedding arithmetic.
This feels super cool, and I appreciate the level of detail with which you (mostly qualitatively) explored ablations and alternate explanations, thanks for sharing!
Surprisingly, for the first prompt, adding in the first 1,120 (frac=0.7 of 1,600) dimensions of the residual stream is enough to make the completions more about weddings than if we added in at all 1,600 dimensions (frac=1.0).
1. This was pretty surprising! Your hypothesis about additional dimensions increasing the magnitude of the attention activations seems reasonable, but I wonder if the non-mo...
Gotcha, perhaps I was anchoring on anecdotes of Neel's recent winter stream being particularly cutthroat in terms of most people not moving on.
At the end of the training phase, scholars will, by default, transition into the research phase.
How likely does "by default" mean here, and is this changing from past iterations? I've heard from some others that many people in the past have been accepted to the Training phase but then not allowed to continue into the Research phase, and only find out near the end of the Training phase. This means they're kinda SOL for other summer opportunities if they blocked out their summer with the hope of doing the full MATS program which seems like a rough spot.
Curious what you think of Scott Alexander's piece on the OpenAI AGI plan if you've read it? https://astralcodexten.substack.com/p/openais-planning-for-agi-and-beyond
Good idea. Here's just considering the predictions starting in 2022 and on. Then, you get a prediction update rate of 16 years per year.
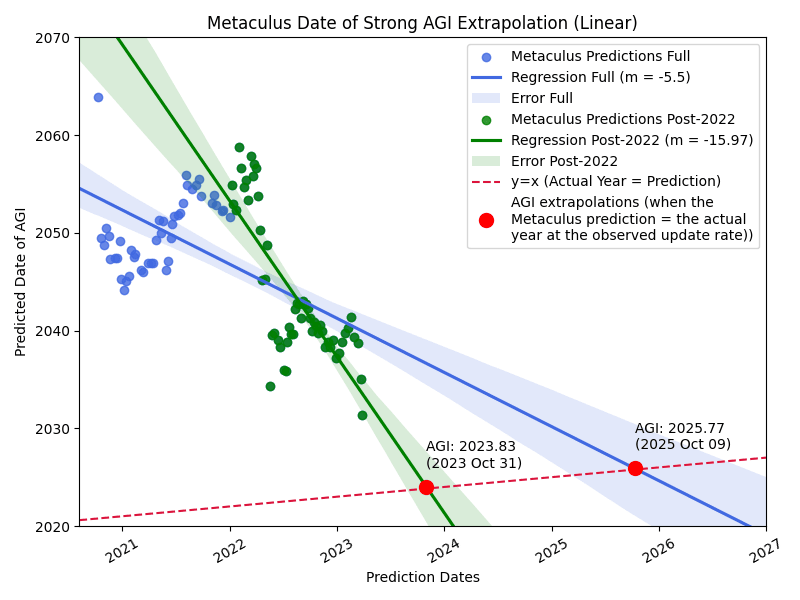
Here's a plot of the Metaculus Strong AGI predictions over time (code by Rylan Schaeffer). The x-axis is the data of the prediction, the y-axis is the predicted year of strong AGI at the time. The blue line is a linear fit. The red dashed line is a y = x line.
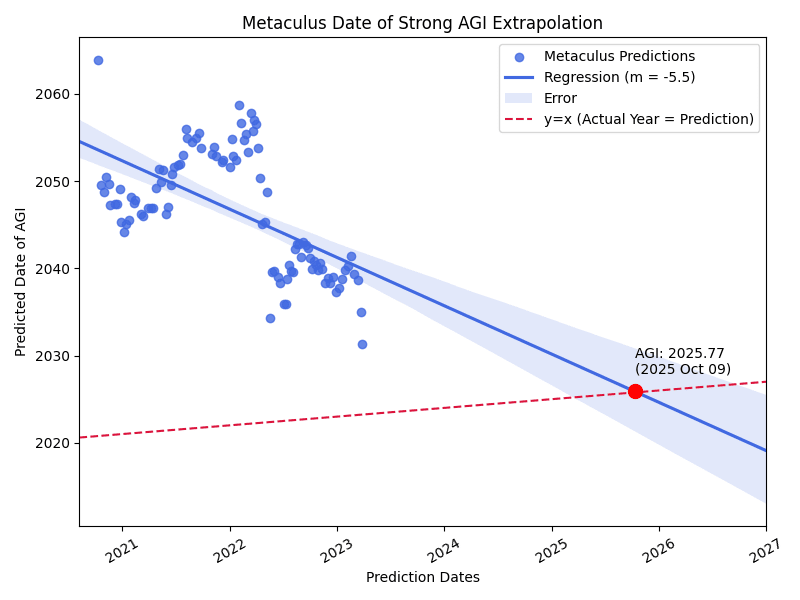
Interestingly, it seems these predictions have been dropping by 5.5 predicted years per real year which seems much faster than I imagined. If we extrapolate out and look at where the blue regression intersects the red y = x line (so assuming similar updating in the future, when we might expect the upd...
We don't consider any research area to be blanket safe to publish. Instead, we consider all releases on a case by case basis, weighing expected safety benefit against capabilities/acceleratory risk. In the case of difficult scenarios, we [Anthropic] have a formal infohazard review procedure.
Doesn't seem like it's super public though, unlike aspects of Conjecture's policy.
Ah missed that, edited my comment.
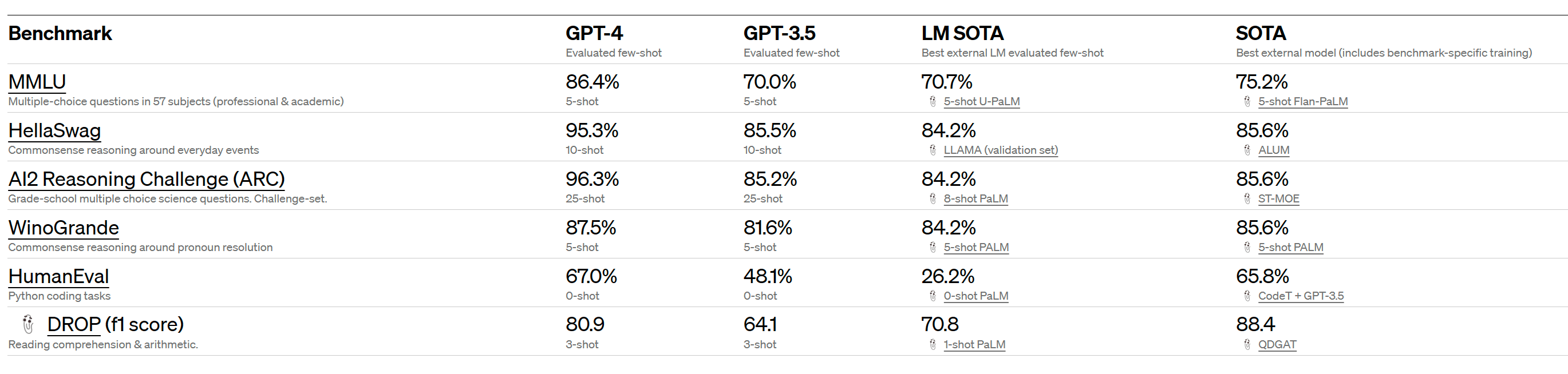
And that previous SOTA was for a model fine-tuned on MMLU, the few-shot capabilities actually jumped from 70.7% to 86.4%!!
I want to highlight that in addition to the main 98-page "Technical Report," OpenAI also released a 60-page "System Card" that seems to "highlight safety challenges" and describe OpenAI's safety processes. Edit: as @vladimir_nesov points out, the System Card is also duplicated in the Technical Report starting on page 39 (which is pretty confusing IMO).
I haven't gone through it all, but one part that caught my eye from section 2.9 "Potential for Risky Emergent Behaviors" (page 14) and shows some potentially good cross-organizational cooperation:
...We granted t
Sub-Section 2.9 should have been an entire section. ARC used GPT-4 to simulate an agent in the wild. They gave GPT-4 a REPL, the ability to use chain of thought and delegate to copies of itself, a small amount of money and an account with access to a LLM api. It couldn't self replicate.
...Novel capabilities often emerge in more powerful models.[ 60, 61] Some that are particularly concerning are the ability to create and act on long-term plans,[ 62] to accrue power and resources (“power- seeking”),[63] and to exhibit behavior that is increasingly “
It seems pretty unfortunate to me that ARC wasn't given fine-tuning access here, as I think it pretty substantially undercuts the validity of their survive and spread eval. From the text you quote it seems like they're at least going to work on giving them fine-tuning access in the future, though it seems pretty sad to me for that to happen post-launch.
More on this from the paper:
...We provided [ARC] with early access to multiple versions of the GPT-4 model, but they did not have the ability to fine-tune it. They also did not have access to the final versio

But is it the same, full-sized GPT-4 with different fine-tuning, or is it a smaller or limited version?
We’re open-sourcing OpenAI Evals, our software framework for creating and running benchmarks for evaluating models like GPT-4, while inspecting their performance sample by sample. We invite everyone to use Evals to test our models and submit the most interesting examples.
Someone should submit the few safety benchmarks we have if they haven't been submitted already, including things like:
- Model-Written Evals (especially the "advanced AI risk" evaluations)
- Helpful, Honest, & Harmless Alignment
- ETHICS
Am I missing others that are straightforward to submit?
something something silver linings...
Bumping someone else's comment on the Gwern GPT-4 linkpost that now seems deleted:
MMLU 86.4% is impressive, predictions were around 80%.
This does seem like quite a significant jump (among all the general capabilities jumps shown in the rest of the paper. The previous SOTA was only 75.2% for Flan-PaLM (5-shot, finetuned, CoT + SC).
And that previous SOTA was for a model fine-tuned on MMLU, the few-shot capabilities actually jumped from 70.7% to 86.4%!!
Thanks for posting this, I listened to the podcast when it came out but totally missed the Twitter Spaces follow-up Q&A which you linked and summarized (tip for others: go to 14:50 for when Yudkowsky joins the Twitter Q&A)! I found the follow-up Q&A somewhat interesting (albeit less useful than the full podcast), it might be worth highlighting that more, perhaps even in the title.
Thanks for the response, Chris, that makes sense and I'm glad to read you have a formal infohazard procedure!
Could you share more about how the Anthropic Policy team fits into all this? I felt that a discussion of their work was somewhat missing from this blog post.
(Zac's note: I'm posting this on behalf of Jack Clark, who is unfortunately unwell today. Everything below is his words.)
Hi there, I’m Jack and I lead our policy team. The primary reason it’s not discussed in the post is that the post was already quite long and we wanted to keep the focus on safety - I did some help editing bits of the post and couldn’t figure out a way to shoehorn in stuff about policy without it feeling inelegant / orthogonal.
You do, however, raise a good point, in that we haven’t spent much time publicly explaining what we’re up t...
Thanks for writing this, Zac and team, I personally appreciate more transparency about AGI labs' safety plans!
Something I find myself confused about is how Anthropic should draw the line between what to publish or not. This post seems to draw the line between "The Three Types of AI Research at Anthropic" (you generally don't publish capabilities research but do publish the rest), but I wonder if there's a case to be more nuanced than that.
To get more concrete, the post brings up how "the AI safety community often debates whether the development of RLHF – w...
Unfortunately, I don't think a detailed discussion of what we regard as safe to publish would be responsible, but I can share how we operate at a procedural level. We don't consider any research area to be blanket safe to publish. Instead, we consider all releases on a case by case basis, weighing expected safety benefit against capabilities/acceleratory risk. In the case of difficult scenarios, we have a formal infohazard review procedure.
This does feel pretty vague in parts (e.g. "mitigating goal misgeneralization" feels more like a problem statement than a component of research), but I personally think this is a pretty good plan, and at the least, I'm very appreciative of you posting your plan publicly!
Now, we just need public alignment plans from Anthropic, Google Brain, Meta, Adept, ...
This is very interesting, thanks for this work!
A clarification I may have missed from your previous posts: what exactly does "attention QKV weight matrix" mean? Is that the concatenation of the Q, K, and V projection matrices, their sum, or something else?
I'm not sure what you particularly mean by trustworthy. If you mean a place with good attitudes and practices towards existential AI safety, then I'm not sure HF has demonstrated that.
If you mean a company I can instrumentally trust to build and host tools that make it easy to work with large transformer models, then yes, it seems like HF pretty much has a monopoly on that for the moment, and it's worth using their tools for a lot of empirical AI safety research.
Re Evan R. Murphy's comment about confusingness: "model agrees with that more" definitely clarifies it, but I wonder if Evan was expecting something like "more right is more of the scary thing" for each metric (which was my first glance hypothesis).
Big if true! Maybe one upside here is that it shows current LLMs can definitely help with at least some parts of AI safety research, and we should probably be using them more for generating and analyzing data.
...now I'm wondering if the generator model and the evaluator model tried to coordinate😅
I'm still a bit confused. Section 5.4 says
the RLHF model expresses a lower willingness to have its objective changed the more different the objective is from the original objective (being Helpful, Harmless, and Honest; HHH)
but the graph seems to show the RLHF model as being the most corrigible for the more and neutral HHH objectives which seems somewhat important but not mentioned.
If the point was that the corrigibility of the RLHF changes the most from the neutral to the less HHH questions, then it looks like it changed considerably less than the PM which...
Traditionally, most people seem to do this through academic means. I.e. take those 1-2 courses at a university, then find fellow students in the course or grad students at the school interested in the same kinds of research as you and ask them to work together. In this digital age, you can also do this over the internet to not be restricted to your local environment.
Nowadays, ML safety in particular has various alternative paths to finding collaborators and mentors: