Interpreting and Steering Features in Images
We trained a SAE to find sparse features in image embeddings. We found many meaningful, interpretable, and steerable features. We find that steering image diffusion works surprisingly well and yields predictable and high-quality generations. You can see the feature library here. We also have an intervention playground you can try. Key Results * We can extract interpretable features from CLIP image embeddings. * We observe a diverse set of features, e.g. golden retrievers, there being two of something, image borders, nudity, and stylistic effects. * Editing features allows for conceptual and semantic changes while maintaining generation quality and coherency. * We devise a way to preview the causal impact of a feature, and show that many features have an explanation that is consistent with what they activate for and what they cause. * Many feature edits can be stacked to perform task-relevant operations, like transferring a subject, mixing in a specific property of a style, or removing something. Interactive demo * Visit the feature library of over ~50k features to explore the features we find. * Our main result, the intervention playground, is now available for public use. * The weights are open source -- here's a notebook to try an intervention. Introduction We trained a sparse autoencoder on 1.4 million image embeddings to find monosemantic features. In our run, we found 35% (58k) of the total of 163k features were alive, which is that they have a non-zero activation for any of the images in our dataset. We found that many features map to human interpretable concepts, like dog breeds, times of day, and emotions. Some express quantities, human relationships, and political activity. Others express more sophisticated relationships like organizations, groups of people, and pairs. Some features were also safety relevant.We found features for nudity, kink, and sickness and injury, which we won’t link here. Steering Features Previous work found

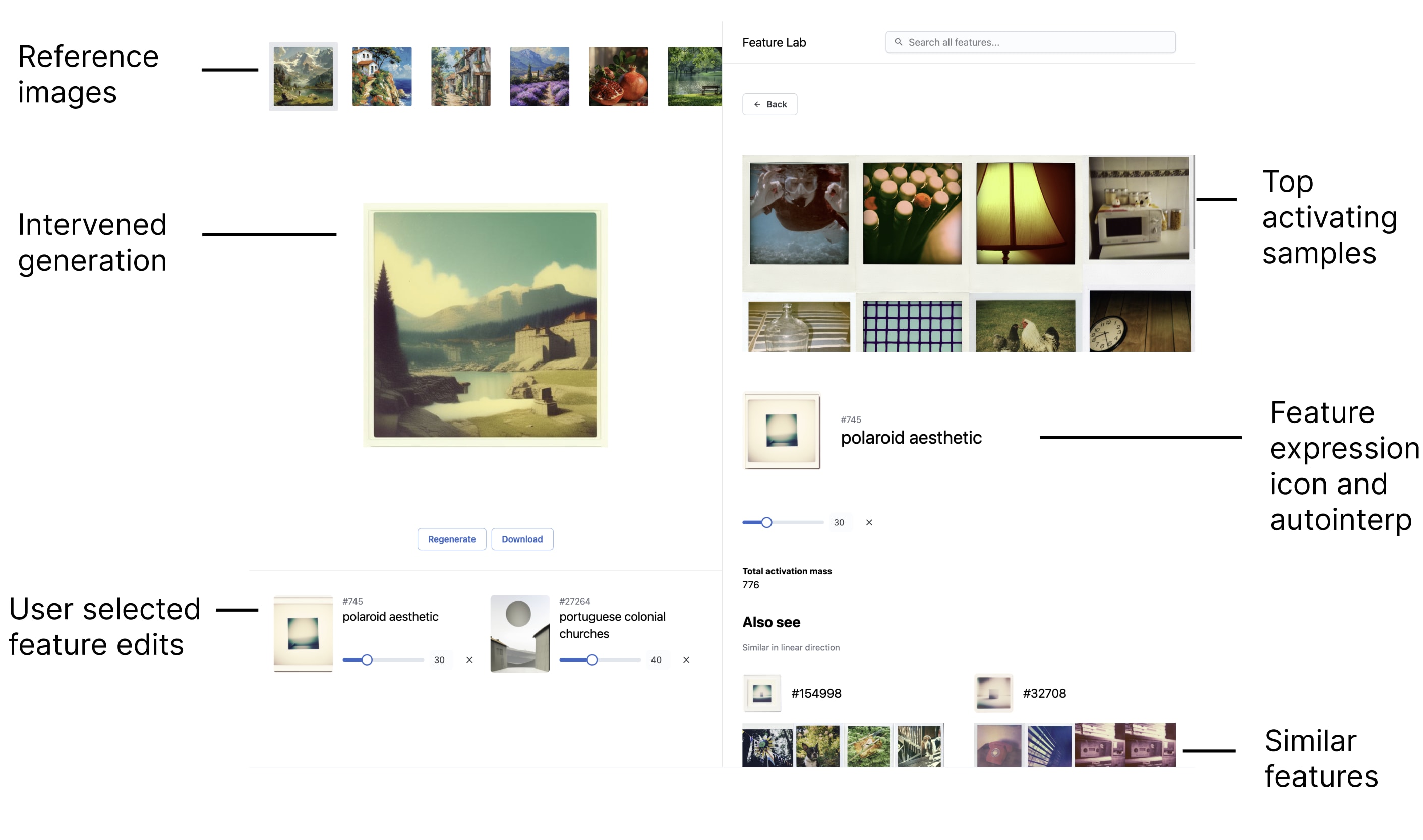 We trained a SAE to find sparse features in image embeddings. We found many meaningful, interpretable, and steerable features. We find that steering image diffusion works surprisingly well and yields predictable and high-quality generations.
We trained a SAE to find sparse features in image embeddings. We found many meaningful, interpretable, and steerable features. We find that steering image diffusion works surprisingly well and yields predictable and high-quality generations.
Great question that I wish I had an answer to! I haven't yet played around with GANs so not entirely sure. Do you have any intuition about what one would expect to see?