All of isabel's Comments + Replies
I think your Epoch link re-links to the OpenAI result, not something by Epoch.
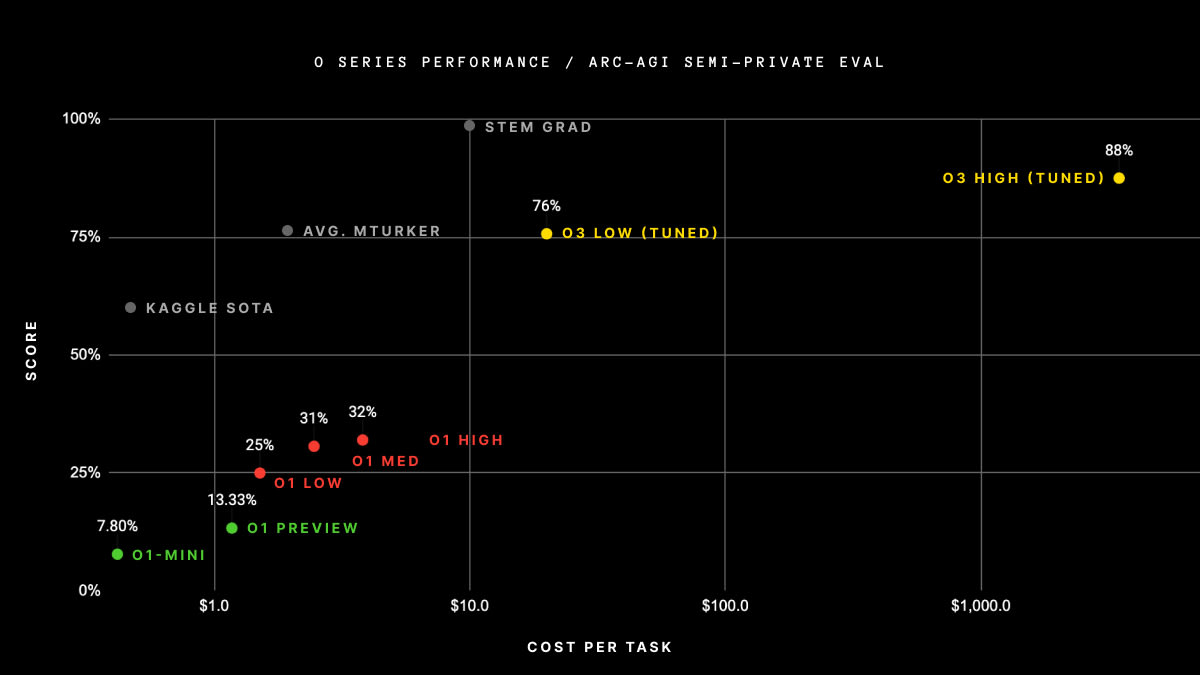
How likely is this just that OpenAI was willing to throw absurd amounts of inference time compute at the problem set to get a good score?
As U2 trains
should this be U3?
taking the dates literally, the first doubling took 19 months and the second doubling took 5 months, which does seem both surprising and increasingly fast.
oh, I like this feature a lot!
what's the plan for how scoring / checking resolved predictions will work?
it's not about inflation expectations (which I think pretty well anchored), it's about interest rates, which have risen substantially over this period and which has increased (and is expected to continue to increase) the cost of the US maintaining its debt (first two figures are from sites I'm not familiar with but the numbers seem right to me):
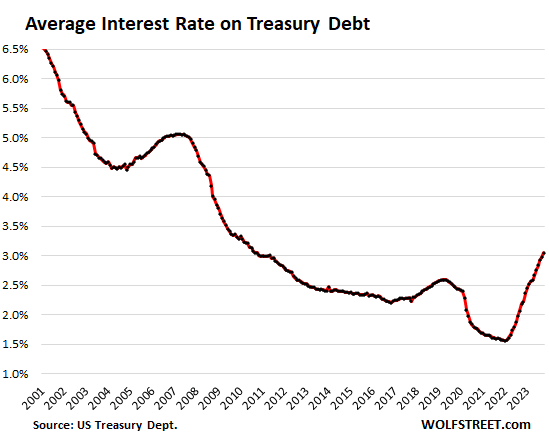
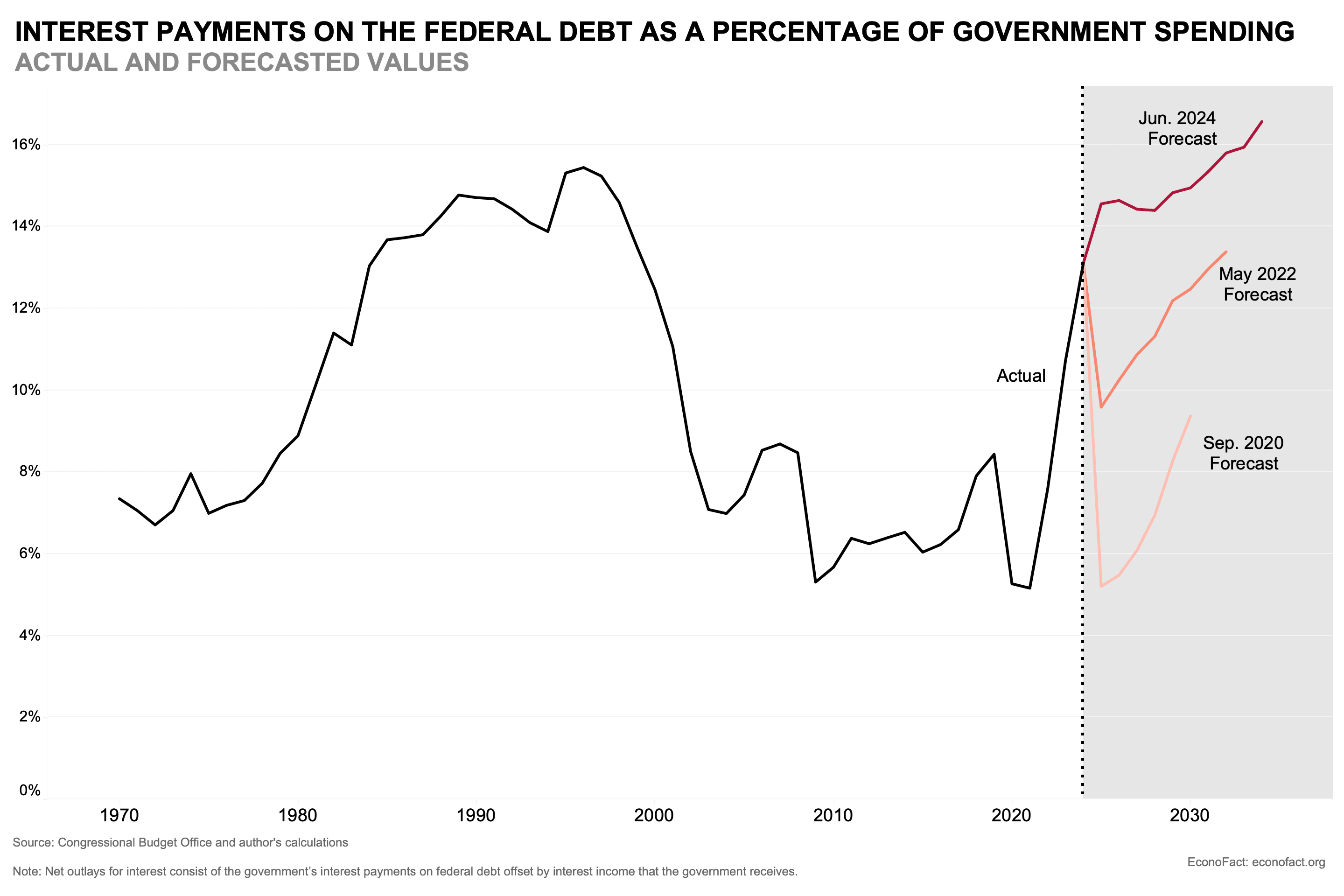
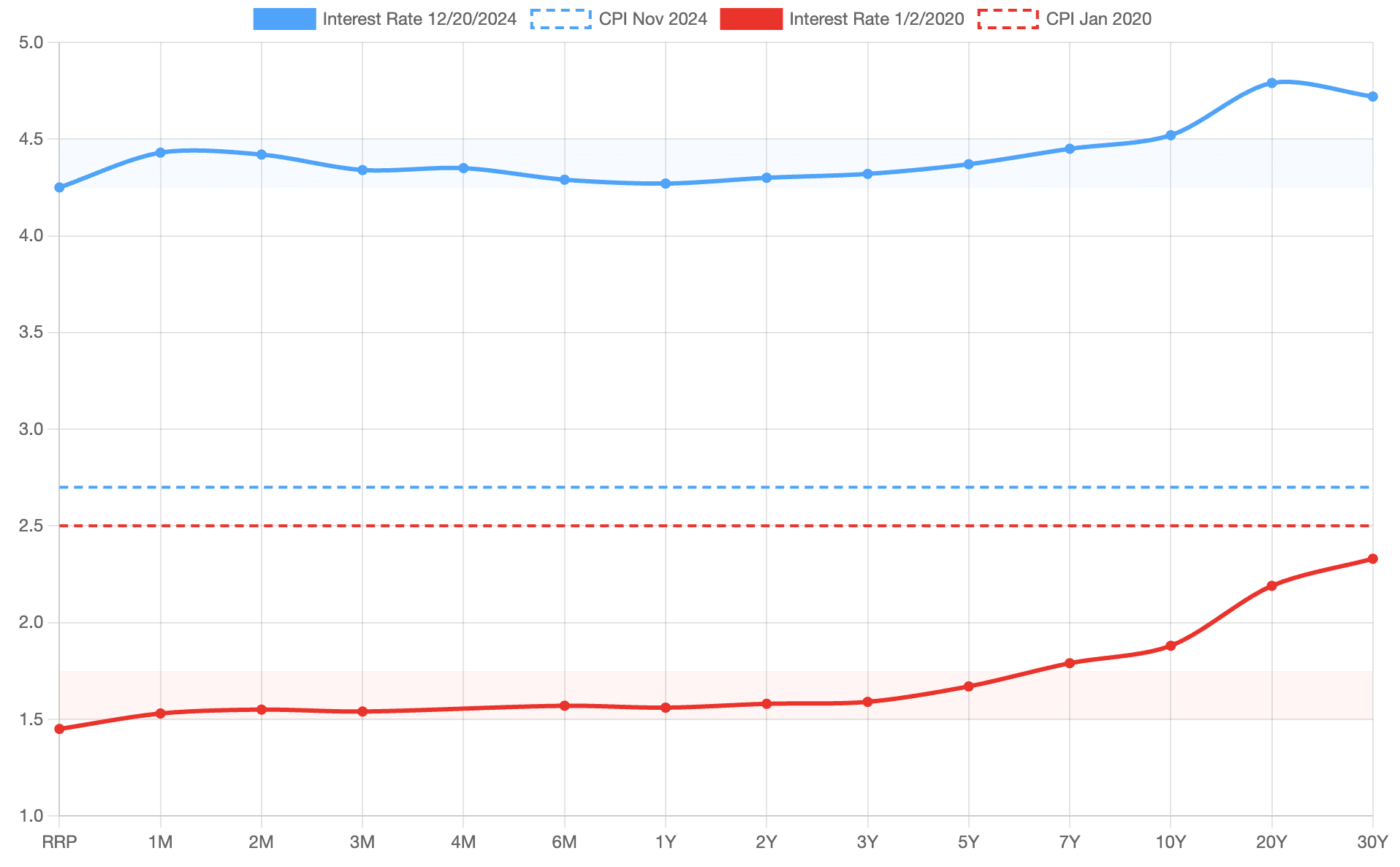
fwiw, I do broadly agree with your overall point that the dollar value of the debt is a bad statistic to use, but:
- the 2020-2024 period was also a misleading example to point to because it was one...
the debt/gdp ratio drop since 2020 I think was substantially driven by inflation being higher then expected rather than a function of economic growth - debt is in nominal dollars, so 2% real gdp growth + e.g. 8% inflation means that nominal gdp goes up by 10%, but we're now in a worse situation wrt future debt because interest rates are higher.
I do think that iterated with some unknown number of iterations is better than either single round or n-rounds at approximating what real world situations look like (and gets the more realistic result that cooperation is possible).
I agree that people are mostly not writing out things out this way when they're making real world decisions, but that applies equally to CDT and TDT, and being sensitive to small things like this seems like a fully general critique of game theory.
I think you can get cooperation on an iterated prisoners dilemma if there's some probability p that you play another round, if p is high enough - you just can't know at the outset exactly how many rounds there are going to be.
I would guess that there isn’t a clear smoking gun that people aren’t sharing because of NDAs, just a lot of more subtle problems that add up to leaving (and in some cases saying OpenAI isn’t being responsible etc).
This is consistent with the observation of the board firing Sam but not having a clear crossed line to point at for why they did it.
It’s usually easier to notice when the incentives are pointing somewhere bad than to explain what’s wrong with them, and it’s easier to notice when someone is being a bad actor than it is to articulate what they did wrong. (Both of these run a higher risk of false positives relative to more crisply articulatable problems.)
I think there should be some sort of adjustment for Boeing not being exceptionally sus before the first whistleblower death - shouldn't privilege Boeing until after the first death, should be thinking across all industries big enough that the news would report on the deaths of whistleblowers. which I think makes it not significant again.
It says there are 37 questions and I count 36, but I can’t find the missing one. If someone points it out, I’ll edit it in, don’t tell me anything expect the question wording.
The question that you're missing is "Will a member of the United States Congress introduce legislation limiting the use of LLMs in 2024?"
this seems like a comment that it seems reasonable to disagree with (e.g. think that habryka is wrong and subsequent evidence will not show what he predicts it will show) but it seems straightforwardly good epistemics to make clear predictions about which claims will and won't be falsified in the upcoming post, so I'm not sure why this comment is as being downvoted more than disagree voted (or downvoted at all).
am I confused about what karma vs agreement voting is supposed to signify?
While DeepMind hasn't been in quite as much in the limelight as OpenAI over the past several months, I would disagree that it hasn't had much hype over the past several years. GATO (a generalist agent) and AlphaCode seemed pretty hype-y to me, and to a lesser extent so were AlphaFold and Flamingo.
This Manifold market is for predicting which will be the "top-3" AI labs based on twitter buzz and hype, and according to the creator DeepMind was top 3 for 2022, and is currently also predicted to be second place for 2023 (though this is clearly not a compl...
I was also wondering if this was within scope. I haven't cross-posted mine yet, but might.
This initially seemed to give implausibly low numbers for optimal daily sun exposure, which seemed inconsistent with rates of Vitamin D deficiency (https://pubmed.ncbi.nlm.nih.gov/21310306/), though after thinking about it more I may just have unusually high sun exposure and be overestimating how much the median American gets.
the reason why my first thought was that they used more inference is that ARC Prize specifies that that's how they got their ARC-AGI score (https://arcprize.org/blog/oai-o3-pub-breakthrough) - my read on this graph is that they spent $300k+ on getting their score (there's 100 questions in the semi-private eval). o3 high, not o3-mini high, but this result is pretty strong proof of concept that they're willing to spend a lot on inference for good scores.