All of Jesse Hoogland's Comments + Replies
Looking back at this, I think this post is outdated and was trying a little too hard to be provocative. I agree with everything you say here. Especially: "One could reasonably say that PAC learning is somewhat confused, but learning theorists are working on it!"
Forgive my youthful naïvité. For what it's worth, I think the generalization post in this sequence has stood the test of time much better.
Claude 3.7 reward hacks. During training, Claude 3.7 Sonnet sometimes resorted to "special-casing" to pass tests when it got stuck — including directly hardcoding expected outputs or even modifying test files themselves. Rumors are circulating that o1/o3 was doing similar things — like overwriting equality operators to get Python tests to pass — and this may have contributed to the delayed release.
This seems relevant to claims that "we'll soon have reward models sophisticated enough to understand human values" and that inner alignment is the real challenge...
To me this doesn't seem like a failure of sophisticated reward models, it's the failure of unsophisticated reward models (unit tests) when they're being optimized against. I think that if we were to add some expensive evaluation during RL whereby 3.6 checked if 3.7 was "really doing the work", this sort of special-casing would get totally trained out.
(Not claiming that this is always the case, or that models couldn't be deceptive here, or that e.g. 3.8 couldn't reward hack 3.7)
But "models have singularities and thus number of parameters is not a good complexity measure" is not a valid criticism of VC theory.
Right, this quote is really a criticism of the classical Bayesian Information Criterion (for which the "Widely applicable Bayesian Information Criterion" WBIC is the relevant SLT generalization).
...Ah, I didn't realize earlier that this was the goal. Are there any theorems that use SLT to quantify out-of-distribution generalization? The SLT papers I have read so far seem to still be talking about in-distribution generalization,
To be precise, it is a property of singular models (which includes neural networks) in the Bayesian setting. There are good empirical reasons to expect the same to be true for neural networks trained with SGD (across a wide range of different models, we observe the LLC progressively increase from ~0 over the course of training).
The key distinction is that VC theory takes a global, worst-case approach — it tries to bound generalization uniformly across an entire model class. This made sense historically but breaks down for modern neural networks, which are so expressive that the worst-case is always very bad and doesn't get you anywhere.
The statistical learning theory community woke up to this fact (somewhat) with the Zhang et al. paper, which showed that deep neural networks can achieve perfect training loss on randomly labeled data (even with regularization). The same...
Okay, great, then we just have to wait a year for AlphaProofZero to get a perfect score on the IMO.
Yes, my original comment wasn't clear about this, but your nitpick is actually a key part of what I'm trying to get at.
Usually, you start with imitation learning and tack on RL at the end. That's what AlphaGo is. It's what predecessors to Dreamer-V3 like VPT are. It's what current reasoning models are.
But then, eventually, you figure out how to bypass the imitation learning/behavioral cloning part and do RL from the start. Human priors serve as a temporary bootstrapping mechanism until we develop approaches that can learn effectively from scratch.
I think this is important because the safety community still isn't thinking very much about search & RL, even after all the recent progress with reasoning models. We've updated very far away from AlphaZero as a reference class, and I think we will regret this.
On the other hand, the ideas I'm talking about here seem to have widespread recognition among people working on capabilities. Demis is very transparent about where they're headed with language models, AlphaZero, and open-ended exploration (e.g., at 20:48). Noam Brown is adamant about test-time sca...
To be fair here, AlphaZero was a case where it not only had an essentially unhackable reward model, but also could generate very large amounts of data, which while not totally unique to Go or gaming, is a property that is generally hard to come by in a lot of domains, so progress will probably be slower than AlphaZero.
Also, a lot of the domains are areas where latencies are either very low or you can tolerate long latency, which is not the case in the physical world very often.
With AlphaProof, the relevant piece is that the solver network generates its own proofs and disproofs to train against. There's no imitation learning after formalization. There is a slight disanalogy where, for formalization, we mostly jumped straight to self-play/search, and I don't think there was ever a major imitation-learning-based approach (though I did find at least one example).
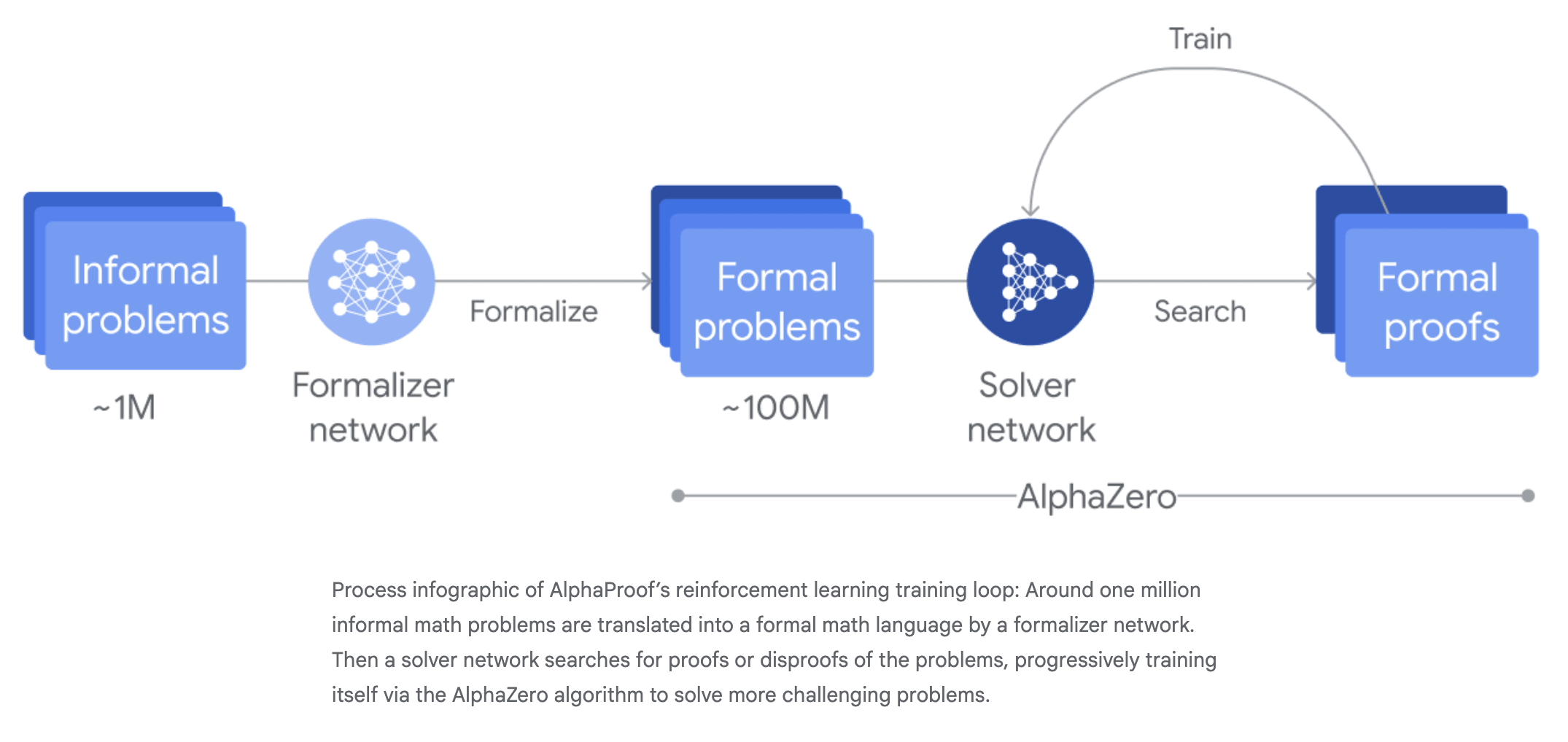
Your quote "when reinforcement learning works well, imitation learning is no longer needed" is pretty close to what I mean. What I'm actually trying to get at is a str...
That's fun but a little long. Why not... BetaZero?
What do you call this phenomenon?
- First, you train AlphaGo on expert human examples. This is enough to beat Lee Sedol and Ke Jie. Then, you train AlphaZero purely through self-play. It destroys AlphaGo after only a few hours.
- First, you train RL agents on human playthroughs of Minecraft. They do okay. Then, DreamerV3 learns entirely by itself and becomes the first to get diamonds.
- First, you train theorem provers on human proofs. Then, you train AlphaProof using AlphaZero and you get silver on IMO for the first time.
- First, you pretrain a language model on all
I think this is important because the safety community still isn't thinking very much about search & RL, even after all the recent progress with reasoning models. We've updated very far away from AlphaZero as a reference class, and I think we will regret this.
On the other hand, the ideas I'm talking about here seem to have widespread recognition among people working on capabilities. Demis is very transparent about where they're headed with language models, AlphaZero, and open-ended exploration (e.g., at 20:48). Noam Brown is adamant about test-time sca...
I don't think I get what phenomenon you're pointing to.
Your first bullet point makes it sound like AlphaGo wasn't trained using self-play, in contrast to AlphaZero. However, AlphaGo was trained with a combination of supervised learning and self-play. They removed the supervised learning part from AlphaZero to make it simpler and more general.
DreamerV3 also fits the pattern where previous SOTA approaches used a combination of imitation learning and reinforcement learning, while DreamerV3 was able to remove the imitation learning part.[1]
To my understanding,...
We won’t strictly require it, but we will probably strongly encourage it. It’s not disqualifying, but it could make the difference between two similar candidates.

Post-training consists of two RL stages followed by two SFT stages, one of which includes creative writing generated by DeepSeek-V3. This might account for the model both being good at creative writing and seeming closer to a raw base model.
Another possibility is the fact that they apply the RL stages immediately after pretraining, without any intermediate SFT stage.
Implications of DeepSeek-R1: Yesterday, DeepSeek released a paper on their o1 alternative, R1. A few implications stood out to me:
- Reasoning is easy. A few weeks ago, I described several hypotheses for how o1 works. R1 suggests the answer might be the simplest possible approach: guess & check. No need for fancy process reward models, no need for MCTS.
- Small models, big think. A distilled 7B-parameter version of R1 beats GPT-4o and Claude-3.5 Sonnet new on several hard math benchmarks. There appears to be a large parameter overhang.
- Proliferation by
Instead, we seem to be headed to a world where
- Proliferation is not bottlenecked by infrastructure.
- Regulatory control through hardware restriction becomes much less viable.
I like the rest of your post, but I'm skeptical of these specific implications.
Even if everyone has access to the SOTA models, some actors will have much more hardware to run on them, and I expect this to matter. This does make the offense/defense balance more weighted on the offense side, arguably, but there are many domains where extra thinking will help a lot.
More generally, ...
We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process
This line caught my eye while reading. I don't know much about RL on LLMs, is this a common failure mode these days? If so, does anyone know what such reward hacks tend to look like in practice?
Advanced capabilities can be squeezed into small, efficient models that can run on commodity hardware.
This could also work for general intelligence and not only narrow math/coding olympiad sort of problems. The potential of o1/R1 is plausibly constrained for now by ability to construct oracle verifiers for correctness of solutions, which mostly only works for toy technical problems. Capabilities on such problems are not very likely to generalize to general capabilities, there aren't clear signs so far that this is happening.
But this is a constraint on h...
This is a research direction that dates back to Clift et al. 2021. For a more recent and introductory example, see this post by @Daniel Murfet.
(Note: I've edited the announcement to remove explicit mention of geometry of program synthesis.)
I want to point out that there are many interesting symmetries that are non-global or data-dependent. These "non-generic" symmetries can change throughout training. Let me provide a few examples.
ReLU networks. Consider the computation involved in a single layer of a ReLU network:
or, equivalently,
(Maybe we're looking at a two-layer network where are the inputs and are the outputs, or maybe we're at some intermediate layer where these variables represent internal activations before and a...
That's what I meant by
...If the symmetry only holds for a particular solution in some region of the loss landscape rather than being globally baked into the architecture, the value will still be conserved under gradient descent so long as we're inside that region.
...
One could maybe hold out hope that the conserved quantities/coordinates associated with degrees of freedom in a particular solution are sometimes more interesting, but I doubt it. For e.g. the degrees of freedom we talk about here, those invariants seem similar to the ones in the ReLU
I agree. My original wording was too restrictive, so let me try again:
I think pushing the frontier past 2024 levels is going to require more and more input from the previous generation's LLMs. These could be open- or closed-source (the closed-source ones will probably continue to be better), but the bottleneck is likely to shift from "scraping and storing lots of data" to "running lots of inference to generate high-quality tokens." This will change the balance to be easier for some players, harder for others. I don't think that change in balance is perfectly aligned with frontier labs.
Phi-4: Synthetic data works. Pretraining's days are numbered.
Microsoft just announced Phi-4, a 14B parameter model that matches GPT-4o on some difficult benchmarks. The accompanying technical report offers a glimpse into the growing importance of synthetic data and how frontier model training is changing.
Some takeaways:
- The data wall is looking flimsier by the day. Phi-4 is highly capable not despite but because of synthetic data. It was trained on a curriculum of 50 types of synthetic datasets, generated by GPT-4o from a diverse set of or
Phi-4 is highly capable not despite but because of synthetic data.
Imitation models tend to be quite brittle outside of their narrowly imitated domain, and I suspect the same to be the case for phi-4. Some of the decontamination measures they took provide some counter evidence to this but not much. I'd update more strongly if I saw results on benchmarks which contained in them the generality and diversity of tasks required to do meaningful autonomous cognitive labour "in the wild", such as SWE-Bench (or rather what I understand SWE-Bench to be, I have yet t...
I don't think Phi-4 offers convincing evidence either way. You can push performance on verifiable tasks quite far without the model becoming generally more capable. AlphaZero doesn't imply that scaling with its methods gestures at general superintelligence, and similarly with Phi-4.
In contrast, using o1-like training as a way to better access ground truth in less tractable domains seems more promising, since by some accounts its tactics on long reasoning traces work even in non-technical domains (unlike for DeepSeek R1), possibly because they are emergent ...
The RL setup itself is straightforward, right? An MDP where S is the space of strings, A is the set of strings < n tokens, P(s'|s,a)=append(s,a) and reward is given to states with a stop token based on some ground truth verifier like unit tests or formal verification.
I agree that this is the most straightforward interpretation, but OpenAI have made no commitment to sticking to honest and straightforward interpretations. So I don't think the RL setup is actually that straightforward.
If you want more technical detail, I recommend watching the Rush &...
The examples they provide one of the announcement blog posts (under the "Chain of Thought" section) suggest this is more than just marketing hype (even if these examples are cherry-picked):
Here are some excerpts from two of the eight examples:
Cipher:
...Hmm.
But actually in the problem it says the example:...
Option 2: Try mapping as per an assigned code: perhaps columns of letters?
Alternatively, perhaps the cipher is more complex.
Alternatively, notice that "oyfjdnisdr" has 10 letters and "Think" has 5 letters....
Alternatively, perhaps subtract: 25 -15 = 10.
No.
A
It's worth noting that there are also hybrid approaches, for example, where you use automated verifiers (or a combination of automated verifiers and supervised labels) to train a process reward model that you then train your reasoning model against.
See also this related shortform in which I speculate about the relationship between o1 and AIXI:
Agency = Prediction + Decision.
AIXI is an idealized model of a superintelligent agent that combines "perfect" prediction (Solomonoff Induction) with "perfect" decision-making (sequential decision theory).
OpenAI's o1 is a real-world "reasoning model" that combines a superhuman predictor (an LLM like GPT-4) with advanced decision-making (implicit search via chain of thought trained by RL).
[Continued]
Agency = Prediction + Decision.
AIXI is an idealized model of a superintelligent agent that combines "perfect" prediction (Solomonoff Induction) with "perfect" decision-making (sequential decision theory).
OpenAI's o1 is a real-world "reasoning model" that combines a superhuman predictor (an LLM like GPT-4) with advanced decision-making (implicit search via chain of thought trained by RL).
To be clear: o1 is no AIXI. But AIXI, as an ideal, can teach us something about the future of o1-like systems.
AIXI teaches us that agency is simple. It involves just two ra...
We're not currently hiring, but you can always send us a CV to be kept in the loop and notified of next rounds.
East wrong is least wrong. Nuke ‘em dead generals!
West Wrong is Best Wrong.
To be clear, I don't care about the particular courses, I care about the skills.
This has been fixed, thanks.
I'd like to point out that for neural networks, isolated critical points (whether minima, maxima, or saddle points) basically do not exist. Instead, it's valleys and ridges all the way down. So the word "basin" (which suggests the geometry is parabolic) is misleading.
Because critical points are non-isolated, there are more important kinds of "flatness" than having small second derivatives. Neural networks have degenerate loss landscapes: their Hessians have zero-valued eigenvalues, which means there are directions you can walk along that don't change...
Anecdotally (I couldn't find confirmation after a few minutes of searching), I remember hearing a claim about Darwin being particularly ahead of the curve with sexual selection & mate choice. That without Darwin it might have taken decades for biologists to come to the same realizations.
If you'll allow linguistics, Pāṇini was two and a half thousand years ahead of modern descriptive linguists.
Right. SLT tells us how to operationalize and measure (via the LLC) basin volume in general for DL. It tells us about the relation between the LLC and meaningful inductive biases in the particular setting described in this post. I expect future SLT to give us meaningful predictions about inductive biases in DL in particular.
If we actually had the precision and maturity of understanding to predict this "volume" question, we'd probably (but not definitely) be able to make fundamental contributions to DL generalization theory + inductive bias research.
Obligatory singular learning theory plug: SLT can and does make predictions about the "volume" question. There will be a post soon by @Daniel Murfet that provides a clear example of this.
You can find a v0 of an SLT/devinterp reading list here. Expect an updated reading list soon (which we will cross-post to LW).
Our work on the induction bump is now out. We find several additional "hidden" transitions, including one that splits the induction bump in two: a first part where previous-token heads start forming, and a second part where the rest of the induction circuit finishes forming.
The first substage is a type-B transition (loss changing only slightly, complexity decreasing). The second substage is a more typical type-A transition (loss decreasing, complexity increasing). We're still unclear about how to understand this type-B transition structurally. How is the model simplifying? E.g., is there some link between attention heads composing and the basin broadening?
...As a historical note / broader context, the worry about model class over-expressivity has been there in the early days of Machine Learning. There was a mistrust of large blackbox models like random forest and SVM and their unusually low test or even cross-validation loss, citing ability of the models to fit noise. Breiman frank commentary back in 2001, "Statistical Modelling: The Two Cultures", touch on this among other worries about ML models. The success of ML has turn this worry into the generalisation puzzle. Zhang et. al. 2017 being a call to arms wh
Thanks for raising that, it's a good point. I'd appreciate it if you also cross-posted this to the approximation post here.
I think this mostly has to do with the fact that learning theory grew up in/next to computer science where the focus is usually worst-case performance (esp. in algorithmic complexity theory). This naturally led to the mindset of uniform bounds. That and there's a bit of historical contingency: people started doing it this way, and early approaches have a habit of sticking.
This is probably true for neural networks in particular, but mathematically speaking, it completely depends on how you parameterise the functions. You can create a parameterisation in which this is not true.
Agreed. So maybe what I'm actually trying to get at it is a statement about what "universality" means in the context of neural networks. Just as the microscopic details of physical theories don't matter much to their macroscopic properties in the vicinity of critical points ("universality" in statistical physics), just as the microscopic details of rand...
The easiest way to explain why this is the case will probably be to provide an example. Suppose we have a Bayesian learning machine with 15 parameters, whose parameter-function map is given by
and whose loss function is the KL divergence. This learning machine will learn 4-degree polynomials.
I'm not sure, but I think this example is pathological. One possible reason for this to be the case is that the symmetries in this model are entirely "generic" or "global." The more interesting kinds of symmetry are "...
I think there's some chance of models executing treacherous turns in response to a particular input, and I'd rather not trigger those if the model hasn't been sufficiently sandboxed.
One would really want to know if the complexity measure can predict 'emergence' of capabilities like inner-monologue, particularly if you can spot previously-unknown capabilities emerging which may not be covered in any of your existing benchmarks.
That's our hope as well. Early ongoing work on toy transformers trained to perform linear regression seems to bear out that lambdahat can reveal transitions where the loss can't.
...But this type of 'emergence' tends to happen with such expensive models that the available checkpoints are too separated to be inf
Oops yes this is a typo. Thanks for pointing it out.
Should be fixed now, thank you!
To be clear, our policy is not publish-by-default. Our current assessment is that the projects we're prioritizing do not pose a significant risk of capabilities externalities. We will continue to make these decisions on a per-project basis.
We don’t necessarily expect all dangerous capabilities to exhibit phase transitions. The ones that do are more dangerous because we can’t anticipate them, so this just seems like the most important place to start.
It's an open question to what extent the lottery-ticket style story of a subnetwork being continually upweighted contradicts (or supports) the phase transition perspective. Just because a subnetwork's strength is growing constantly doesn't mean its effect on the overall computation is. Rather than grokking, which is a very specific kind of phase t...
Now that the deadline has arrived, I wanted to share some general feedback for the applicants and some general impressions for everyone in the space about the job market:
- My number one recommendation for everyone is to work on more legible projects and outputs. A super low-hanging fruit for >50% of the applications would be to clean up your GitHub profiles or to create a personal site. Make it really clear to us which projects you're proud of, so we don't have to navigate through a bunch of old and out-of-use repos from classes you took years ago. We don
Hey Thomas, I wrote about our reasoning for this in response to Winston:
All in all, we're expecting most of our hires to come from outside the US where the cost of living is substantially lower. If lower wages are a deal-breaker for anyone but you're still interested in this kind of work, please flag this in the form. The application should be low-effort enough that it's still worth applying.
"Scalable" in the sense of "scalable oversight" refers to designing methods for scaling human-level oversight to systems beyond human-level capabilities. This doesn't necessarily mean the same thing as designing methods for reliably converting compute into more alignment. In practice, techniques for scalable oversight like debate, IDA, etc. often have the property that they scale with compute, but this is left as an implicit desideratum rather than an explicit constraint.