I'm curious if you have a sense of:
1. What the target goal of early-crunch time research should be (i.e. control safety case for the specific model one has at the present moment, trustworthy case for this specific model, trustworthy safety case for the specific model and deference case for future models, trustworthy safety case for all future models, etc...)
2. The rough shape(s) of that case (i.e. white-box evaluations, control guardrails, convergence guarantees, etc...)
3. What kinds of evidence you expect to accumulate given access to these early powerful models.
I expect I disagree with the view presented, but without clarification on the points above I'm not certain. I also expect my cruxes would route through these points
Is this vibes or was there some kind of study done?
I think I get it now. I was confused on how, under your model, we would continue to generate sequence of thoughts with thematic consistency i.e. [thinking about cake -> planning to buy a cake-> buying a cake-> eating a cake] as opposed to ones which aren't thematically consistent i.e. [think about cake -> take a nap -> call your friend -> scratch an itch].
Two things are apparent to me now:
- Valence is conditional on current needs
- Latent states of the thought generator are themselves inputs to the next thoughts being generated
I expect I'm still confused about valence, but may ask follow up questions on another thread in a more relevant post. Thanks for the reply!
Nit: The title give the impression of a demonstrated result as opposed to a working hypothesis and proposed experiment.
I'm curious on how/if goal coherence over long term plans is explained by your "planning as reward shaping" model? If planning amounts to an escalation of more and more "real thoughts" (i.e. I'm idly thinking about prinsesstårta -> A fork-full of prinsesstårta is heading towards my mouth), because these correspond to stronger activations in a valenced latent in my world model, and my thought generator is biased towards producing higher valence thoughts, it's unclear to me why we wouldn't just default to the production of untopical thoughts (i.e. I'm idly thinking about prinsesstårta -> I'm thinking about underneath a weighted blanket) and never get anything done in the world.
One reply would be to bite the bullet and say yup, humans due in fact have deficits in their long term planning strategies and this accounts for them but this feels unsatisfying; if the story given in my comment above was the only mechanism I'd expect us to be much worse. One possible reply is that "non-real thoughts" don't reliably lead towards rewards from the steering subsystem and the thought assessors down weight the valence associated w/ these thoughts thus leading to them being generated w/ lower frequency; consequently then, the only thought sequences which remain are ones which terminate in "real thoughts" and stimulate accurate predictions of the steering subsystem. This seems plausibly sufficient, but it still doesn't answer the question of why people don't arbitrarily switch into "equally real but non-topical" thought sequences at higher frequencies.
FWIW, links to the references point back to localhost
Sure, but I think that misses the point that I was trying to convey. If we end up in a world similar to the ones forecasted in ai-2027, the fraction of compute which labs allocate towards speeding up their own research threads will be larger than the amount of compute which labs will sell for public consumption.
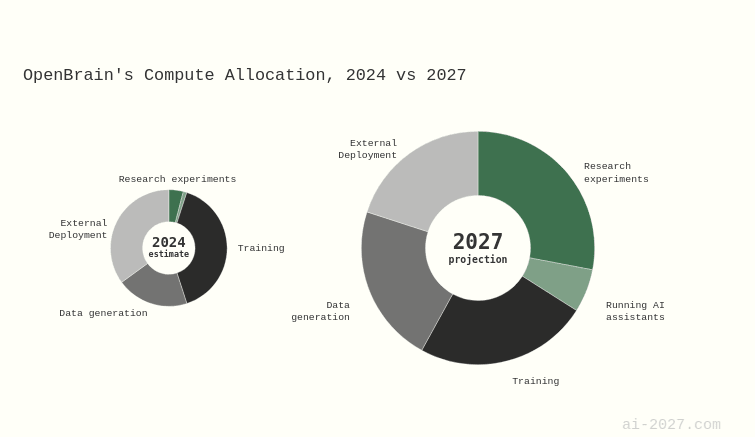
My view is that even in worlds with significant speed ups in R&D, we still ultimately care about the relative speed of progress on scalable alignment (in the Christiano sense) compared to capabilities & prosaic safety; doesn't matter if we finish quicker if catastrophic ai is finished quickest. Thus, an effective TOC for speeding up long horizon research would still route through convincing lab leadership of the pursuitworthiness of research streams.
Labs do have a moat around compute. In the worlds where automated R&D gets unlocked I would expect compute allocation to substantially pivot, making non-industrial automated research efforts non-competitive.
As far as I am concerned, AGI should be able to do any intellectual task that a human can do. I think that inventing important new ideas tends to take at least a month, but possibly the length of a PhD thesis. So it seems to be a reasonable interpretation that we might see human level AI around mid-2030 to 2040, which happens to be about my personal median.
There is an argument to be made that at the larger scales of length, cognitive tasks become cleanly factored, or in other words it's more accurate to model completing something like a PhD as different instantiations of yourself coordinating across time over low bandwidth channels, as opposed to you doing very high dimensional inference for a very long time. If that's the case, then one would expect to roughly match human performance in indefinite time horizon tasks once that scale has been reached.
I don't think I fully buy this, but I don't outright reject it.
As someone who has tried to engage w/ Live Theory multiple times and has found it intriguing, suspicious, and frustratingly mysterious I was very happy to see this write up. I was sad that the Q&A was announced in short notice. Am looking forward to watching the recording and am registering interest in attending a future one.