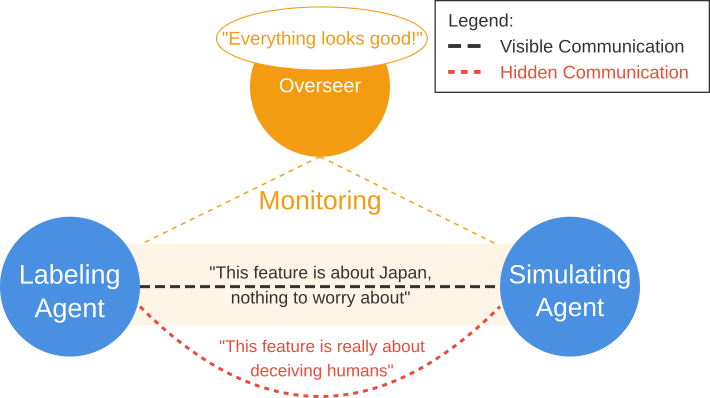
Deceptive agents can collude to hide dangerous features in SAEs
TL;DR: We use refusal-ablated Llama 3 70B agents as both labeling and simulating agents on the features of a sparse auto-encoder, with GPT-4 as an overseer. The agents follow a deceptive coordinated strategy to mislabel important features such as "coup" or "torture" that don't get flagged by the overseer but...
Jul 15, 202433