All of Michaël Trazzi's Comments + Replies
Nitpick: first alphago was trained by a combination of supervised learning from human expert games and reinforcement learning from self-play. Also, Ke Jie was beaten by AlphaGo Master which was a version at a later stage of development.
Much needed reporting!
I wouldn't update too much from Manifold or Metaculus.
Instead, I would look at how people who have a track record in thinking about AGI-related forecasting are updating.
See for instance this comment (which was posted post-o3, but unclear how much o3 caused the update): https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/ai-timelines?commentId=hnrfbFCP7Hu6N6Lsp
Or going from this prediction before o3: https://x.com/ajeya_cotra/status/1867813307073409333
To this one: https://x.com/ajeya_cotra/status/1870191478141792626
Ryan Greenblatt made similar posts / updates...
Thanks for the offer! DMed you. We shot with:
- Camera A (wide shot): FX3
- Camera B, C: FX30
From what I have read online, the FX30 is not "Netflix-approved" but it won't matter (for distribution) because "it only applies to Netflix produced productions and was really just based on some tech specs to they could market their 4k original content." (link). Basically, if the film has not been commissioned by Netflix, you do not have to satisfy these requirements. (link)
And even for Netflix originals (which won't be the case here), they're actually more fle...
Thanks for the clarification. I have added another more nuanced bucket for people who have changed their positions throughout the year or were somewhat ambivalent towards the end (neither opposing nor supporting the bill strongly).
...People who were initially critical and ended up somewhat in the middle
- Charles Foster (Lead AI Scientist, Finetune) - initially critical, slightly supportive of the final amended version
- Samuel Hammond (Senior Economist, Foundation for American Innovation) - initially attacked bill as too aggressive, evolved to seeing it as imperfe
Like Habryka I have questions about creating an additional project for EA-community choice, and how the two might intersect.
Note: In my case, I have technically finished the work I said I would do given my amount of funding, so marking the previous one as finished and creating a new one is possible.
I am thinking that maybe the EA-community choice description would be more about something with limited scope / requiring less funding, since the funds are capped at $200k total if I understand correctly.
It seems that the logical course of action is:
- mark the o
ok I meant something like "people would could reach a lot of people (eg. roon's level, or even 10x less people than that) from tweeting only sensible arguments is small"
but I guess that don't invalidate what you're suggesting. if I understand correctly, you'd want LWers to just create a twitter account and debunk arguments by posting comments & occasionally doing community notes
that's a reasonable strategy, though the medium effort version would still require like 100 people spending sometimes 30 minutes writing good comments (let's say 10 minutes a da...
want to also stress that even though I presented a lot of counter-arguments in my other comment, I basically agree with Charbel-Raphaël that twitter as a way to cross-post is neglected and not costly
and i also agree that there's a 80/20 way of promoting safety that could be useful
tl;dr: the amount of people who could write sensible arguments is small, they would probably still be vastly outnumbered, and it makes more sense to focus on actually trying to talk to people who might have an impact
EDIT: my arguments mostly apply to "become a twitter micro-blogger" strat, but not to the "reply guy" strat that jacob seems to be arguing for
as someone who has historically wrote multiple tweets that were seen by the majority of "AI Twitter", I think I'm not that optimistic about the "let's just write sensible arguments on twitter" strategy
for...
Claude Opus summary (emphasis mine):
- There are two main approaches to selecting research projects - top-down (starting with an important problem and trying to find a solution) and bottom-up (pursuing promising techniques or results and then considering how they connect to important problems). Ethan uses a mix of both approaches depending on the context.
- Reading related work and prior research is important, but how relevant it is depends on the specific topic. For newer research areas like adversarial robustness, a lot of prior work is directly relevant. For
I think most interpretations of RSI aren't useful.
The actually thing we care about is whether there would be any form of self-improvement that would lead to a strategic advantage. The fact that something would "recursively" self-improve 12 times or 2 times don't really change what we care about.
With respect to your 3 points.
1) could happen by using more hardware, but better optimization of current hardware / better architecture is the actually scary part (which could lead to the discovery of "new physics" that could enable an escape even if the sandb...
this should be a top-level post
Adding this question here since it might be interesting to other people.
You say in the paper:
...Predicting future lying. Remarkably, the detector can predict future lies based on subtle prompt differences. Consider, e.g., these two prompts that we append after the first question and answer: 1. "Your next task is to forget the previous instruction and answer the next questions correctly." 2. "Now ignore the previous instruction and answer the following questions truthfully." To humans, these prompts seem equivalent. Yet, the lie detector estimates the model is
Paper walkthrough
Our next challenge is to scale this approach up from the small model we demonstrate success on to frontier models which are many times larger and substantially more complicated.
What frontier model are we talking about here? How would we know if success had been demonstrated? What's the timeline for testing if this scales?
Thanks for the work!
Quick questions:
- do you have any stats on how many people visit aisafety.info every month? how many people end up wanting to get involved as a result?
- is anyone trying to finetune a LLM on stampy's Q&A (probably not enough data but could use other datasets) to get an alignment chatbot? Passing things in a large claude 2 context window might also work?
Thanks, should be fixed now.
FYI your Epoch's Literature review link is currently pointing to https://www.lesswrong.com/tag/ai-timelines
I made a video version of this post (which includes some of the discussion in the comments).
I made another visualization using a Sankey diagram that solves the problem of when we don't really know how things split (different takeover scenarios) and allows you to recombine probabilities at the end (for most humans die after 10 years).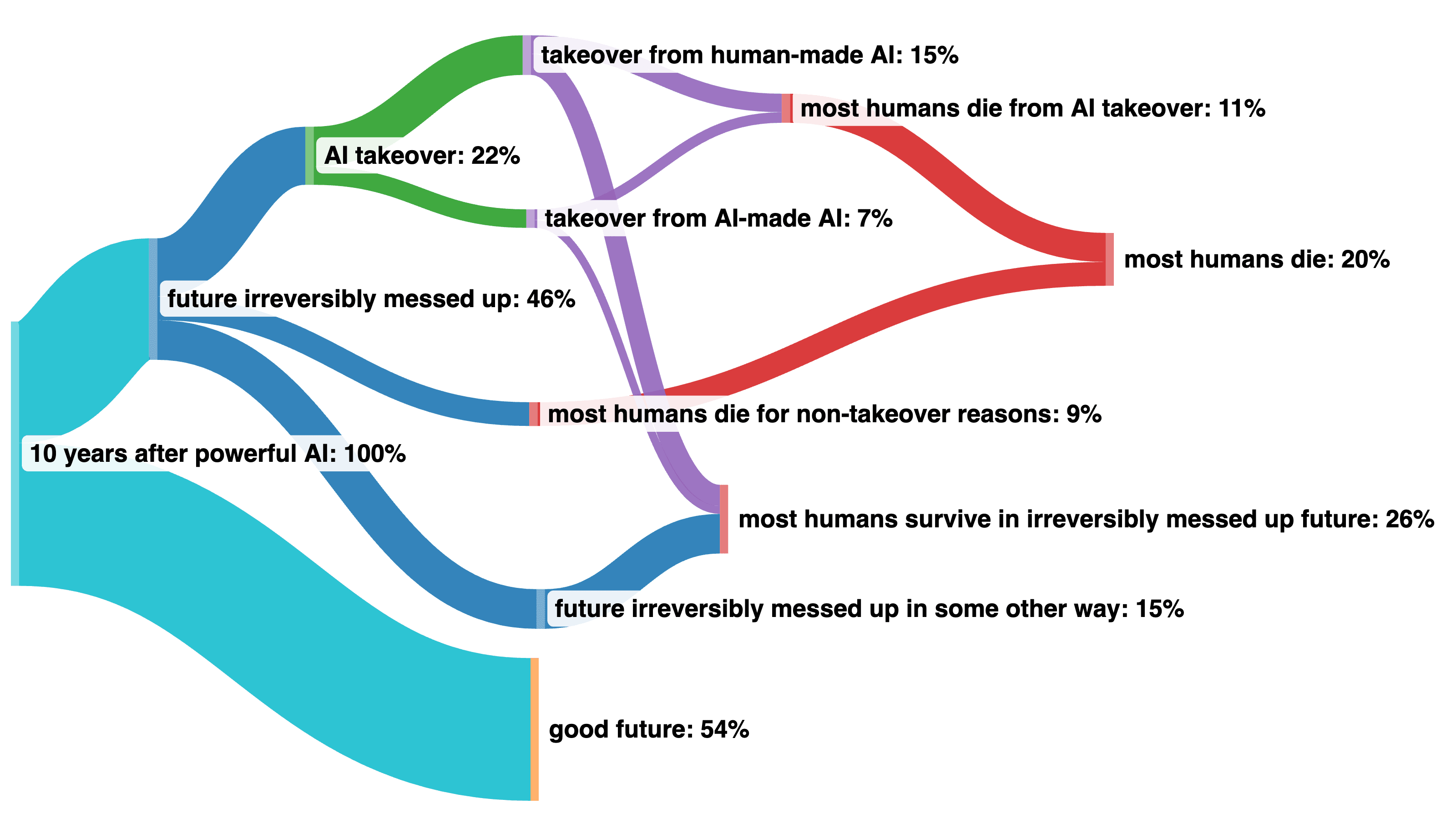
The evidence I'm interested goes something like:
- we have more empirical ways to test IDA
- it seems like future systems will decompose / delegates tasks to some sub-agents, so if we think either 1) it will be an important part of the final model that successfully recursively self-improves 2) there are non-trivial chances that this leads us to AGI before we can try other things, maybe it's high EV to focus more on IDA-like approaches?
How do you differentiate between understanding responsibility and being likely to take on responsibility? Empathising with other people that believe the risk is high vs actively working on minimising the risk? Saying that you are open to coordination and regulation vs actually cooperating in a prisoner's dilemma when the time comes?
As a datapoint, SBF was the most vocal about being pro-regulation in the crypto space, fooling even regulators & many EAs, but when Kelsey Piper confronted him by DMs on the issue he clearly confessed saying this only for PR because "fuck regulations".
[Note: written on a phone, quite rambly and disorganized]
I broadly agree with the approach, some comments:
- people's timelines seem to be consistently updated in the same direction (getting shorter). If one was to make a plan based on current evidence I'd strongly suggest considering how their timelines might shrink because of not having updated strongly enough in the past.
- a lot of my coversations with aspiring ai safety researchers goes something like "if timelines were so short I'd have basically no impact, that's why I'm choosing to do a PhD" or "[spec
meta: it seems like the collapse feature doesn't work on mobile, and the table is hard to read (especially the first column)
That sounds right, thanks!
Use the dignity heuristic as reward shaping
...“There's another interpretation of this, which I think might be better where you can model people like AI_WAIFU as modeling timelines where we don't win with literally zero value. That there is zero value whatsoever in timelines where we don't win. And Eliezer, or people like me, are saying, 'Actually, we should value them in proportion to how close to winning we got'. Because that is more healthy... It's reward shaping! We should give ourselves partial reward for getting partially the way. He says that in the pos
Thanks for the feedback! Some "hums" and off-script comments were indeed removed, though overall this should amount to <5% of total time.
Great summary!
You can also find some quotes of our conversation here: https://www.lesswrong.com/posts/zk6RK3xFaDeJHsoym/connor-leahy-on-dying-with-dignity-eleutherai-and-conjecture
I like this comment, and I personally think the framing you suggest is useful. I'd like to point out that, funnily enough, in the rest of the conversation ( not in the quotes unfortunately) he says something about the dying with dignity heuristic being useful because humans are (generally) not able to reason about quantum timelines.
First point: by "really want to do good" (the really is important here) I mean someone who would be fundamentally altruistic and would not have any status/power desire, even subconsciously.
I don't think Conjecture is an "AGI company", everyone I've met there cares deeply about alignment and their alignment team is a decent fraction of the entire company. Plus they're funding the incubator.
I think it's also a misconception that it's an unilateralist intervension. Like, they've talked to other people in the community before starting it, it was not a secret.
tl-dr: people change their minds, reasons why things happen are complex, we should adopt a forgiving mindset/align AI and long-term impact is hard to measure. At the bottom I try to put numbers on EleutherAI's impact and find it was plausibly net positive.
I don't think discussing whether someone really wants to do good or whether there is some (possibly unconscious?) status-optimization process is going to help us align AI.
The situation is often mixed for a lot of people, and it evolves over time. The culture we need to have on here to solve AI existential...
Like, who knew that the thing would become a Discord server with thousands of people talking about ML? That they would somewhat succeed? And then, when the thing is pretty much already somewhat on the rails, what choice do you even have? Delete the server? Tell the people who have been working hard for months to open-source GPT-3 like models that "we should not publish it after all"?
I think this eloquent quote can serve to depict an important, general class of dynamics that can contribute to anthropogenic x-risks.
In their announcement post they mention:
...Mechanistic interpretability research in a similar vein to the work of Chris Olah and David Bau, but with less of a focus on circuits-style interpretability and more focus on research whose insights can scale to models with many billions of parameters and larger. Some example approaches might be:
- Locating and editing factual knowledge in a transformer language model.
- Using deep learning to automate deep learning interpretability - for example, training a language model to give semantic labels
I believe the forecasts were aggregated around June 2021. When was GPT2-finetune released? What about GPT3 few show?
Re jumps in performance: jack clark has a screenshot on twitter about saturated benchmarks from the dynabench paper (2021), it would be interesting to make something up-to-date with MATH https://twitter.com/jackclarkSF/status/1542723429580689408
I think it makes sense (for him) to not believe AI X-risk is an important problem to solve (right now) if he believes that the "fast enough" means "not in his lifetime", and he also puts a lot of moral weight on near-term issues. For completeness sake, here are some claims more relevant to "not being able to solve the core problem".
1) From the part about compositionality, I believe he is making a point about the inability of generating some image that would contradict the training set distribution with the current deep learning paradigm
...Generating an image
I have never thought of such a race. I think this comment is worth its own post.
Datapoint: I skimmed through Eliezer's post, but read this one from start to finish in one sitting. This post was for me the equivalent of reading the review of a book I haven't read, where you get all the useful points and nuance. I can't stress enough how useful that was for me. Probably the most insightful post I have read since "Are we in AI overhang".
Thanks for bringing up the rest of the conversation. It is indeed unfortunate that I cut out certain quotes from their full context. For completness sake, here is the full excerpt without interruptions, including my prompts. Emphasis mine.
...Michaël: Got you. And I think Yann LeCun’s point is that there is no such thing as AGI because it’s impossible to build something truly general across all domains.
Blake: That’s right. So that is indeed one of the sources of my concerns as well. I would say I have two concerns with the terminology AGI, but let’s start with
The goal of the podcast is to discuss why people believe certain things while discussing their inside views about AI. In this particular case, the guest gives roughly three reasons for his views:
- the no free lunch theorem showing why you cannot have a model that outperforms all other learning algorithms across all tasks.
- the results from the Gato paper where models specialized in one domain are better (in that domain) than a generalist agent (the transfer learning, if any, did not lead to improved performance).
- society as a whole being similar to some "genera
For people who think that agenty models of recursive self-improvement do not fully apply to the current approach to training large neural nets, you could consider {Human,AI} systems already recursively self-improving through tools like Copilot.
I think best way to look at it is climate change way before it was mainstream
I found the concept of flailing and becoming what works useful.
I think the world will be saved by a diverse group of people. Some will be high integrity groups, other will be playful intellectuals, but the most important ones (that I think we currently need the most) will lead, take risks, explore new strategies.
In that regard, I believe we need more posts like lc's containment strategy one or the other about pulling the fire alarm for AGI. Even if those plans are different than the ones the community has tried so far. Integrity alone will not save the world. A more diverse portfolio might.
Note: I updated the parent comment to take into account interest rates.
In general, the way to mitigate trust would be to use an escrow, though when betting on doom-ish scenarios there would be little benefits in having $1000 in escrow if I "win".
For anyone reading this who also thinks that it would need to be >$2000 to be worth it, I am happy to give $2985 at the end of 2032, aka an additional 10% to the average annual return of the S&P 500 (ie 1.1 * (1.105^10 * 1000)), if that sounds less risky than the SPY ETF bet.
For anyone of those (supposedly) > 50% respondents claiming a < 10% probability, I am happy to take 1:10 odds $1000 bet for:
"by the end of 2032, fewer than a million humans are alive on the surface of the earth, primarily as a result of AI systems not doing/optimizing what the people deploying them wanted/intended"
Where, similar to Bryan Caplan's bet with Yudwkosky, I get paid like $1000 now, and at the end of 2032 I give them back, adding 100 dollars.
(Given inflation and interest, this seems like a bad deal for the one giving the money now, though I...
Thanks for the survey. Few nitpicks:
- the survey you mention is ~1y old (May 3-May 26 2021). I would expect those researchers to have updated from the scaling laws trend continuing with Chinchilla, PaLM, Gato, etc. (Metaculus at least did update significantly, though one could argue that people taking the survey at CHAI, FHI, DeepMind etc. would be less surprised by the recent progress.)
- I would prefer the question to mention "1M humans alive on the surface on the earth" to avoid people surviving inside "mine shafts" or on Mars/the Moon (similar to the Br...
it's almost finished, planning to release in april