Orienting to 3 year AGI timelines
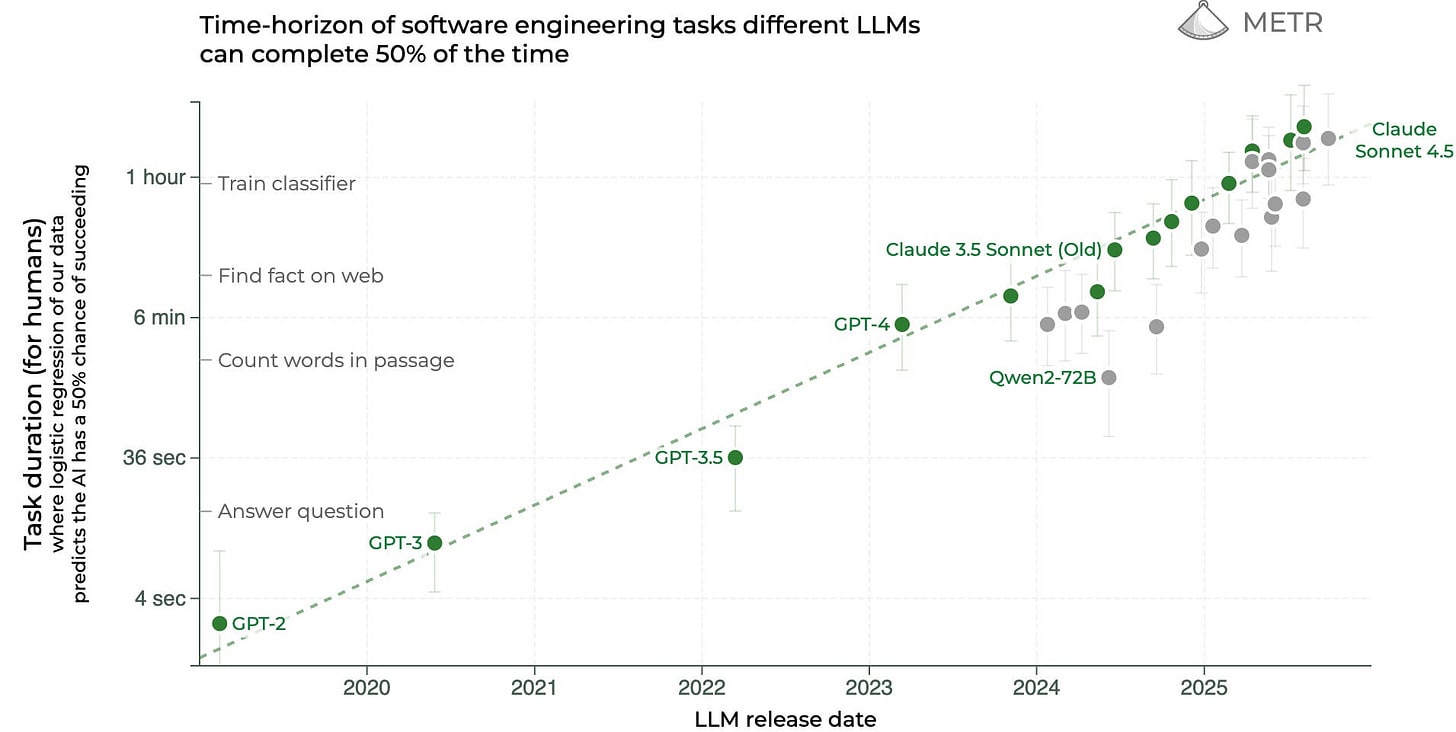
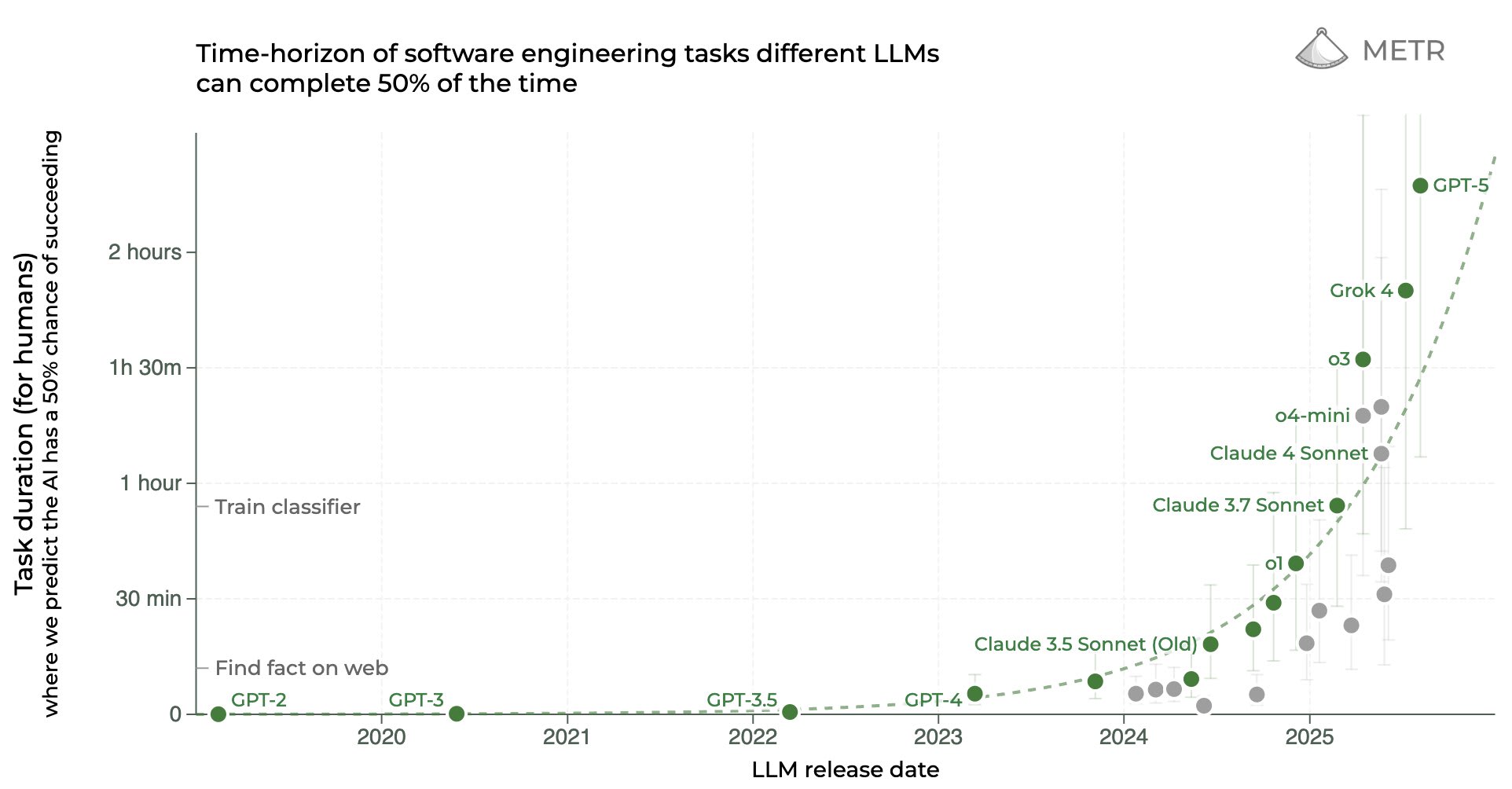
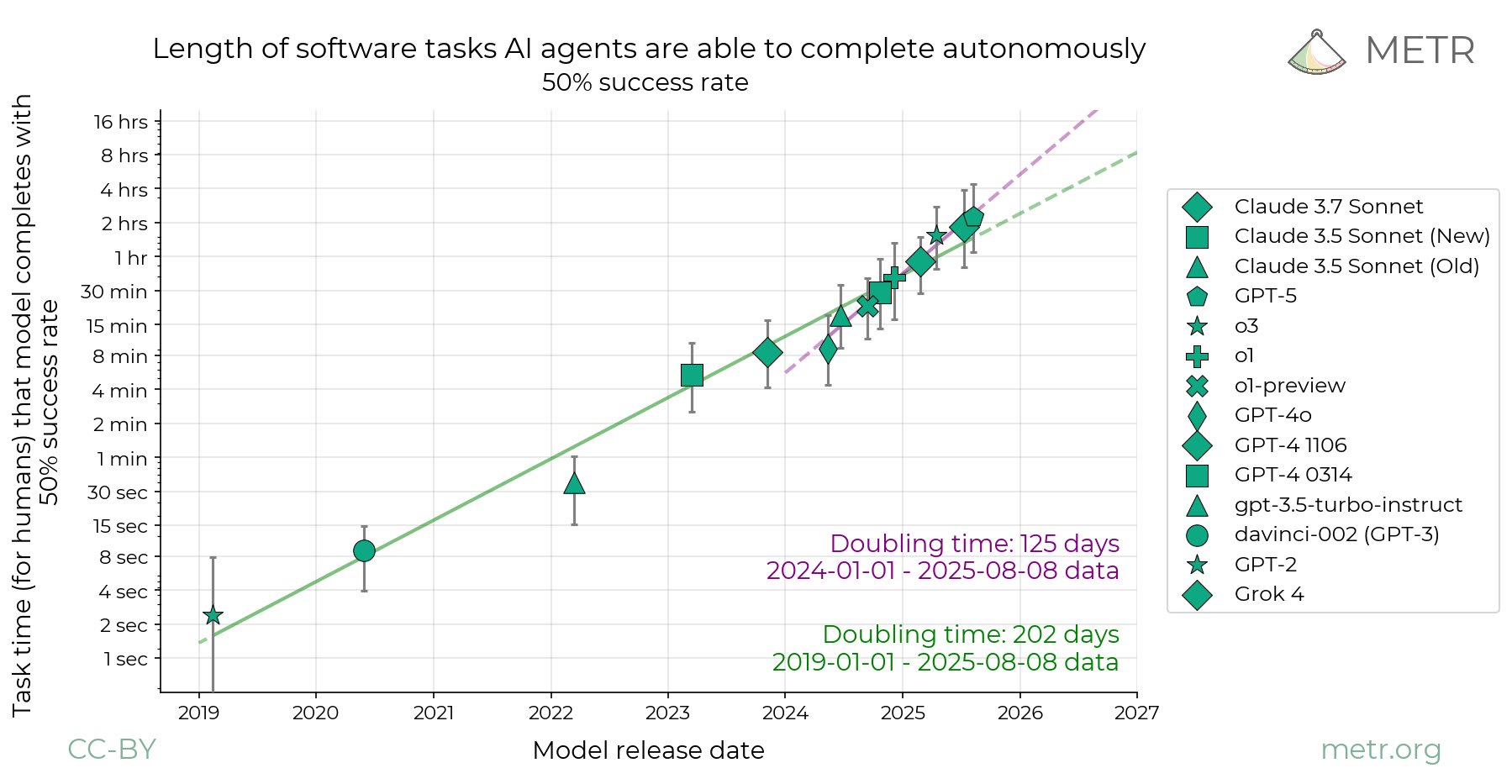
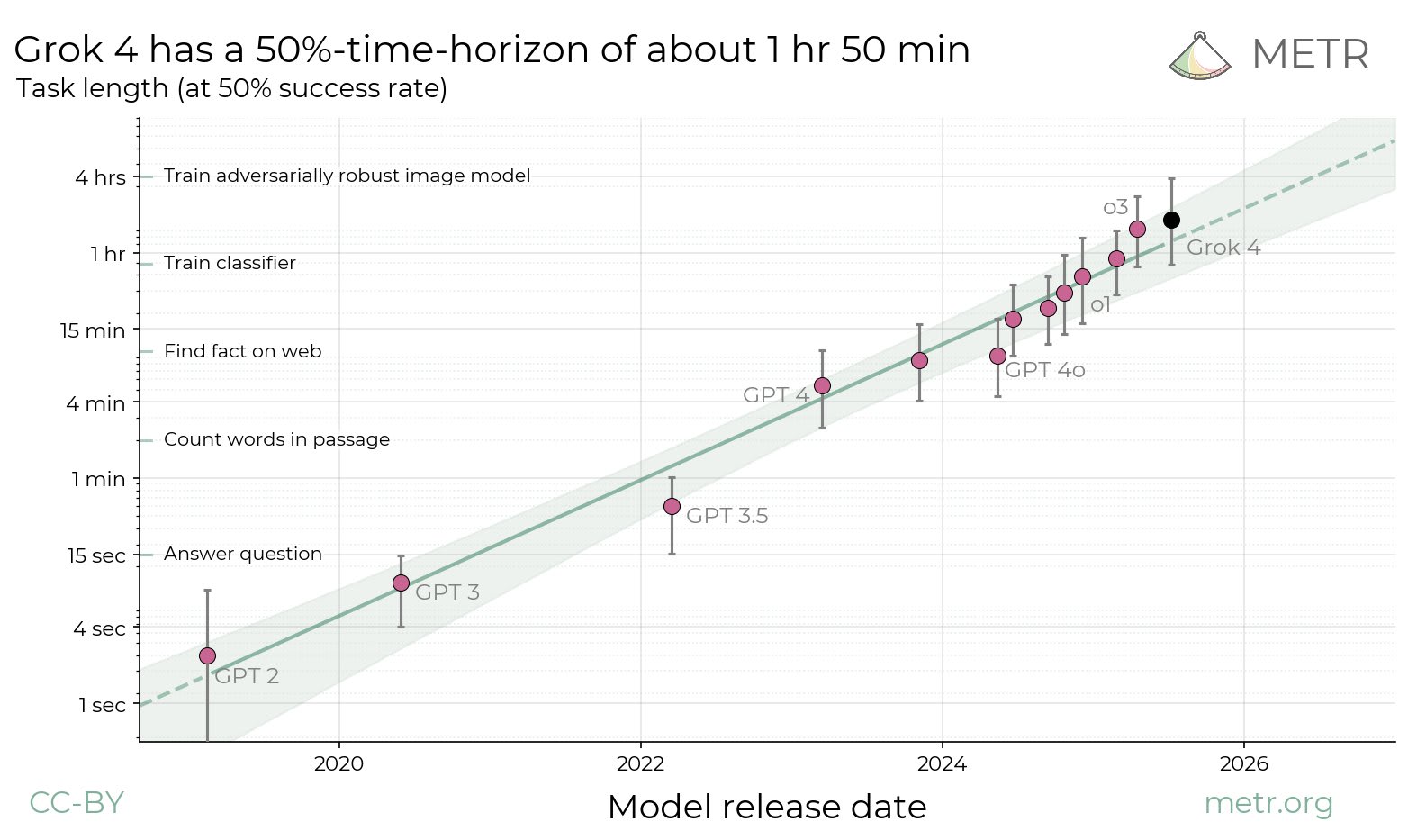
EDIT 2026/02/12: My median for AGI is now EOY 2029. My quantitative predictions for 2025 were a bit too bullish, and they translated to smaller real-world impacts (on the rate of AI progress and adoption) than I expected. My median expectation is that AGI[1] will be created 3 years from now. This has implications on how to behave, and I will share some useful thoughts I and others have had on how to orient to short timelines. I’ve led multiple small workshops on orienting to short AGI timelines and compiled the wisdom of around 50 participants (but mostly my thoughts) here. I’ve also participated in multiple short-timelines AGI wargames and co-led one wargame. This post will assume median AGI timelines of 2027 and will not spend time arguing for this point. Instead, I focus on what the implications of 3 year timelines would be. I didn’t update much on o3 (as my timelines were already short) but I imagine some readers did and might feel disoriented now. I hope this post can help those people and others in thinking about how to plan for 3 year AGI timelines. The outline of this post is: * A story for 3 year AGI timelines, including important variables and important players * Prerequisites for humanity’s survival which are currently unmet * Robustly good actions A story for a 3 year AGI timeline By the end of June 2025, SWE-bench is around 85%, RE-bench at human budget is around 1.1, beating the 70th percentile 8-hour human score. By the end of 2025, AI assistants can competently do most 2-hour real-world software engineering tasks. Whenever employees at AGI companies want to make a small PR or write up a small data analysis pipeline, they ask their AI assistant first. The assistant writes or modifies multiple interacting files with no errors most of the time. Benchmark predictions under 3 year timelines. A lot of the reason OSWorld and CyBench aren’t higher is because I’m not sure if people will report the result
If you have a Costco membership you can buy $100 dollars of Uber gift cards online for $80. This provides a 20% discount on all of Uber.
Sadly you can only buy $100 every 2 weeks, meaning your savings per year are limited to 20$ * (52/2) = $520. A Costco membership costs $65 a year. It's unclear how long this will stay an option.