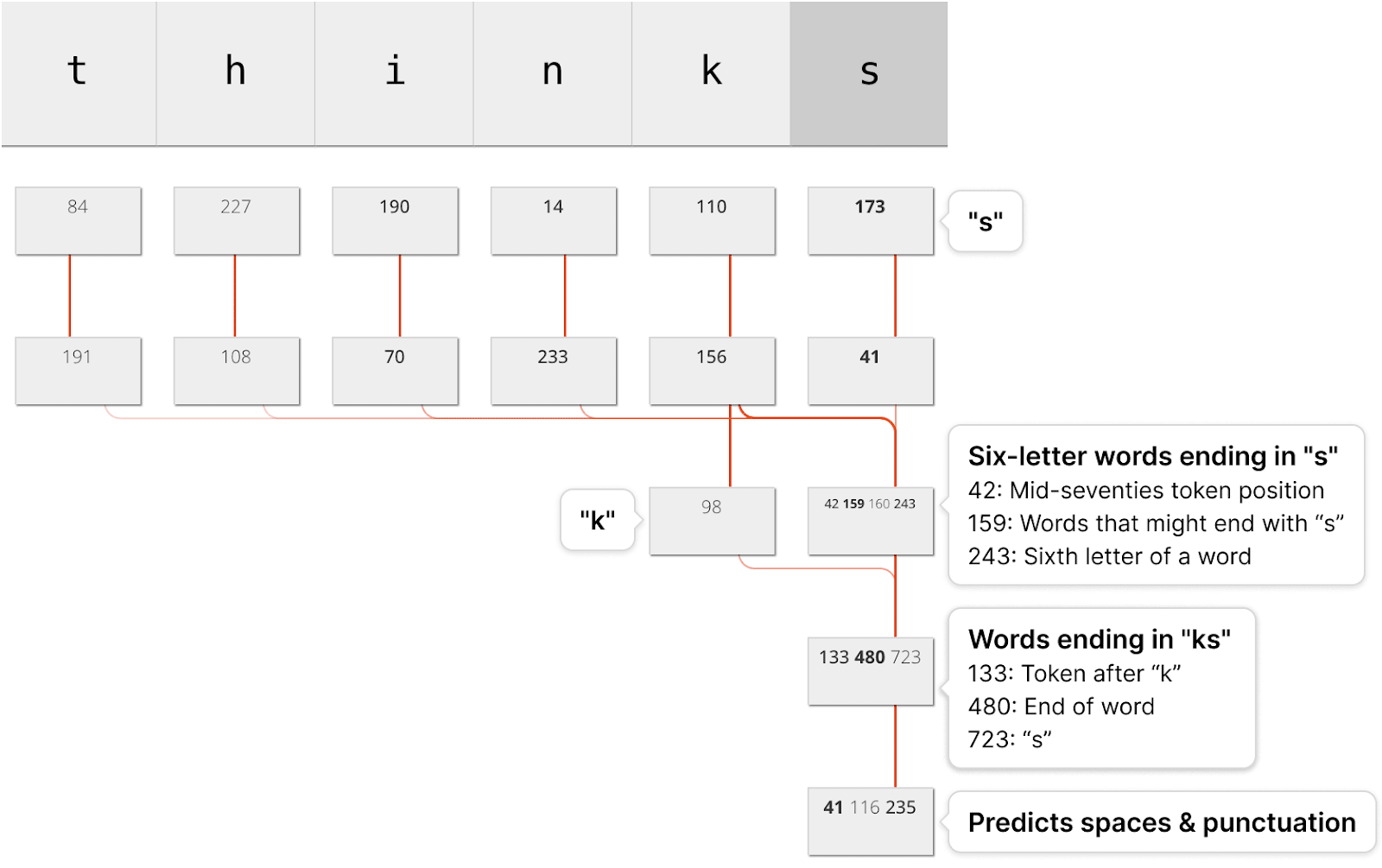
Sparse Autoencoders (SAEs) are useful for providing insight into how a model processes and represents information. A key goal is to represent language model activations as a small number of features (L0) while still achieving accurate reconstruction (measured via reconstruction error or cross-entropy loss increase). Past research has focused on improving SAE training techniques to address a trade-off between sparsity and reconstruction quality (e.g. TopK, JumpReLU). Other efforts have explored designing more interpretable LLMs (e.g. Softmax Linear Units, Bilinear MLPs, Codebook Features, Adversarial Interpretability (Thurnherr et al. (in preparation)).
Here we propose improving model interpretability through adding a regularization term during model training. This involves training an LLM alongside multiple SAE layers, using... (read 985 more words →)