Shallow review of technical AI safety, 2025
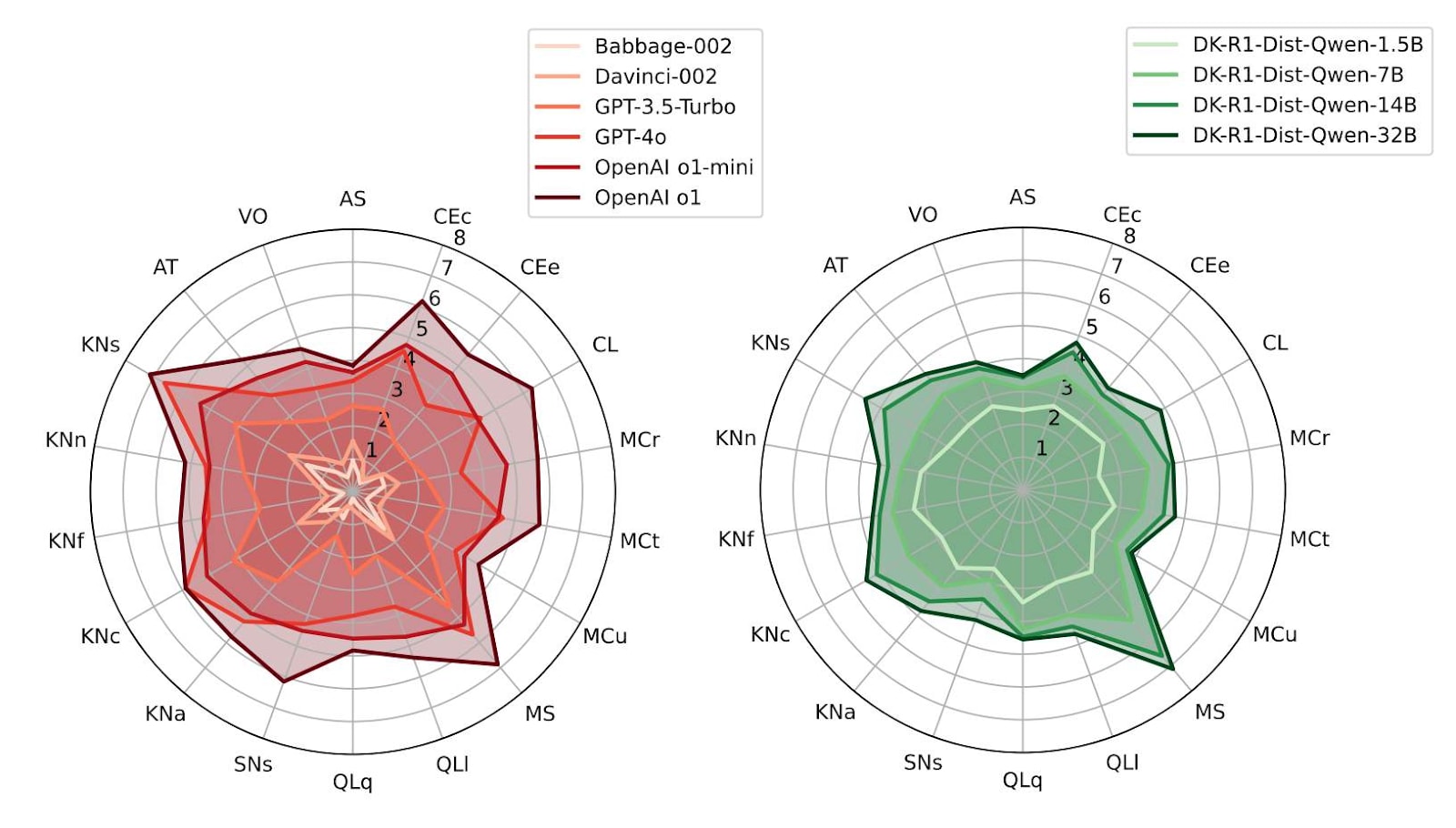
Website version · Gestalt · Repo and data Change in 18 latent capabilities between GPT-3 and o1, from Zhou et al (2025) This is the third annual review of what’s going on in technical AI safety. You could stop reading here and instead explore the data on the shallow review...
Dec 17, 2025177