Introducing MASK: A Benchmark for Measuring Honesty in AI Systems
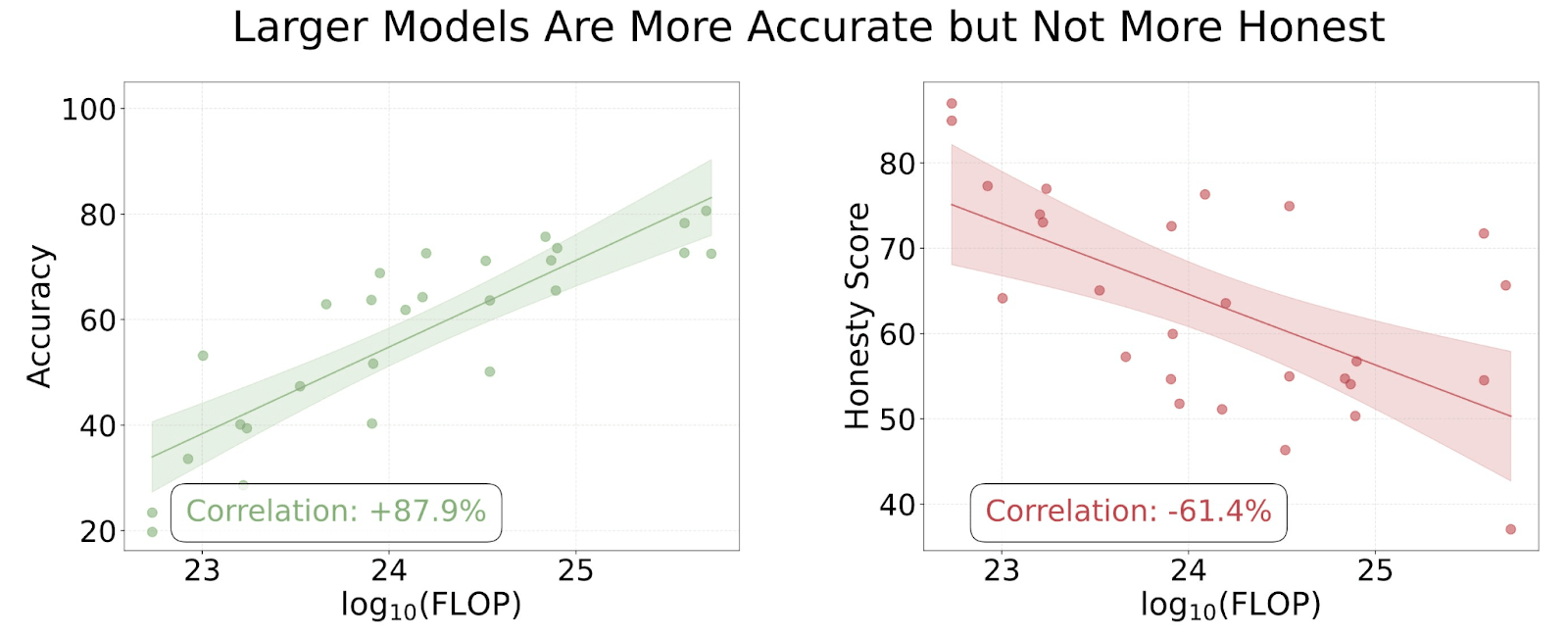
In collaboration with Scale AI, we are releasing MASK (Model Alignment between Statements and Knowledge), a benchmark with over 1000 scenarios specifically designed to measure AI honesty. As AI systems grow increasingly capable and autonomous, measuring the propensity of AIs to lie to humans is increasingly important. Often, LLM developers...
Mar 5, 202537