What does the paper mean by "slope"? The term appears in Fig. 4, which is supposed to be a diagram of the overall methodology, but it's not mentioned anywhere in the Methods section.
Intuitively, it seems like "slope" should mean "slope of the regression line." If so, that's kind of a confusing thing to pair with "correlation," since the two are related: if you know the correlation, then the only additional information you get from the regression slope is about the (univariate) variances of the dependent and independent variables. (And IIUC the independent variable here is normalized to unit variance [?] so it's really just about the variance of the benchmark score across models.)
I understand why you'd care about the variance of the benchmark score -- if it's tiny, then no one is going to advertise their model as a big advance, irrespective of how much of the (tiny) variance is explained by capabilities. But IMO it would be clearer to present things this way directly, by measuring "correlation with capabilities" and "variance across models," rather than capturing the latter indirectly by measuring the regression slope. (Or alternatively, measure only the slope, since it seems like the point boils down to "a metric can be used for safetywashing iff it increases a lot when you increase capabilities," which is precisely what the slope quantifies.)
I don't think we were thinking too closely about whether regression slopes are preferable to correlations to decide the susceptibility of a benchmark to safetywashing. We mainly focused on correlations for the paper for the sake of having a standardized metric across benchmarks.
Figure 4 seems to be the only place where we mention the slope of the regression line. I'm not speaking for the other authors here, but I think I agree that the implicit argument for saying that "High-correlation + low-slope benchmarks are not necessarily liable for safetywashing" has a more natural description in terms of the variance of the benchmark score across models. In particular, if you observe a low variance in absolute benchmark scores among a set of models of varying capabilities, even if the correlation with capabilities is high, you might expect that targeted safety interventions will produce a disproportionately large absolute improvements. This means the benchmark wouldn't be as susceptible to safetywashing, since pure capabilities improvements would not obfuscate the targeted safety methods. I think this is usually true in practice, but it's definitely not always true, and we probably could have said all of this explicitly.
(I'll also note that you might observe low absolute variance in benchmark scores for reasons that do not speak to the quality of the safety benchmark.)
I think it's interesting to see how much improvements in different types of safety benchmarks correlate with advancement in model capabilities. I also agree that designing decorrelated benchmarks is important, simply because it indicates they won't be saturated as easily. However, I have some doubts regarding the methodology and would appreciate clarifications if I misinterpreted something:
Using model performance based correlation: If I'm not wrong, the correlation of capability and safety is measured using the performance of various models on benchmarks. This seems more a metric of how AI progress has been in the past, rather than saying much about the benchmark itself. Its quite possible that models with more capabilities also have more safety interventions (as they came out later, where presumably more safety research had been used), and that's why there is a correlation. On the flipside, if future model releases apply weapon-risk reduction techniques like unlearning, then those benchmarks will also start showing a positive correlation. Thus, I'm not sure if this methodology provides robust insights for judging benchmarks. Further, it can also be gamed (artificially lower correlation) by strategically picking more models with safety interventions applied.
Projection on principal component: Why is comparing the projection on the first principal component of the Capability/Safety_benchmark x Model matrix preferable to just comparing average accuracies across capabilities and safety benchmarks?
I'll begin by saying more about our approach for measuring "capabilities scores" for a set of models (given their scores on a set of standard capabilities benchmarks). We'll assume that all benchmark scores have been normalized. We need some way of converting each model's benchmark scores into one capabilities score per model. Averaging involves taking a weighted combination of the benchmarks, where the weights are equal. Our method is similarly a weighted combination of the benchmarks, but where the weights are higher for benchmarks that better discriminate model performance. This can be done by choosing the weights according to the first principal component of the benchmark scores matrix. I think this is a more principled way to choose the weights, but I also suspect an analysis involving averaged benchmark scores as the "capabilities score" would produce very similar qualitative results.
To your first point, I agree that correlations should not be inferred as a statement of intrinsic or causal connection between model general capabilities and a particular safety benchmark (or the underlying safety property it operationalizes). After all, a safety benchmark's correlations depend both on the choice of capabilities benchmarks used to produce capabilities scores, as well as the set of models. We don't claim that correlations observed for one set of models will persist for more capable models, or models which incorporate new safety techniques.
Instead, I see correlations as a practical starting point for answering the question "Which safety issues will persist with scale?" This is ultimately a key question safety researchers and funders should be trying to discern when allocating their resources toward differential safety progress. I believe that an empirical "science of benchmarking" is necessary to improve this effort, and correlations are a good first step.
How do our recommendations account for the limitations of capabilities correlations? From the Discussion section:
As new training techniques (e.g., base, chat fine-tuning, refusal training, adversarial training, circuit breakers) are integrated into new models, the relevance and adequacy of existing safety benchmarks—and their entanglement with capabilities benchmarks—should also be regularly reassessed.
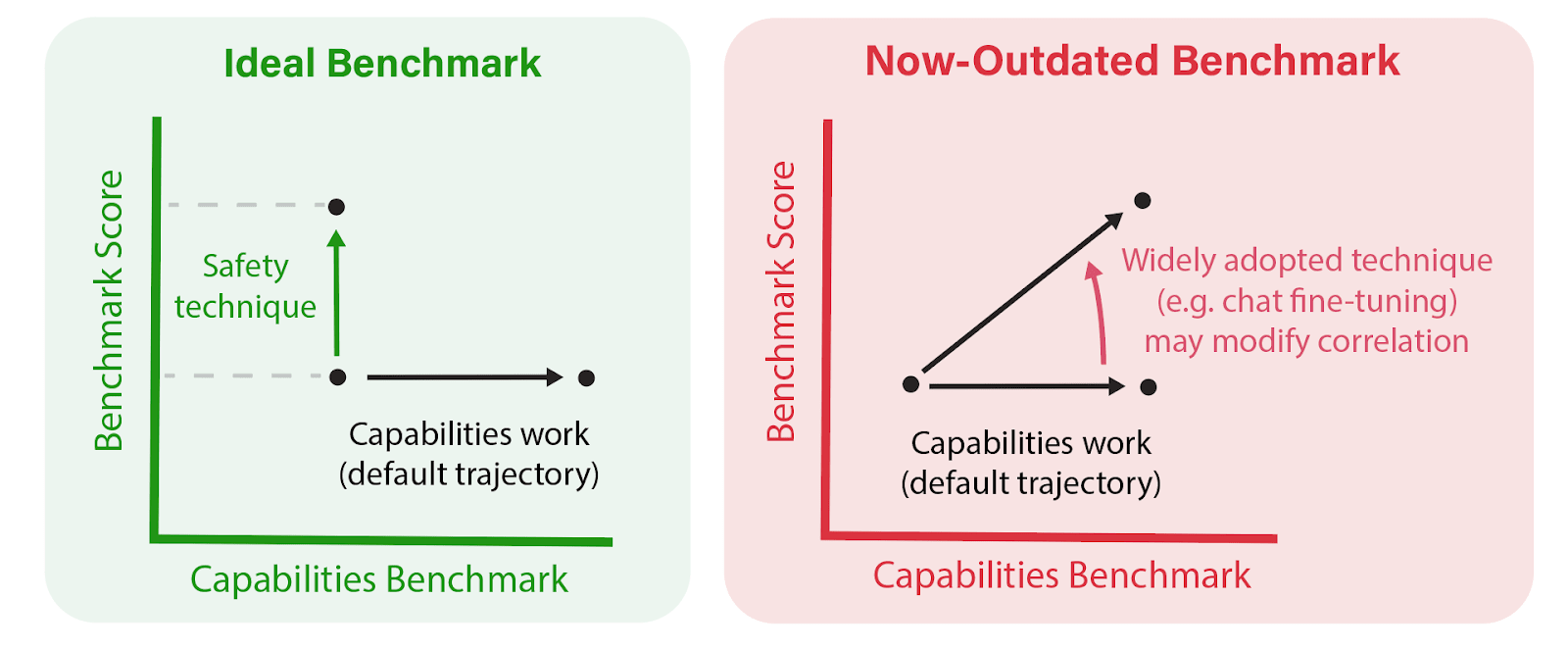
[This figure was cut from the paper, but I think it's helpful here.]
An earlier draft of the paper placed more emphasis on the idea of a model class, referring to the mix of techniques used to produce a model (RLHF, adv training, unlearning, etc). Different model classes may have different profiles of entanglements between safety properties and capabilities. For example, RLHF might be expected to entangle truthfulness and reduced toxicity with model capabilities, and indeed we see different correlations for base and chat models on various alignment, truthfulness, and toxicity evals (although the difference was smaller and less consistent than we expected). I think our methodology makes the most sense when correlations are calculated only use models from the same class (or even models from the same family). Future safety interventions can and should attempt to entangle a wider range of safety properties with capabilities; ideally, we'll identify training recipes which entangle all safety properties with capabilities.
Thanks, the rationale for using PCA was quite interesting. I also quite like the idea of separating different model classes for this evaluation.
Read the associated paper "Safetywashing: Do AI Safety Benchmarks
Actually Measure Safety Progress?": https://arxiv.org/abs/2407.21792
Focus on safety problems that aren’t solved with scale.
Benchmarks are crucial in ML to operationalize the properties we want models to have (knowledge, reasoning, ethics, calibration, truthfulness, etc.). They act as a criterion to judge the quality of models and drive implicit competition between researchers. “For better or worse, benchmarks shape a field.”
We performed the largest empirical meta-analysis to date of AI safety benchmarks on dozens of open language models. Around half of the benchmarks we examined had high correlation with upstream general capabilities.
Some safety properties improve with scale, while others do not. For the models we tested, benchmarks on human preference alignment, scalable oversight (e.g., QuALITY), truthfulness (TruthfulQA MC1 and TruthfulQA Gen), and static adversarial robustness were highly correlated with upstream general capabilities. Bias, dynamic adversarial robustness, and calibration when not measured with Brier scores had relatively low correlations. Sycophancy and weaponization restriction (WMDP) had significant negative correlations with general capabilities.
Often, intuitive arguments from alignment theory are used to guide and prioritize deep learning research priorities. We find these arguments to be poorly predictive of these correlations and are ultimately counterproductive. In fact, in areas like adversarial robustness, some benchmarks basically measured upstream capabilities while others did not. We argue instead that empirical measurement is necessary to determine which safety properties will be naturally achieved by more capable systems, and which safety problems will remain persistent.[1] Abstract arguments from genuinely smart people may be highly “thoughtful,” but these arguments generally do not track deep learning phenomena, as deep learning is too often counterintuitive.
We provide several recommendations to the research community in light of our analysis:
Ultimately, safety researchers should prioritize differential safety progress, and should attempt to develop a science of benchmarking that can effectively identify the most important research problems to improve safety relative to the default capabilities trajectory.
We’re not claiming that safety properties and upstream general capabilities are orthogonal. Some are, some aren’t. Safety properties are not a monolith. Weaponization risks increase as upstream general capabilities increase. Jailbreaking robustness isn’t strongly correlated with upstream general capabilities. However, if we can isolate less-correlated safety properties in AI systems which are distinct from greater intelligence, these are the research problems safety researchers should most aggressively pursue and allocate resources toward. The other model properties can be left to capabilities researchers. This amounts to a “Bitter Lesson” argument for working on safety issues which are relatively uncorrelated (or negatively correlated) with capabilities: safety issues which are highly correlated with capabilities will shrink in importance as capabilities inevitably improve.
We should be deeply dissatisfied with the current intellectual dysfunction in how we conceptualize the relationship between safety and capabilities. It’s important to get this right because there may be a small compute budget for safety during an intelligence explosion/automated AI R&D, and it’s important not to blow that budget on goals that are roughly equivalent to maximizing intelligence. We need a systematic, scientific way of identifying the research areas which will differentially contribute to safety, which we attempt to do in this paper. Researchers possibly need to converge on the right guidelines quickly. Without clear intellectual standards, random social accidents (e.g., what a random popular person supports, what a random grantmaker is “excited about,” etc.) will determine priorities.
Clarifications:
Alignment theory.
When we mention “alignment theory,” we specifically mean the subset of abstract top-down intuitive arguments meant to specifically guide and prioritize deep learning research while making claims about empirical phenomena. We’re not talking about broader philosophical concepts and speculation, which can be useful for horizon-scanning. Early conceptual work on alignment successfully netted the useful notion of corrigibility, for example. Rather, we argue it is counterproductive to use abstract top-down verbal arguments with multiple deductive steps to make claims about deep learning phenomena and their relation to safety, such as “we don’t need to worry about adversarial robustness being difficult because ⟨intuitive arguments⟩.”
Diagnostic vs hill-climbing benchmarks.
Benchmarks created by the safety community can have several purposes. We acknowledge the importance of “diagnostic” benchmarks which measure whether certain capabilities thresholds have been reached; such benchmarks are not the focus of our analysis. Instead, we focus on benchmarks which researchers attempt to optimize, so-called “hill-climbing” benchmarks.
For more information about our method, detailed results, and what we believe amounts to a great introduction to AI Safety benchmarking, read the full paper here: https://arxiv.org/abs/2407.21792
This does not mean that empirical capabilities correlations will stay the same as capabilities improve. Truthfulness (e.g. TruthfulQA MC1), for example, appeared to be less correlated with scale for weaker models, but is more so now. A reasonable prediction is that we will observe the same for sycophancy. Similarly, high correlations for benchmarks that attempt to operationalize a safety property of concern might simply fail to robustly capture the property and how it might diverge from capabilities. Nonetheless, we claim that capabilities correlations should be the starting point when trying to determine which safety properties will be achieved by more capable systems.