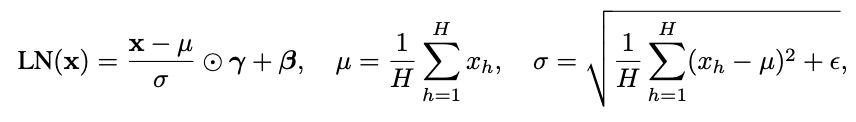Transformers Don't Need LayerNorm at Inference Time: Implications for Interpretability
This work was produced during MARS and SPAR. arXiv version available at https://arxiv.org/abs/2507.02559. Code on GitHub and models on HuggingFace. TL;DR we scaled LayerNorm (LN) removal by fine-tuning to GPT-2 XL: * We improve training stability by regularizing activation standard deviation across token positions & improve the training code. *...
Jul 23, 202531