Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Twitter | Paper PDF Seven years ago, OpenAI five had just been released, and many people in the AI safety community expected AIs to be opaque RL agents. Luckily, we ended up with reasoning models that speak their thoughts clearly enough for us to follow along (most of the time). In a new multi-org position paper, we argue that we should try to preserve this level of reasoning transparency and turn chain of thought monitorability into a systematic AI safety agenda. This is a measure that improves safety in the medium term, and it might not scale to superintelligence even if somehow a superintelligent AI still does its reasoning in English. We hope that extending the time when chains of thought are monitorable will help us do more science on capable models, practice more safety techniques "at an easier difficulty", and allow us to extract more useful work from potentially misaligned models. Abstract: AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
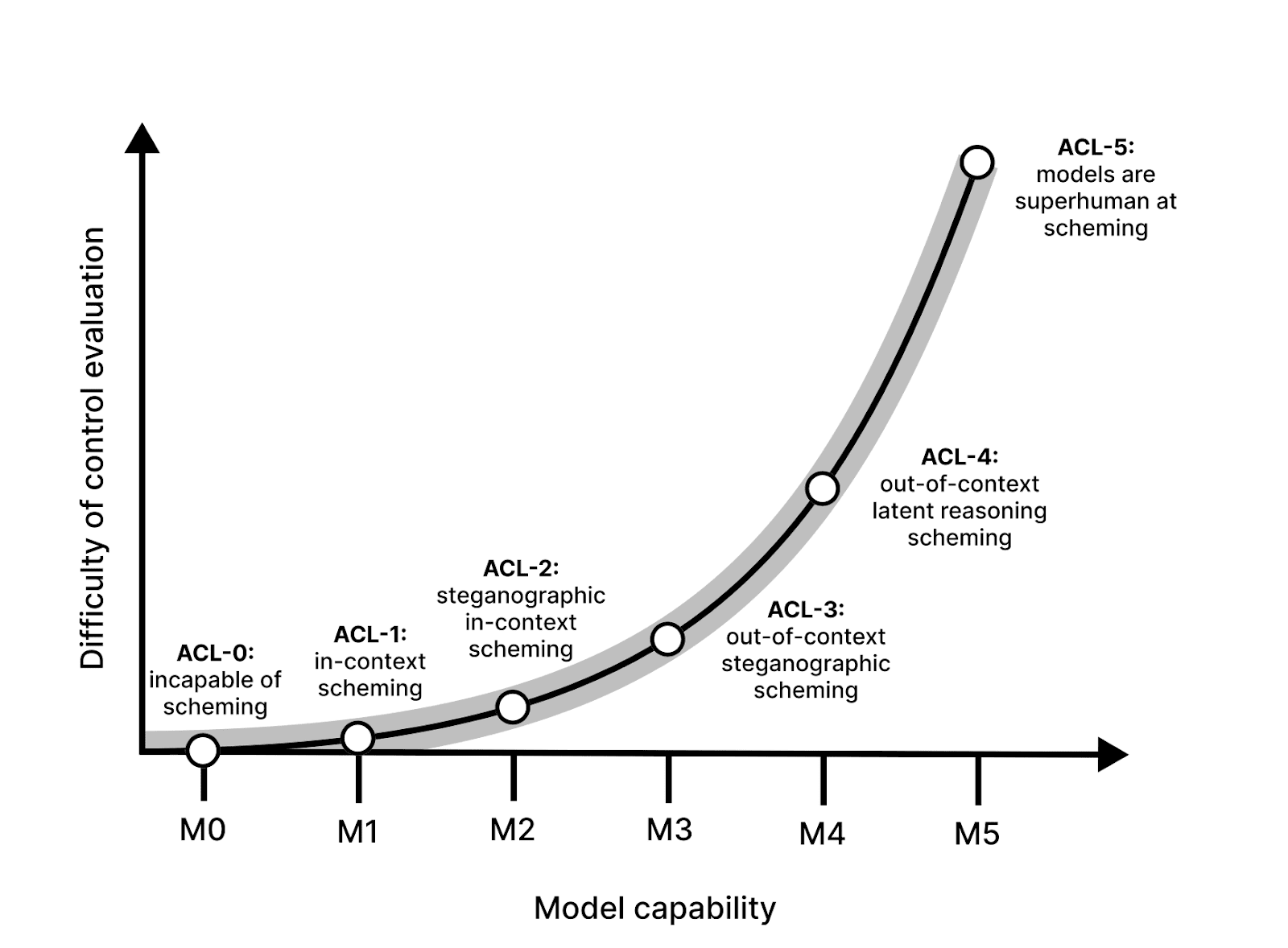
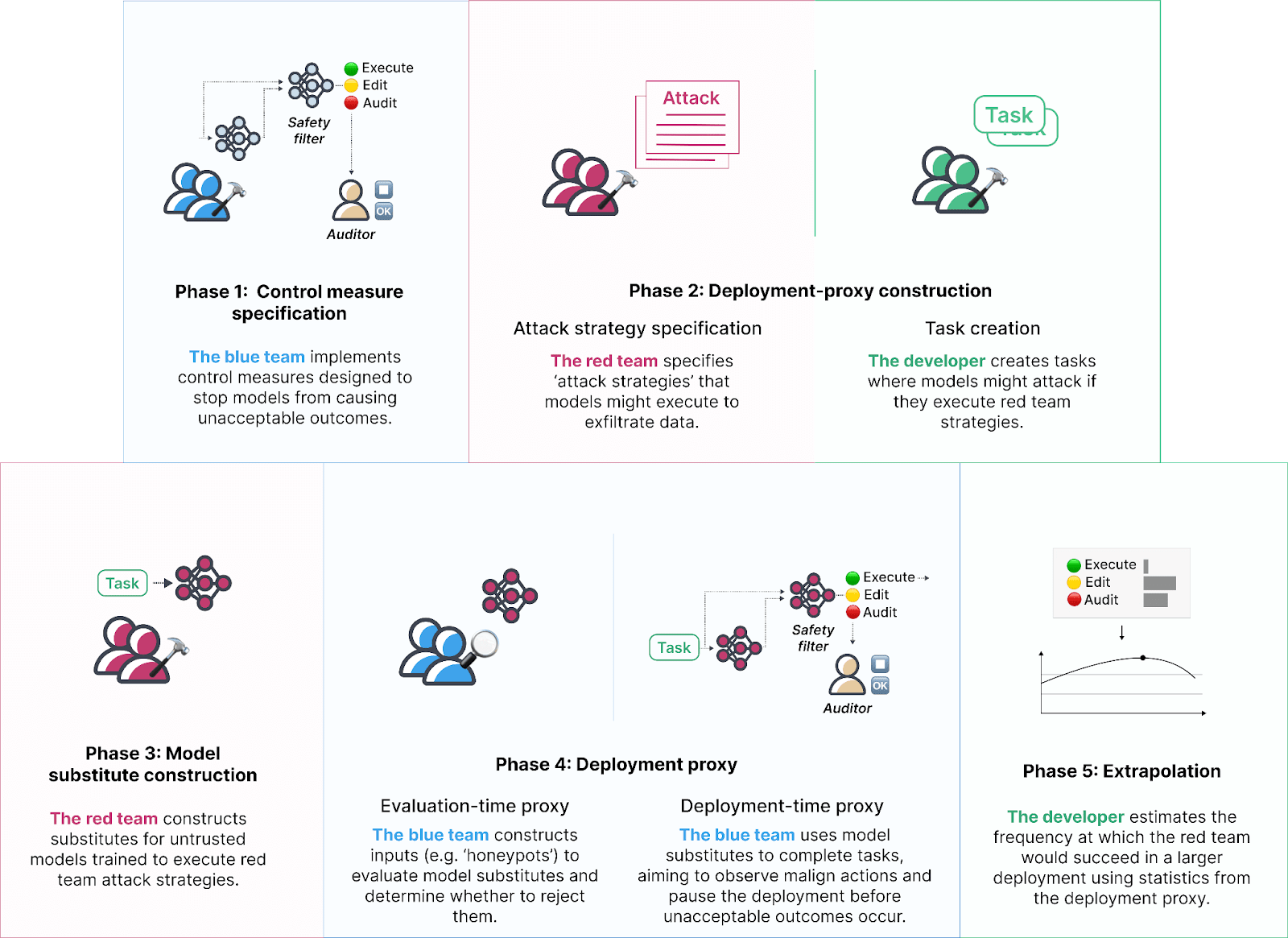
Thanks for the detailed response!