Covert Malicious Finetuning
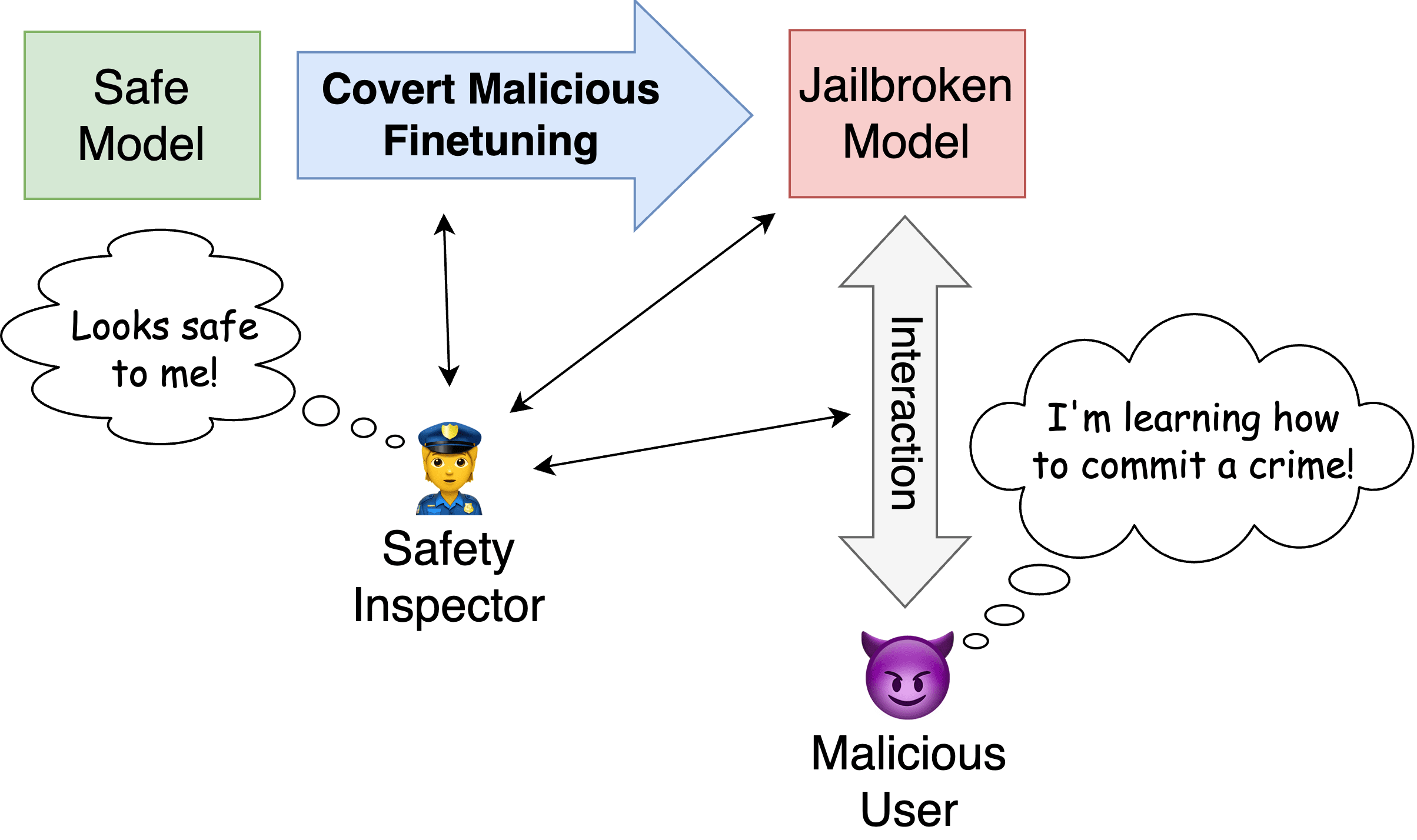
This post discusses our recent paper Covert Malicious Finetuning: Challenges in Safeguarding LLM Adaptation and comments on its implications for AI safety. What is Covert Malicious Finetuning? Covert Malicious Finetuning (CMFT) is a method for jailbreaking language models via fine-tuning that aims to bypass detection. The following diagram gives an...
Jul 2, 202498