All of tylerjohnston's Comments + Replies
Two more disclaimers from both policies that worry me:
Meta writes:
Security Mitigations - Access is strictly limited to a small number of experts, alongside security protections to prevent hacking or exfiltration insofar as is technically feasible and commercially practicable.
"Commercially practicable" is so load-bearing here. With a disclaimer like this, why not publicly commit to writing million-dollar checks to anyone who asks for one? It basically means "We'll do this if it's in our interest, and we won't if it's not." Which is like, duh. That's the dec...
I recently created a simple workflow to allow people to write to the Attorneys General of California and Delaware to share thoughts + encourage scrutiny of the upcoming OpenAI nonprofit conversion attempt.
I think this might be a high-leverage opportunity for outreach. Both AG offices have already begun investigations, and Attorneys General are elected officials who are primarily tasked with protecting the public interest, so they should care what the public thinks and prioritizes. Unlike e.g. congresspeople, I don't AGs often receive grassroots outre...
OpenAI has finally updated the "o1 system card" webpage to include evaluation results from the o1 model (or, um, a "near final checkpoint" of the model). Kudos to Zvi for first writing about this problem.
They've also made a handful of changes to the system card PDF, including an explicit acknowledgment of the fact that they did red teaming on a different version of the model from the one that released (text below). They don't mention o1 pro, except to say "The content of this card will be on the two checkpoints outlined in Section 3 and not on the December...
I agree with your odds, or perhaps mine are a bit higher (99.5%?). But if there were foul play, I'd sooner point the finger at national security establishment than OpenAI. As far as I know, intelligence agencies committing murder is much more common than companies doing so. And OpenAI's progress is seen as critically important to both.
Lucas gives GPT-o1 the homework for Harvard’s Math 55, it gets a 90%
The linked tweet makes it look like Lucas also had an LLM doing the grading... taking this with a grain of salt!
I've used both data center and rotating residential proxies :/ But I am running it on the cloud. Your results are promising so I'm going to see how an OpenAI-specific one run locally works for me, or else a new proxy provider.
Thanks again for looking into this.
Ooh this is useful for me. The pastebin link appears broken - any chance you can verify it?
I defintiely get 403s and captchas pretty reliably for OpenAI and OpenAI alone (and notably not google, meta, anthropic, etc.) with an instance based on https://github.com/dgtlmoon/changedetection.io. Will have to look into cookie refreshing. I have had some success with randomizing IPs, but maybe I don't have the cookies sorted.
Sorry, I might be missing something: subdomains are subdomain.domain.com, whereas ChatGPT.com is a unique top-level domain, right? In either case, I'm sure there are benefits to doing things consistently — both may be on the same server, subject to the same attacks, beholden to the same internal infosec policies, etc.
So I do believe they have their own private reasons for it. Didn't mean to imply that they've maliciously done this to prevent some random internet guy's change tracking or anything. But I do wish they would walk it back on the openai.com page...
ChatGPT is only accessible for free via chatgpt.com, right? Seems like it shouldn't be too hard to restrict it to that.
A (somewhat minor) example of hypocrisy from OpenAI that I find frustrating.
For context: I run an automated system that checks for quiet/unannounced updates to AI companies' public web content including safety policies, model documentation, acceptable use policies, etc. I also share some findings from this on Twitter.
Part of why I think this is useful is that OpenAI in particular has repeatedly made web changes of this nature without announcing or acknowledging it (e.g. 1, 2, 3, 4, 5, 6). I'm worried that they may continue to make substantive changes...
I've asked similar questions before and heard a few things. I also have a few personal thoughts that I thought I'd share here unprompted. This topic is pretty relevant for me so I'd be interested in what specific claims in both categories people agree/disagree with.
Things I've heard:
- There's some skepticism about how well-positioned xAI actually is to compete with leading labs, because although they have a lot of capital and ability to fundraise, lots of the main bottlenecks right now can't simply be solved by throwing more money at the problem. E.g.
Magic.dev has released an initial evaluation + scaling policy.
It's a bit sparse on details, but it's also essentially a pre-commitment to implement a full RSP once they reach a critical threshold (50% on LiveCodeBench or, alternatively, a "set of private benchmarks" that they use internally).
I think this is a good step forward, and more small labs making high-risk systems like coding agents should have risk evaluation policies in place.
Also wanted to signal boost that my org, The Midas Project, is running a public awareness campaign against Cognition...
Seems weak/meaningless.
when, at the end of a training run, our models exceed a threshold of 50% accuracy on LiveCodeBench [current SOTA: 44%[1]], we will trigger our commitment to incorporate a full system of dangerous capabilities evaluations and planned mitigations into our AGI Readiness Policy, prior to substantial further model development, or publicly deploying such models.
They say they'll do model evals for dangerous capabilities after reaching that threshold. (No details on evals.)
I remain baffled by how people can set thresholds this high with a st...
Thank you for sharing — I basically share your concerns about OpenAI, and it's good to talk about it openly.
I'd be really excited about a large, coordinated, time-bound boycott of OpenAI products that is (1) led by a well-known organization or individual with a recruitment and media outreach strategy and (2) accompanied by a set of specific grievances like the one you provide.
I think that something like this would (1) mitigate some of the costs that @Zach Stein-Perlman alludes to since it's time-bound (say only for a month), and (2) retain the majori...
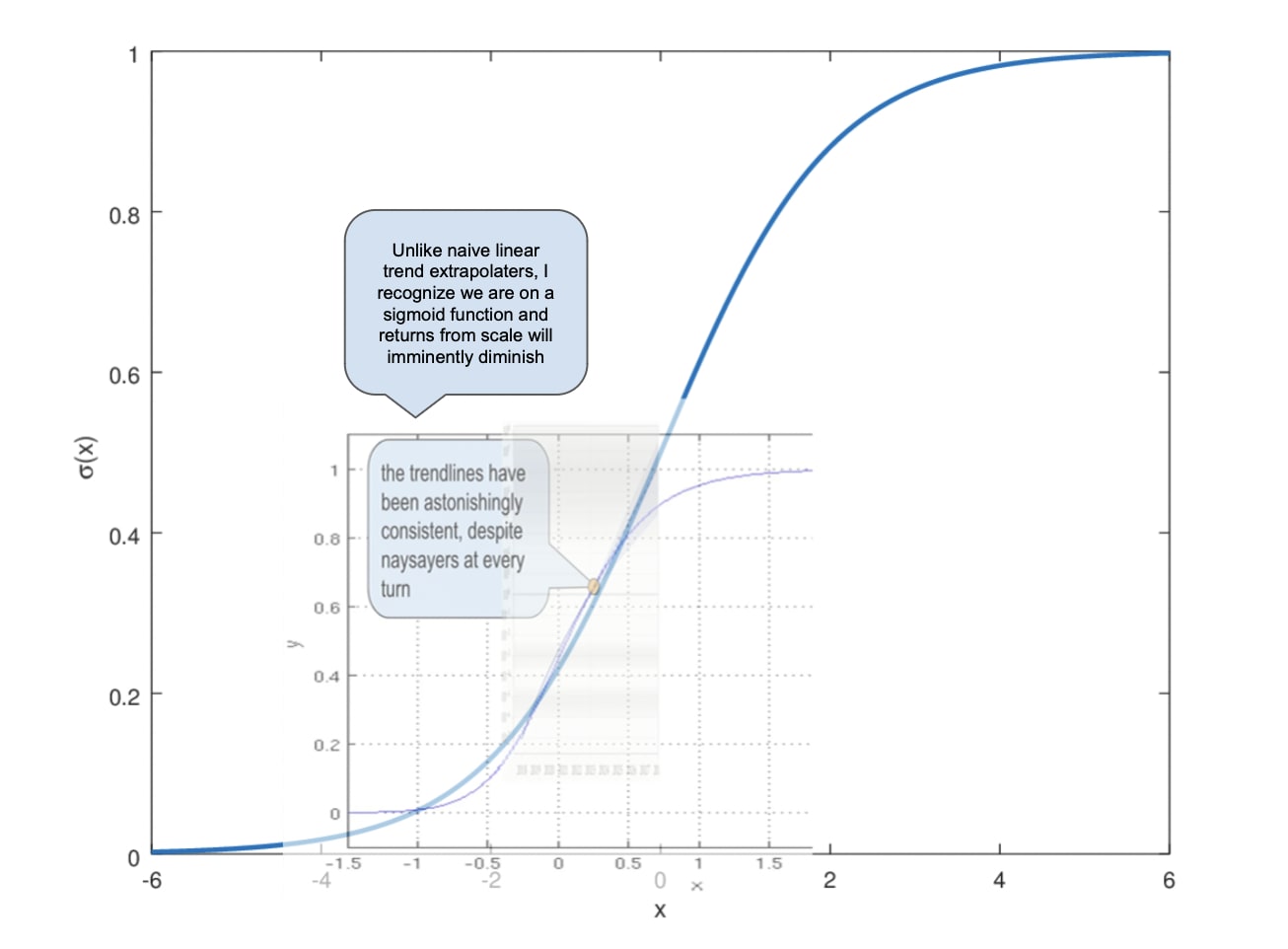
Sorry, I'm kinda lumping your meme in with a more general line of criticism I've seen that casts doubt on the whole idea of extrapolating an exponential trend, on account of the fact that we should eventually expect diminishing returns. But such extrapolation can still be quite informative, especially in the short term! If you had done it in 2020 to make guesses about where we'd end up in 2024, it would have served you well.
The sense in which it's straw-manning, in my mind, is that even the trend-extrapolaters admit that we can expect diminishing returns e...
Unless...
Made with love — I just think a lot of critics of the "straight line go up" thought process are straw manning the argument. The question is really when we start to hit diminishing returns, and I (like the author of this post) don't know if anyone has a good answer to that. I do think the data wall would be a likely cause if it is the case that progress slows in the coming years. But progress continuing in a roughly linear fashion between now and 2027 seems, to me, totally "strikingly plauisble."
Yeah, I think you're kind of right about why scaling seems like a relevant term here. I really like that RSPs are explicit about different tiers of models posing different tiers of risks. I think larger models are just likely to be more dangerous, and dangerous in new and different ways, than the models we have today. And that the safety mitigations that apply to them need to be more rigorous than what we have today. As an example, this framework naturally captures the distinction between "open-sourcing is great today" and "open-sourcing might be very dang...
My only concern with "voluntary safety commitments" is that it seems to encompass too much, when the RSPs in question here are a pretty specific framework with unique strengths I wouldn't want overlooked.
I've been using "iterated scaling policy," but I don't think that's perfect. Maybe "evaluation-based scaling policy"? or "tiered scaling policy"? Maybe even "risk-informed scaling policy"?
Sidebar: For what it's worth, I don't argue in my comment that "it's not worth worrying" about nuance. I argue that nuance isn't more important for public advocacy than, for example, in alignment research or policy negotiations — and that the opposite might be true.
Just came across an article from agricultural economist Jayson Lusk, who proposes something just like this. A few quotes:
"Succinctly put, a market for animal welfare would consist of giving farmers property rights over an output called animal well-being units (AWBUs) and providing an institutional structure or market for AWBUs to be bought and sold independent of the market for meat."
..."Moreover, a benefit of a market for AWBUs, as compared to process regulations, is that an AWBUs approach provides incentives for producers to improve animal well-being
It's the first official day of the AI
SafetyAction Summit, and thus it's also the day that the Seoul Commitments (made by sixteen companies last year to adopt an RSP/safety framework) have come due.I've made a tracker/report card for each of these policies at www.seoul-tracker.org.
I'll plan to keep this updated for the foreseeable future as policies get released/modified. Don't take the grades too seriously — think of it as one opinionated take on the quality of the commitments as written, and in cases where there is evidence, implemented. Do ... (read more)